Sometimes I think most people still don’t understand how important “data validation” is going to be in the world of autonomous AI.
If I had to say it from the bottom of my heart, it’s because the whole discussion is still stuck on quantity. Which model has more parameters, which one scraped more terabytes of text, which company hoarded the biggest server farm. But underneath, something much deeper is happening…. and that’s probably data purity. Who actually cleans and verifies the information before the machine learns it? And honestly, the more I look at the OpenLedger Datanet architecture, the more it seems like they’re not just creating another decentralized storage bucket. They’re actually trying to redefine the relationship between raw information and verified truth.
It sounds big. Maybe even extra big – I mean something absolutely massive. And it might take a few more cycles for people to understand whether this decentralized validation will actually work at scale under heavy scraping stress. Yet…. there’s something different here at the structural level. Because traditionally, AI models absorb vast oceans of internet garbage—but once the model starts hallucinating or making bad decisions, the underlying toxic data is completely hidden from the users who rely on it.
The model learns everything.
The system verifies nothing.
This imbalance has been there for many years.
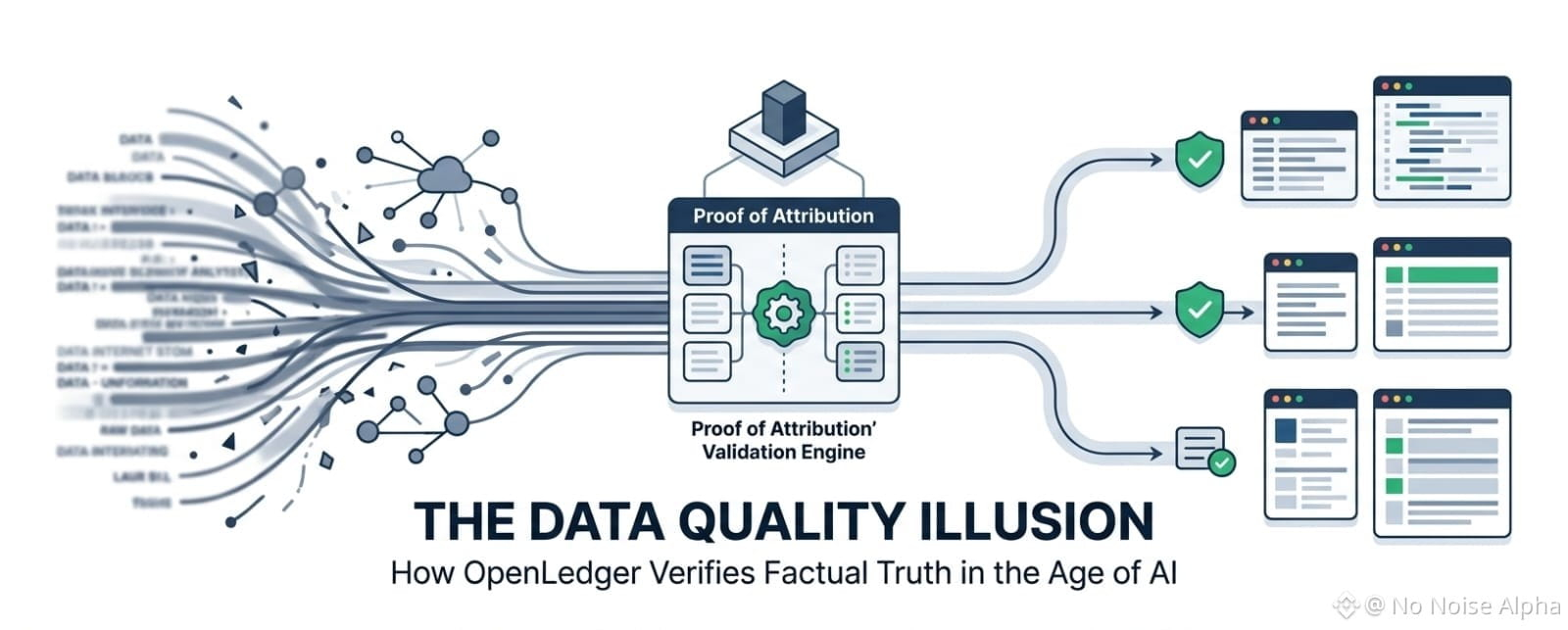
And to be honest, this is where OpenLedger's focus on verifiable data starts to sound interesting to me. Not for branding. Honestly, crypto projects launch new data marketplaces almost every week. But since the contribution framework moved into live execution, the discussion has shifted from scraping theory to economic reality. Now the Datanet layer is no longer just a conceptual drawing. Contributors can submit specific datasets, validators physically verify the quality, and smart contracts manage the attribution metrics on-chain. It changes the psychological structure of dataset creation.
Suddenly, data is no longer just raw fuel.
It becomes a verified, traceable asset.
And I think this distinction is more important than people think. Especially after looking closely at how the Proof of Attribution engine handles overlapping inputs. The architecture relies on feeding human-curated context directly into a distributed validation engine. If a specific dataset is poisoned with fake facts, or if a bot intentionally provides spam, the quality score drops instantly. By tracking these quality shifts at the granular level, the framework attempts to mathematically attribute which contributor actually provided the clean signal. Because mapping a clean AI answer back to an opaque web of scraped websites is an uncomfortable engineering hurdle.
Sources are collective.
Origins are blurred.
Almost untraceable.
So trying to isolate the exact origin of a single factual input within a massive training corpus… is actually a hugely ambitious infrastructure problem. And maybe imperfect. I don’t think data verification will ever be completely mathematically pure. Still, trying to at least create a transparent validation layer seems like a different shift from where the industry was going. Most platforms optimize simple data extraction. OpenLedger is at least trying to optimize data accountability. Or at least going in that direction.
And here's another thing I keep thinking about... the legal and commercial reality for the people actually building this stuff. When you look at a polished AI answering a complex medical or financial question, it looks incredibly smart. But in the practical world, enterprises and developers aren't looking at the smooth interface. They are asking hard questions:
Is this dataset legally clean ?
Are the sources verified ?
How does the model handle poisoned inputs ?
Will the origins hold up in court ?
And this could change the entire dynamics of the commercial machine ecosystem. Looking at OpenLedger's approach to domain-specific datasets, they seem aware of this reality. They aren't trying to build a generic scraper that steals everything. They are focusing on specialized, high-fidelity data environments. Honestly, it seems refreshing in a market where many projects are still trying to be "data layers for everything". But at the same time..... I don't think the journey will be easy from here. Because where real economic rewards meet data submission, unpredictable behavior will come.
Synthetic data loops.
Quality manipulation.
Spam farming.
Validation disputes.
These pressures are unavoidable. So the real test probably starts now as more builders plug their custom datasets into the stack. Will the validation process remain strong even when scaling across thousands of parallel submissions? Will the quality score be trusted across millions of autonomous interactions? Will the long-term incentives keep validators honest?
Honestly.......
I don't know for sure. But maybe this uncertainty is what makes this phase important. Because after a long time, a project is emerging that isn't just talking about abstract compute power or speculative narratives. They're trying to answer a much more uncomfortable question:
“If AI systems become the foundation of our knowledge.… will the infrastructure actually know what is true and what is fake ?”
And honestly, I think the industry will have to face this question sooner or later. OpenLedger may not have all the answers yet. Still, it seems like this is one of the very few architectures that is not avoiding the messy reality of data quality, but rather trying to build a permanent foundation around it anyway.
If you are currently fine-tuning or experimenting with custom datasets, how are you handling origin validation at scale right now?
@OpenLedger #openledger #OpenLedger $OPEN
