今天下午我在咖啡馆整理资料,旁边两个人聊一个新项目,聊了十几分钟,全是“空投还有没有”“任务要不要刷”“群里有没有白名单”。我听着有点想笑,因为这几年Web3社区大多就是这个味道,热闹的时候几万人在线,活动一结束,群里只剩表情包和抱怨。后来我翻到@OpenLedger 的OpenCircle,第一反应也是,别又来一套社区运营话术吧。
OpenCircle看下来和我想的不太一样。#OpenLedger 这次不是单纯建个群,也不是靠任务把人临时拉过来,而是想把早期开发者、数据贡献者和AI团队放到同一个场子里,让他们围着Datanet、Agent和模型应用去做长期项目。这个差别挺重要,因为一个AI数据链如果只有代币,没有人持续贡献数据,也没有人把数据做成可用的模型,最后就是个空壳。
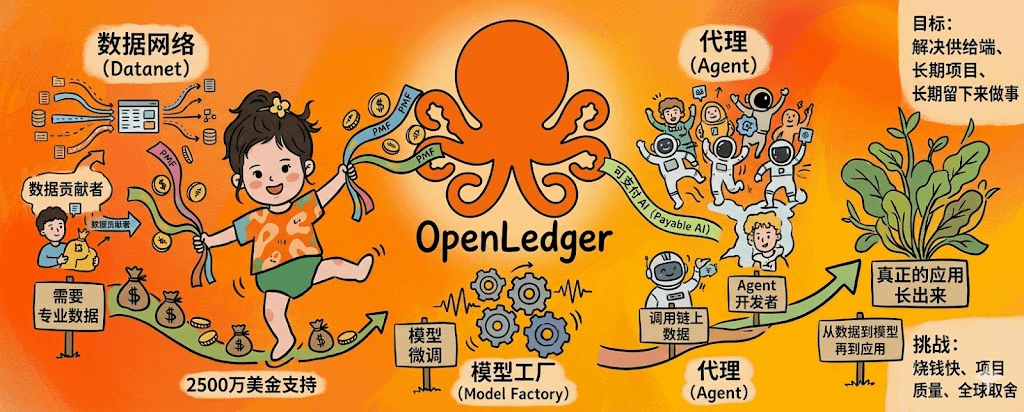
公开信息里提到,OpenCircle会拿出2500万美金支持AI和Web3方向的早期团队。这个数字看起来很大,但我觉得钱本身不是重点,重点是OpenLedger把钱投向了自己最缺的地方。Datanet需要专业数据,Model Factory需要有人做模型微调,OctoClaw需要Agent开发者来调用链上数据。也就是说,OpenCircle不是单独做一场社区活动,而是把OpenLedger手里已有的工具摆到一起,让不同的人都能找到适合自己的。
我5月这周去看了一圈OpenCircle页面和社区讨论,比较明显的感受是,它不像那种大家来共建的空话。很多项目说共建,其实只给你转发任务和积分表;OpenCircle把工具、资金和方向摆出来了。你手里有专业数据,可以围绕Datanet做数据集;你懂模型,可以去试Model Factory;你做Agent,也能想办法接OctoClaw。它给人的感觉不是一起来吹牛,而是你能在这里做一个小产品。
这件事对OpenLedger很关键。OpenLedger讲Proof of Attribution,讲数据归因,讲Payable AI,本质上都离不开供给端。如果没有足够多的数据贡献者,Datanet只是一个空名字;如果没有开发者把数据变成模型,分润机制也没有使用场景;如果没有Agent和应用来调用模型,$OPEN 代币的使用需求也起不来。OpenCircle要解决的,就是这个从数据到模型再到应用的早期循环。
不过我也不想把OpenCircle说得太优秀。2500万美金听起来不少,但AI团队烧钱很快,一个稍微像样的团队,一年花掉几百万美金不奇怪。如果OpenCircle筛选不严,很容易变成花钱买热闹,短期活动很多,长期留下来的东西不多。更麻烦的是,社区项目质量参差不齐,有些团队可能只是借OpenLedger的热度做一轮曝光,东西做出来以后并不会给主网带来多少长期价值。
OpenCircle后面会遇到全球开发者和本地社区之间的取舍。AI数据项目涉及语言、法域和行业数据来源,如果只服务少数地区,开发者网络会变窄;但如果一开始铺得太开,运营成本会很高,项目质量也更难管。这个尺度拿不准,最后可能会变成活动很多,但每个方向都只做了一点点,没能沉淀出几个能被反复使用的产品。
OpenCircle不是OpenLedger旁边挂着的社区招牌,而是主线的一部分。OpenLedger想做AI数据基础设施,光有链和代币不够,还得有人在上面持续建东西,OpenCircle就是把这群人提前聚起来的办法。我会继续看它能不能孵出几个真正被主网使用的应用案例,如果半年后还只是海报、AMA和口号,那它就跟我下午在咖啡馆听到的那些社区没什么区别;但如果真有团队从OpenCircle里长出来,把OpenLedger的链上数据用起来,那它就不是热闹一阵的群,而是一批人愿意长期留下来做事的起点。