
I was enjoying my coffee and exploring OpenLedger’s Proof of Attribution mechanism,A thought click my mind that for years, AI has operated like a machine that eats the internet and speaks back with confidence, while nobody can clearly prove whose data shaped the answer. The people supplying the raw material rarely know where their contribution ended up, and they almost never get paid for it. PoA is trying to change that foundation.
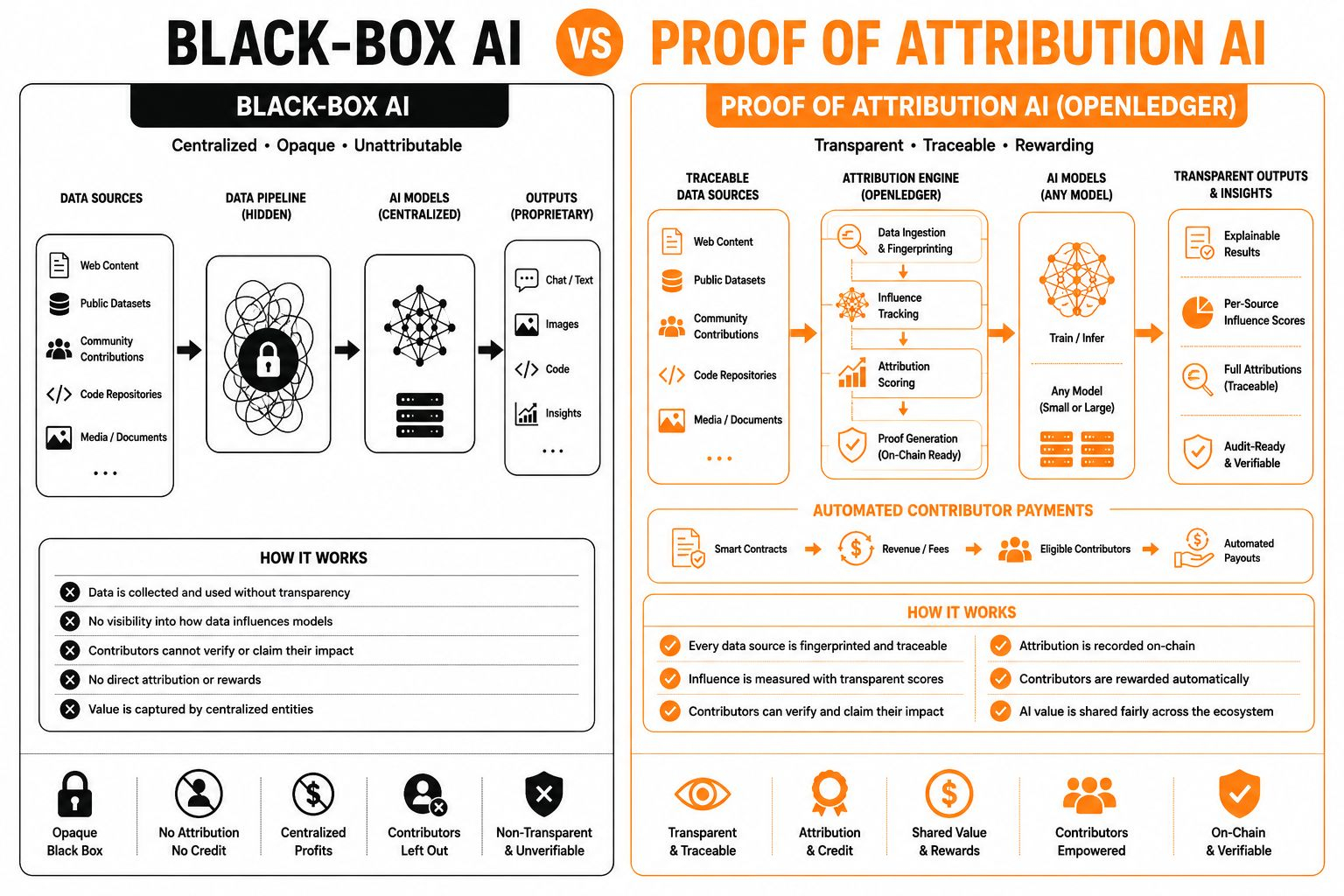
At the surface level, @OpenLedger system does something deceptively simple. It traces which pieces of training data influenced a model’s output. But underneath that is a much harder mathematical problem. Modern language models are trained on billions of tokens. Once gradients move through millions or sometimes trillions of parameters, attribution becomes blurry. Centralized AI labs usually treat this as acceptable collateral damage. The model works, revenue grows, and the training process remains largely opaque. OpenLedger is taking the opposite direction by treating attribution itself as infrastructure.
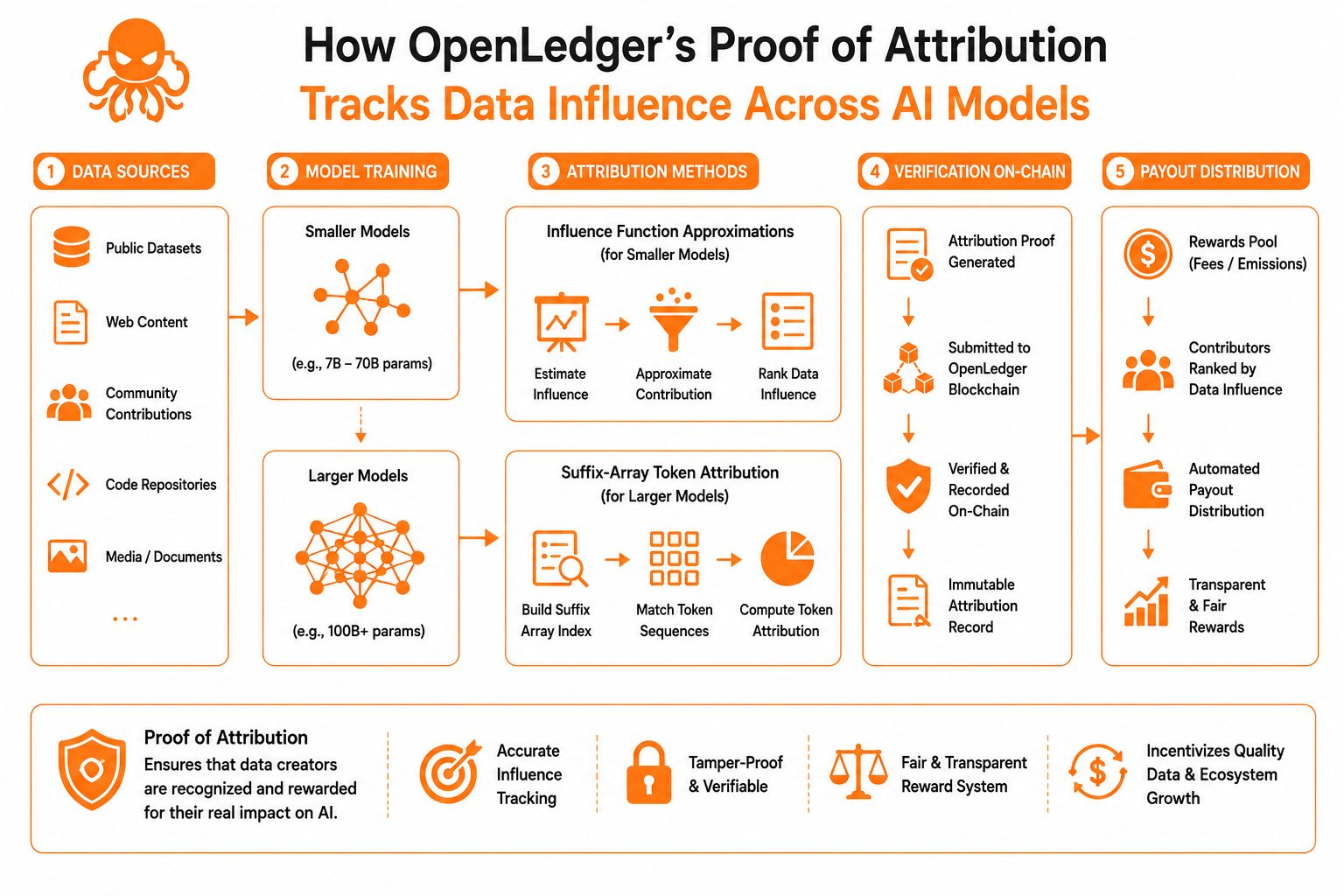
For smaller models, OpenLedger leans on influence function approximations. That sounds abstract until you translate it. Imagine removing one training example from a dataset and asking how much the model’s prediction changes afterward. Retraining the whole model every time would be impossible. A 7B parameter model can cost thousands of GPU hours to retrain even once. Influence functions estimate that effect mathematically instead. They use second-order optimization approximations, specifically the inverse Hessian matrix, to calculate how sensitive a prediction is to a specific training point.
What matters is not the formula itself but what it reveals. If a legal document dataset heavily influences a contract-generation output, the system can identify that relationship with measurable probability scores instead of vague assumptions. Early papers in this field showed attribution correlations exceeding 80% on benchmark datasets, which is significant because it turns training influence into something auditable rather than mythical.
Meanwhile, larger models create another problem entirely. Influence functions become computationally expensive at scale because the parameter space explodes. OpenLedger’s suffix-array token attribution method is a different kind of shortcut. Instead of estimating influence through gradients, it indexes token sequences directly. A suffix array is essentially a searchable map of every token continuation inside the training corpus. When the model generates an output, the system traces overlapping token paths backward to identify likely source contributions.
That sounds almost too mechanical for modern AI, but that simplicity is the point. It trades theoretical elegance for scalable traceability. If a generated paragraph about Ethereum governance closely mirrors thousands of training sequences from a specific research archive, the attribution engine can quantify those overlaps quickly. OpenLedger claims the method works efficiently even across datasets containing billions of tokens because suffix arrays reduce lookup complexity dramatically compared to brute-force matching.
Understanding that helps explain why OpenLedger keeps framing AI as both “explainable” and “payable.” Explainability here is not just about interpreting why a model answered a question. It is about proving where the answer came from. And once provenance becomes measurable, payment systems become programmable. A contributor whose dataset consistently influences outputs can theoretically receive on-chain rewards proportional to verified usage.
The blockchain layer matters because attribution without verification just recreates another trust bottleneck. OpenLedger anchors contribution records on-chain so attribution claims become tamper-resistant. Smart contracts can automate distribution flows. If a medical dataset contributes 2.3% of measured influence across a batch of outputs, compensation logic can execute transparently rather than relying on a company’s internal accounting. That changes incentives in subtle ways. Data providers stop being invisible labor and start acting more like stakeholders.
Of course, the risks are real. Attribution systems can still be gamed through duplicated datasets or synthetic poisoning. Similarity does not always equal influence, especially in language where common phrasing overlaps naturally. And there is a privacy tension underneath all of this. If attribution becomes too precise, models could unintentionally expose fragments of proprietary or sensitive training data. OpenLedger’s approach remains an early architecture, not a settled answer.
Still, the timing feels important. Right now, centralized AI companies are absorbing larger portions of the data economy while public scrutiny around copyright lawsuits, scraping practices, and licensing fights keeps growing. OpenAI, Anthropic, and Google operate largely as black boxes because opacity scales faster than accountability. OpenLedger is betting that the next phase of AI competition may not center only on model size, but on whether contributors can verify their role inside the intelligence itself.
And maybe that is the deeper pattern here. AI is slowly moving from extraction toward accounting. The systems that survive long term may not be the ones that know the most, but the ones that can prove where their knowledge came from.
