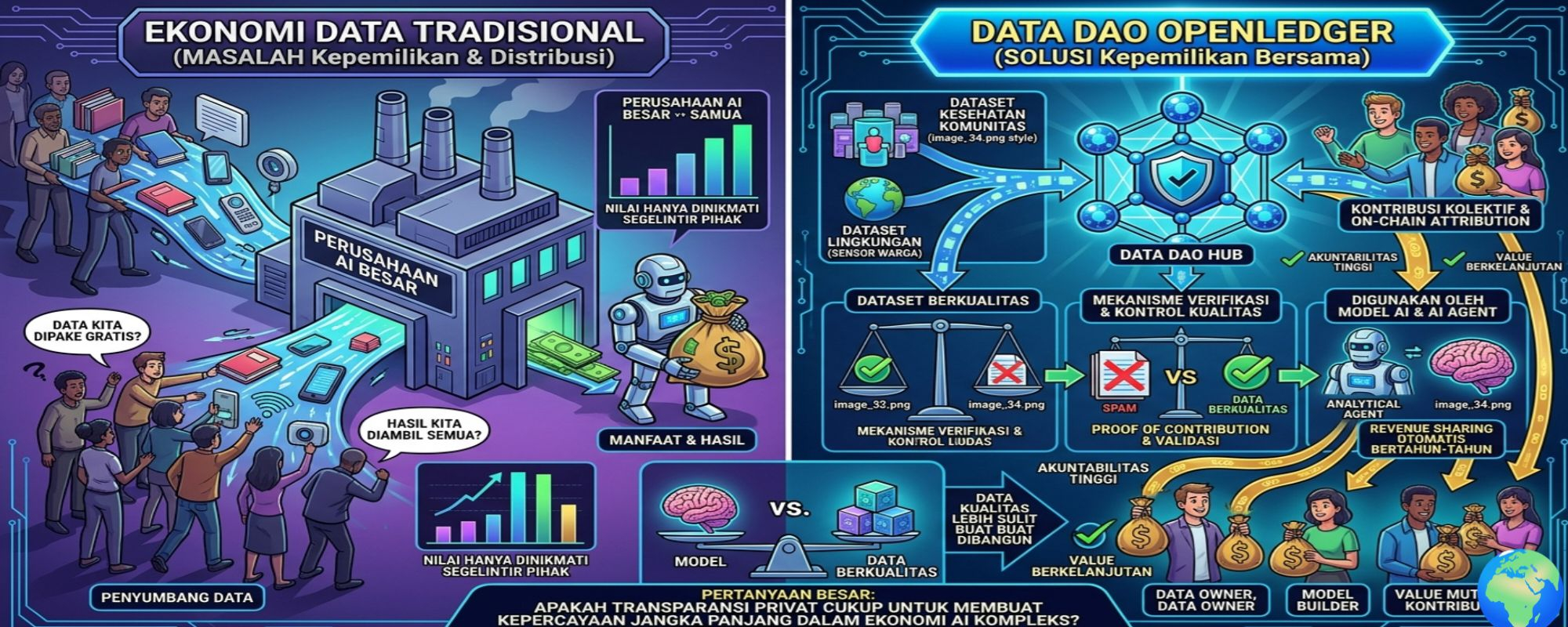
Gua selalu ngerasa ada sesuatu yang aneh di ekonomi data hari ini.
Semakin sering gua baca soal AI, semakin sering juga gua kepikiran satu hal. Model-model AI ini butuh data dalam jumlah besar buat jadi pintar. Tapi hampir engga pernah ada pembahasan soal siapa yang sebenernya menyumbang data tersebut dan siapa yang menikmati hasil akhirnya.
Biasanya cuma perusahaan atau platform yang pegang kendali.
Makanya konsep Data DAO di OpenLedger menurut gua menarik. Bukan karna terdengar keren atau "web3 banget", tapi karna dia mencoba menjawab pertanyaan yang selama ini jarang dibahas dengan serius: kalo nilai sebuah dataset berasal dari ribuan orang, kenapa kepemilikannya cuma jatuh ke satu pihak?
Bayangin ada dataset lingkungan yang dikumpulkan dari sensor milik ribuan warga. Atau dataset kesehatan yang berasal dari kontribusi komunitas besar. Secara logika, nilai dataset itu lahir dari kerja kolektif. Tapi dalam model tradisional, hak ekonominya sering berakhir di satu organisasi aja.
Data DAO mencoba membalik logika itu.
Jujur aja, konsep kepemilikan data bersama bukan ide yang bener-bener baru. Industri crypto udah membicarakan hal serupa selama bertahun-tahun. Yang bikin gua penasaran adalah apakah OpenLedger bisa menerjemahkan ide tersebut menjadi sistem yang bener-bener menghasilkan nilai bagi kontributor data, bukan sekedar narasi yang terdengar menarik.
Di atas kertas, terdengar jauh lebih adil.
Tapi ada pertanyaan yang menurut gua lebih menarik.
Gimana caranya menjaga kualitas ketika ribuan orang ikut berkontribusi? Siapa yang menentukan data mana yang valid dan mana yang cuma spam?
Kalo satu orang mengunggah data berkualitas tinggi sementara seratus orang lain mengirim data yang buruk, apakah sistem bisa membedakan keduanya? Pertanyaan seperti ini mungkin terdengar teknis, tapi justru akan menentukan apakah sebuah Data DAO bener-bener bernilai atau engga.
Di sisi lain, justru tantangan itu yang bikin model ini menarik buat diamati.
Kalo berhasil, Data DAO bisa menciptakan insentif yang selama ini hilang. Orang punya alasan buat terus memperbarui data, menjaga kualitas, dan mengajak kontributor baru masuk ke ekosistem. Semakin bagus dataset yang dimiliki komunitas, semakin besar peluang digunakan oleh model dan AI agent yang membutuhkan data berkualitas tinggi.
Menurut gua, hal yang paling menarik dari OpenLedger bukan cuma soal kepemilikan data bersama. Yang bikin beda adalah upaya mereka menghubungkan data, AI, dan insentif ekonomi dalam satu alur yang saling nyambung. Jika AI terus berkembang menggunakan kontribusi jutaan orang, maka muncul pertanyaan yang semakin sulit diabaikan: haruskah nilai ekonominya cuma dinikmati oleh pemilik model, atau juga oleh pihak yang menyediakan data yang membuat model tersebut menjadi pintar?
Karna di era AI, gua mulai berpikir bahwa model mungkin bukan aset yang paling berharga. Model bisa berubah, bisa diganti, bahkan bisa ditiru. Tapi data berkualitas jauh lebih sulit buat dibangun.
Mungkin itu sebabnya pertanyaan terbesar ke depan bukan lagi siapa yang punya AI paling pintar.
Karna kalo data adalah bahan bakar AI, maka pertanyaan soal siapa yang memiliki data mungkin akan menjadi sama pentingnya dengan pertanyaan soal siapa yang memiliki modelnya.