
I have been following developments in artificial intelligence for some time now and @OpenLedger caught my attention because it tackles real issues that many people in the field talk about quietly. The heading says it well OpenLedger is where AI development finally becomes transparent accountable and sustainable. I want to share what I have learned about this project in a straightforward way so others can understand the thinking behind it.
AI has grown fast in recent years yet most systems stay hidden inside big companies. You feed data into a model but you never really see how it learns or who gets credit for the work. That lack of visibility creates problems around trust fairness and long term growth. @OpenLedger tries to change that picture by building a blockchain designed specifically for AI work. It records data contributions model training and usage on a public ledger so everything stays verifiable.
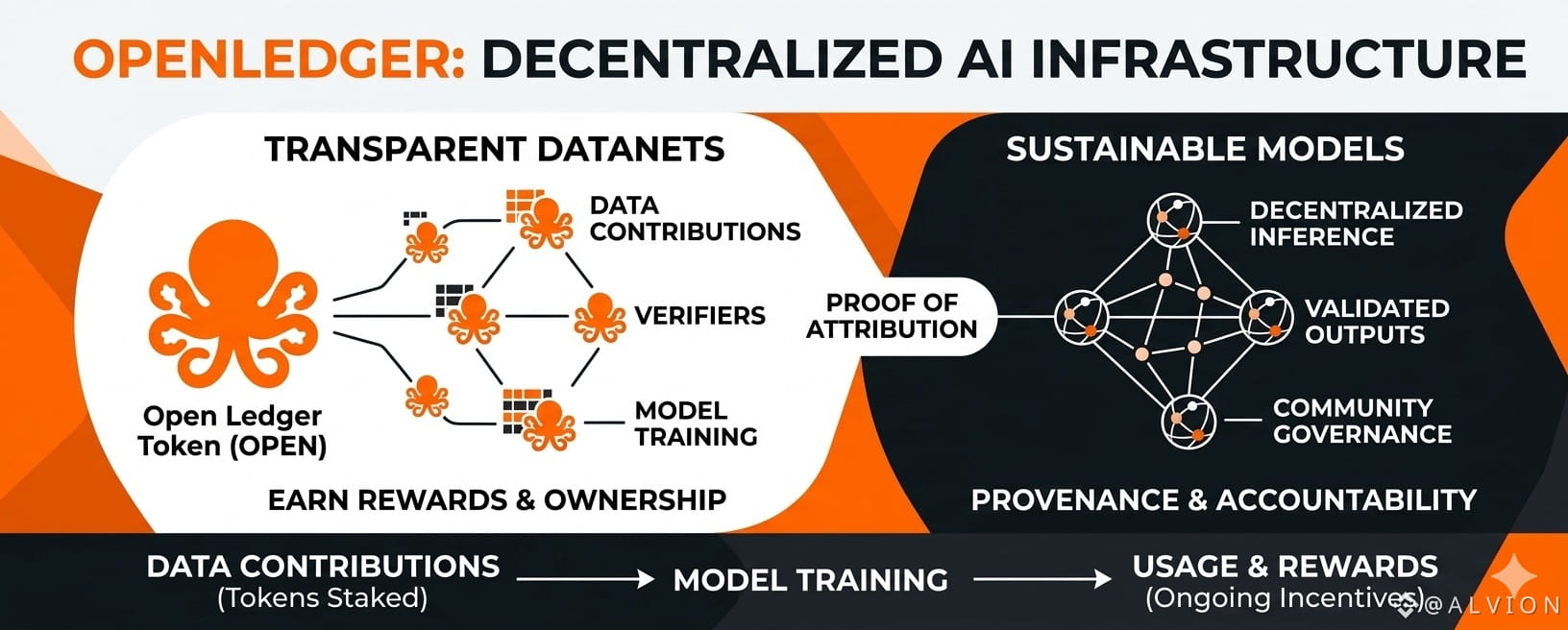
I first came across the idea when reading about how data powers modern AI. Without good data models cannot improve yet most data creators receive nothing in return. @OpenLedger introduces something called Datanets. These are community owned collections of data that people can build together. Anyone can add information to a Datanet and the system tracks exactly who contributed what. When the data helps train a model the contributors earn rewards through on chain mechanisms. This setup feels different from the usual approach where data disappears into private servers.
The core technology revolves around Proof of Attribution. I like how this works because it links every piece of output back to the original inputs. If a model gives an answer the ledger shows which datasets shaped it which people helped refine it and how the value flowed. No more guessing about origins. Everything leaves a clear trail. This traceability matters especially when AI starts making decisions that affect real lives in areas like healthcare finance or legal advice.
Let me explain the flow step by step as I understand it. First someone creates or joins a Datanet focused on a specific topic. Maybe it is medical records for research or code examples for programming tools or customer service conversations for better chat systems. Contributors upload verified data and stake tokens to show they stand behind its quality. Validators check the submissions to keep bad information out. Once the Datanet grows developers use it to train specialized models right on the chain. These are often smaller more focused models rather than massive general ones. The training process itself gets logged so anyone can audit the changes.
After training the model goes live for inference. Every time someone uses it for a task the system records the interaction. It calculates how much each original contributor added to that particular output and distributes rewards accordingly. This creates ongoing incentives. People keep improving datasets because they see real returns when their work gets used. I think this economic layer is one of the strongest parts because it turns participation into something sustainable instead of one time donations.
Transparency comes through at every stage. The blockchain records dataset uploads model versions fine tuning steps and even governance votes. If a company or researcher wants to check how a model reached its conclusions they can follow the full history. No black box. This matters for accountability. When something goes wrong regulators or users can point to specific data points or training decisions instead of waving hands at mysterious algorithms.
Sustainability shows up in several ways. First it spreads the benefits beyond a few big tech labs. Individual experts small teams and even hobbyists can contribute domain knowledge and earn from it. A doctor might add anonymized case studies. A farmer could share crop data. A teacher might upload lesson examples. All of that builds specialized models that serve narrower needs better than one giant model tries to do everything. Second the on chain incentives encourage quality over quantity. Low value data gets filtered or penalized through staking mechanisms. Third the project aims for efficient compute use by focusing on smaller models that run on decentralized networks rather than depending on huge centralized clusters.
I have read about the roadmap they laid out for 2026. It includes deeper integration for autonomous agents that can act on the chain with clear ownership and audit trails. These agents could handle tasks like research or trading while every decision stays traceable back to the models and data that guide them. There is also work on making inference cheaper and faster so more people can actually use these tools without massive costs. The overall goal seems to be turning AI into an ownable asset class where value flows back to creators in a fair measurable way.
One practical example that makes sense to me involves code generation. Developers often complain that large language models hallucinate or give insecure suggestions. With @OpenLedger a community could build a Datanet of verified Solidity code smart contract patterns and security audits. Models trained on that would carry provenance showing exactly which audited examples influenced each output. Users could trust the suggestions more because they see the source data and the experts behind it. Rewards would flow to the auditors and contributors every time the model helps someone ship safer code.
Another area is customer support. Companies spend huge amounts training agents yet the knowledge often sits inside private wikis. @OpenLedger lets support teams contribute conversation logs and resolution paths into a Datanet. The resulting model improves over time and the original contributors get compensated when their insights help resolve tickets. This creates a positive loop where better documentation leads to better AI which leads to more usage and more rewards.
I appreciate how the project handles identity and ownership. Contributors can choose levels of anonymity while still proving they added value. The ledger handles attribution without forcing everyone to reveal personal details. This balance feels important for privacy conscious participants. At the same time enterprises can verify the quality of data through on chain reputation scores and audit histories.
Governance also runs on the chain. Token holders or active contributors can vote on upgrades to the protocol or which Datanets get priority support. This distributed decision making aims to prevent any single group from controlling the direction. Of course governance always carries risks but having it transparent at least lets everyone see the proposals and votes in real time.
From what I have gathered the token called $OPEN plays a role in staking for validation paying for compute resources and receiving rewards from model usage. It is not just a speculative asset but the fuel that keeps the attribution and incentive engines running. The design tries to align long term holding with actual network growth because more valuable data and models increase overall usage and token utility.
Environmental considerations matter too. Many blockchains have faced criticism for energy use but OpenLedger builds on Ethereum standards and focuses on Layer 2 efficiency for AI specific operations. By keeping heavy compute modular and rewarding efficient contributions the hope is to avoid the massive carbon footprint of purely centralized AI training farms. I have not seen detailed audits yet but the intention toward sustainability shows in the architecture choices.
Let me dive deeper into how data quality gets maintained. When someone adds information to a Datanet they stake tokens as a signal of confidence. Validators review the submission using both automated checks and human expertise recorded on chain. If the data proves useful over time the original staker earns more. If it turns out misleading or low quality the stake can get slashed. This economic skin in the game encourages careful contributions rather than spam. Over time the system should develop a reputation layer where trusted contributors gain more influence and higher rewards.
Model training on OpenLedger uses techniques like OpenLoRA which allow efficient fine tuning without retraining everything from scratch. This saves compute resources and makes it possible for smaller players to participate. A developer can take a base model improve it with a specific Datanet and publish the new version with clear attribution to both the base and the new data. Users then choose models based on transparency scores and performance metrics all visible on the ledger.
Inference works in a decentralized manner too. Instead of one company running all the servers the network distributes requests across nodes that provide compute. Payments for usage flow automatically according to the attribution rules. This setup reduces single points of failure and censorship risks. If one node goes down others can pick up the load while the ledger keeps the records straight.
I have thought about potential challenges. Scaling AI workloads on chain is not easy because computations can get expensive and slow. The team seems aware of this and focuses on hybrid approaches where heavy lifting happens off chain but results and metadata stay on chain for verification. Another issue is data privacy. Not every dataset can be fully public especially in healthcare or personal finance. OpenLedger supports private Datanets with zero knowledge proofs or encrypted contributions so sensitive information stays protected while still contributing to model improvement.
Adoption will depend on useful applications. Early use cases around code generation domain specific chatbots and research tools look promising because they solve immediate pain points. As more Datanets mature we might see models for agriculture education or local languages that big tech often overlooks. Those specialized tools could bring AI benefits to more communities while rewarding the people who know those domains best.
The project has partnerships and grant programs including one with Cambridge that lets students and researchers experiment with transparent AI systems. This academic involvement could speed up innovation and provide independent validation of the technology. When universities get involved it often leads to better security audits and more thoughtful design choices.
Looking further ahead the vision includes a full agent economy. Autonomous agents that own their own models data and earnings. These agents could negotiate tasks collaborate with each other and evolve while everything stays auditable. A researcher agent might scour public Datanets for new papers train small improvements and publish results with full credit chains. This feels like science fiction today but the infrastructure pieces are being put in place.
I keep coming back to the human element. AI development has been extractive for too long with millions of people providing data through their online activity yet seeing none of the upside. OpenLedger flips that by making contribution visible and payable. It does not solve every problem in AI but it creates a framework where fairness and transparency become default rather than afterthoughts. That shift could encourage more diverse participation and lead to models that better reflect real world needs instead of just corporate priorities.
Technical users can already explore the tools for building Datanets and models. The documentation explains how to upload data set up training jobs and publish results. For non technical people the value comes from knowing their expertise can finally be tokenized and shared without losing control. A mechanic could contribute repair manuals. A chef could add recipe variations. Each contribution becomes part of a living knowledge base that rewards the source.
Security remains a top priority in any blockchain AI project. OpenLedger uses standard Ethereum security practices plus AI specific checks for model poisoning or data tampering. Validators run reputation systems and the community can propose upgrades through governance. Like any new system it will face tests but the open nature means problems get discovered and fixed in public rather than behind closed doors.
I have tried to cover the main aspects without hype because the real story lies in the mechanics. OpenLedger represents an attempt to build AI infrastructure that matches the decentralized spirit of the internet rather than concentrating power further. Whether it succeeds depends on execution community growth and actual usefulness of the models it enables. From what I see the foundations look solid and the problems it targets are genuine ones that need solving.
The journey toward transparent accountable and sustainable AI is just beginning. Projects like this one show a path forward where technology serves creators and users more evenly. I will keep watching how the ecosystem develops because the implications stretch across many industries and communities. If more people understand these ideas we can have better conversations about the future we actually want from artificial intelligence.!!!
