
Most crypto investors are asking the wrong question about @OpenLedger
The common debate revolves around whether decentralized AI can compete with centralized AI. After spending several days studying #OpenLedger architecture, I no longer think that's the most important issue. The more interesting question is whether $OPEN can solve a problem that exists long before AI enters the discussion: how contributors get compensated for creating value inside digital networks.
When I first approached OpenLedger, I assumed I was looking at another AI focused protocol attempting to capitalize on market enthusiasm around machine learning infrastructure. The project resembled a traditional AI network. Instead of focusing exclusively on model performance, compute markets, or inference demand, OpenLedger appears to be building around a different economic primitive altogether: attribution.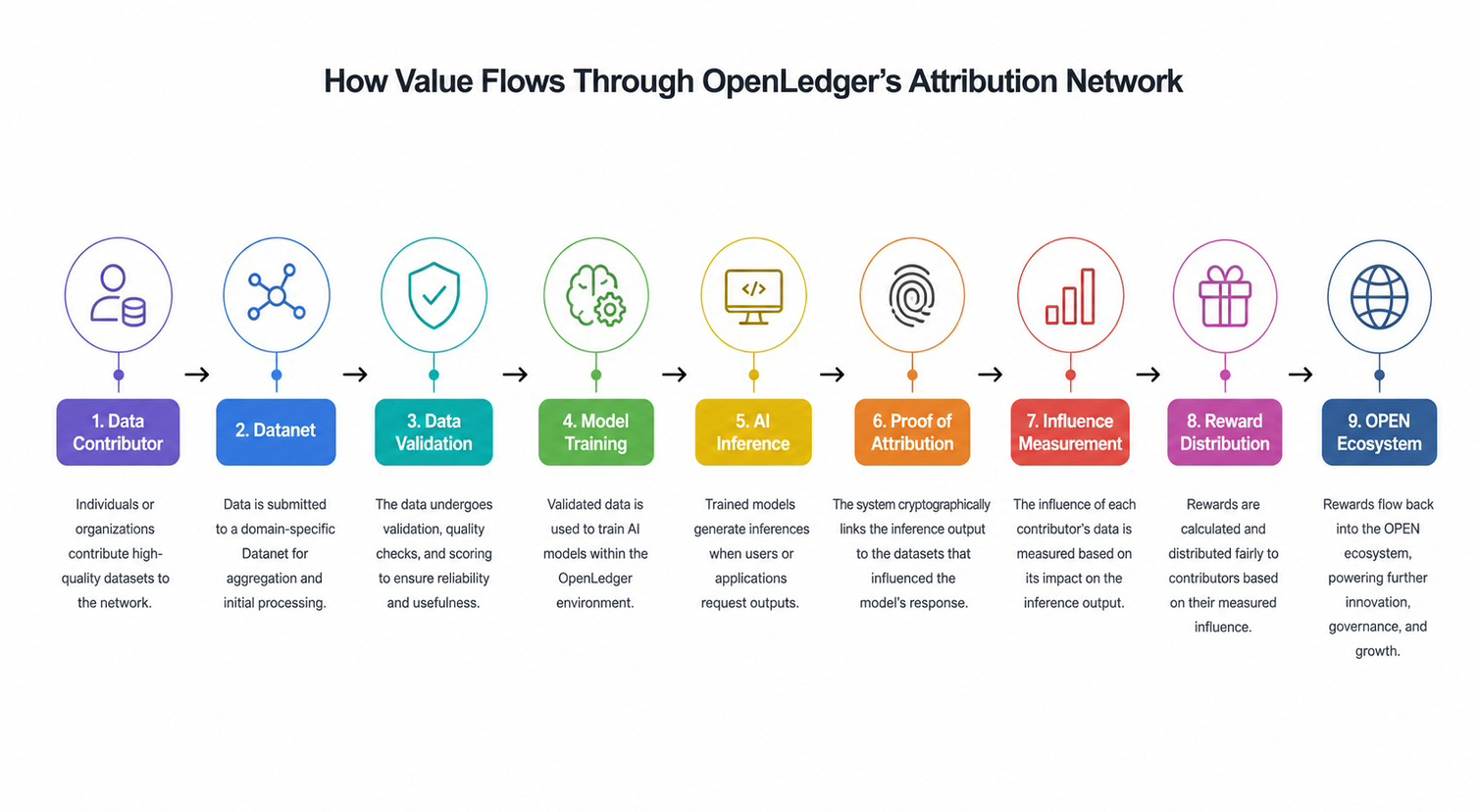
This distinction matters because attribution has historically been one of the biggest unresolved problems in both crypto and artificial intelligence. Networks can measure transactions. They can measure liquidity. They can even measure computational output. What they struggle to measure is contribution. Once data enters a model, determining which participants created value becomes increasingly difficult. OpenLedger's Proof of Attribution framework is effectively an attempt to solve that problem by establishing a verifiable connection between datasets, model training, and downstream outputs.
What caught my attention was not the concept itself but the implications if the mechanism actually works.
Most data today behaves like a consumable resource. It gets collected, sold, processed, and often loses visibility once incorporated into larger systems. OpenLedger is attempting to transform data into a productive asset. Through Datanets, contributors can submit domain specific datasets that become part of an ongoing economic cycle rather than a one time transaction. The objective is not simply storing information but continuously tracking how that information contributes to future outputs. In theory, value generation becomes traceable instead of disappearing into a black box.
That idea sounds elegant on paper, but I wanted to understand whether the surrounding infrastructure supported the vision.
This is where the architecture became far more interesting.
I initially assumed OpenLedger's cross chain integrations and ERC 4626 vault compatibility were secondary features added for ecosystem expansion. After examining the stack more closely, I started viewing them differently. Attribution systems become significantly less valuable if data, capital, and applications remain fragmented across isolated environments. OpenLedger's infrastructure appears designed to reduce that fragmentation. Cross chain messaging allows information and state to move between networks, while ERC 4626 standards create a more unified framework for integrating yield-bearing assets and liquidity layers.
Most protocols use interoperability to move assets.
OpenLedger appears to be using interoperability to coordinate economic activity.
That may sound like a small distinction, but I believe it changes the entire investment thesis. Asset mobility solves a transportation problem. Coordination solves an efficiency problem. The latter is considerably harder.
Another observation emerged when I investigated OpenLoRA and the protocol's development framework. Many AI projects focus on scaling compute resources. OpenLedger appears equally focused on scaling participation. OpenLoRA enables large numbers of specialized models to operate through shared infrastructure rather than requiring isolated deployments for every use case. From a systems perspective, this reduces duplication and improves resource utilization. More importantly, it lowers barriers for developers entering the ecosystem. The result is an architecture designed not only to support AI applications but also to accelerate their creation.
Of course, none of this guarantees success.
In fact, the strongest argument against OpenLedger may be that its ambitions are unusually broad. Attribution systems must remain accurate as models become increasingly complex. Cross chain infrastructure introduces additional operational and security risks. Incentive structures that appear sustainable during growth periods can become stressed during market contractions. There is also a practical adoption challenge. Contributors, developers, and users must all perceive enough value to participate in the same economic network. If one group disengages, the feedback loop weakens.
These risks are not theoretical. They represent the primary reason I remain cautious despite finding the architecture intellectually compelling.
Yet the more I analyzed the protocol, the more I became convinced that most market participants are evaluating OpenLedger through the wrong lens. Investors frequently compare it with other AI projects, but I increasingly view it as an infrastructure network attempting to formalize ownership and contribution within digital economies. AI simply happens to be the environment where that problem is most visible today.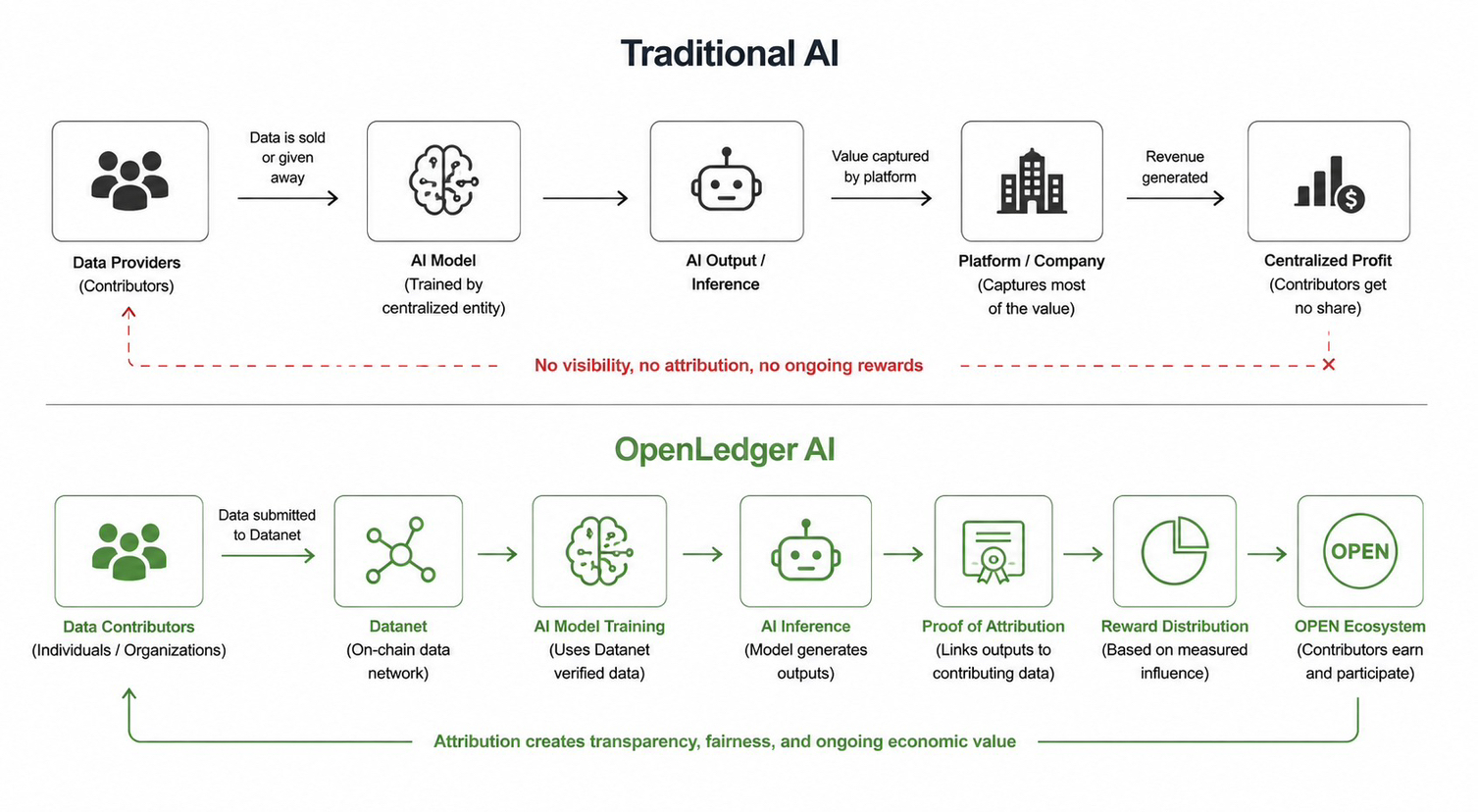
If that interpretation is correct, then the metrics worth tracking are not necessarily token related. I am far more interested in Datanet participation, attribution activity, model deployment growth, developer retention, and the volume of economic interactions occurring between contributors and applications. Those indicators will reveal whether OpenLedger's coordination model is creating genuine network effects or merely generating temporary activity through incentives.
After completing my research, I am left with neither conviction nor dismissal. What I found was not an AI protocol chasing a trend, but an infrastructure experiment attempting to answer a difficult question: who should own the value created by intelligence?
That question remains unresolved.
Whether OpenLedger can answer it is still uncertain.
But after examining the architecture, I believe it is the right question to be asking.