
At first, it’s excitement. Every scroll feels like you’re catching fragments of the future before the rest of the world notices. A few months ago, my timeline became completely flooded with conversations about AI agents, autonomous systems, decentralized intelligence, and the idea that artificial intelligence would become the next major economic layer of the internet.
People were posting screenshots of AI agents trading markets, generating research, automating workflows, writing code, even managing communities. The energy around it felt similar to the early DeFi era — chaotic, experimental, slightly confusing, but impossible to ignore.
Naturally, I became curious.
I assumed getting involved with AI would be simple. In my head, it looked easy: open a website, connect a wallet, maybe customize a few settings, click a button, and suddenly you’re participating in the AI economy.
That illusion disappeared almost immediately.
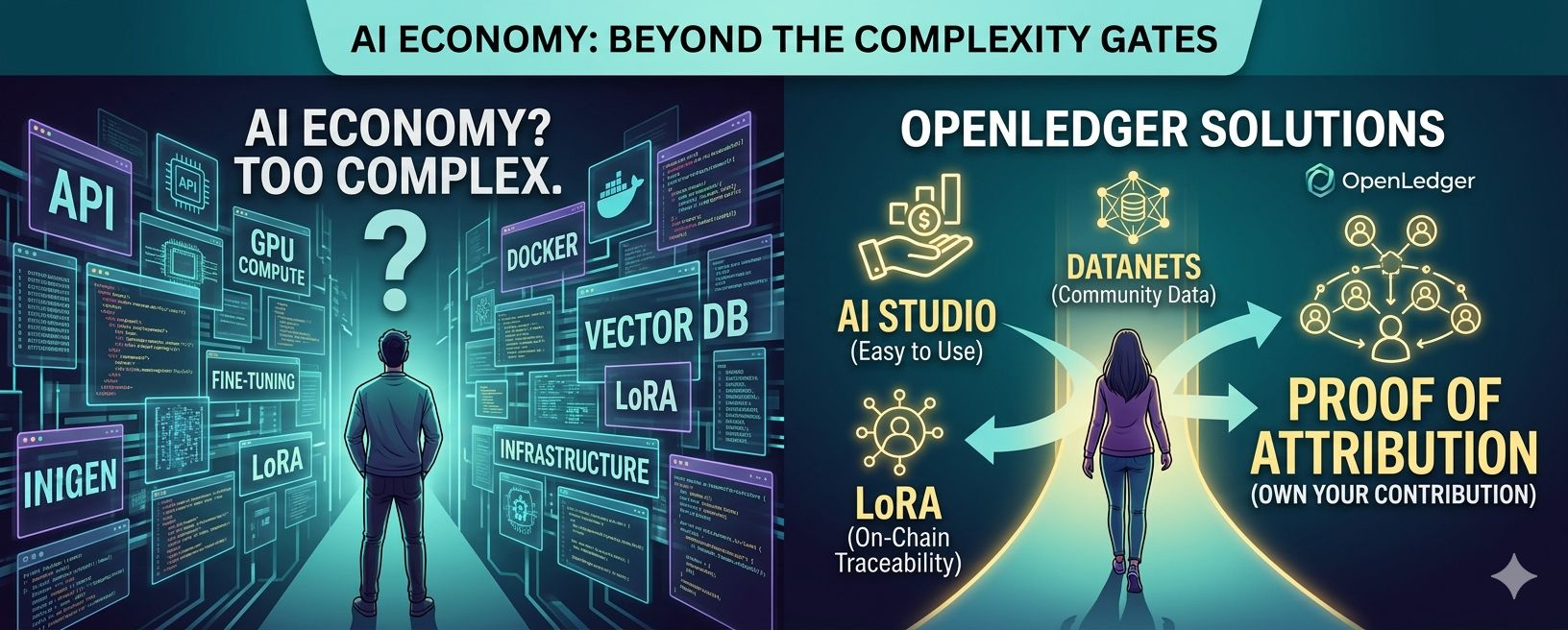
The deeper I went, the more overwhelming everything became. APIs. GPU compute. Model hosting. Fine-tuning. Cloud infrastructure. Deployment environments. Vector databases. Inference layers. Docker containers. LoRA adapters. Python dependencies.
It honestly felt like every tutorial assumed you already had years of technical experience.
I remember opening one documentation page after another and slowly realizing that most AI systems still aren’t designed for ordinary people. Even as someone deeply interested in crypto and emerging technology, I felt mentally exhausted after only a few hours trying to understand how everything connected together.
The strange part is that AI is constantly marketed as the future of humanity, yet participation still feels gated behind developer-level complexity.
And that’s where projects like OpenLedger started catching my attention.
Not because of hype.
But because the project seemed focused on something deeper: the infrastructure problems underneath AI itself.
While most AI narratives in crypto revolve around flashy agents or speculative tokens, OpenLedger appears to be approaching the space from a more foundational angle — transparency, attribution, accessibility, and collaborative intelligence.
That difference matters more than people realize.
Most conversations around AI focus on outputs. OpenLedger seems more interested in the systems that produce those outputs in the first place.
One of the most interesting parts of the ecosystem is its Model Factory and OpenLoRA infrastructure.
At first, even the term “LoRA adapter” sounded intimidating to me. But once I dug into it, the idea became surprisingly understandable.
LoRA — short for Low-Rank Adaptation — is essentially a lightweight way to fine-tune AI models without retraining an entire system from scratch. Instead of rebuilding a massive model every time, developers can create smaller specialized layers that teach the model new behaviors, styles, or expertise.
Think of it like adding modular upgrades onto an existing intelligence system.
A healthcare-focused adapter could teach an AI model medical terminology. A legal adapter could specialize it for case analysis. A multilingual adapter could improve regional language understanding.
The problem is that as these systems become more widespread, transparency starts disappearing.
Who trained the adapter?
What data influenced it?
Can its origins be verified?
Was it manipulated?
This is where OpenLedger’s infrastructure becomes genuinely interesting. By enabling on-chain verification and traceability for LoRA adapters, the project is attempting to create a system where AI components become more transparent rather than more opaque.
That might sound abstract today, but it becomes incredibly important once AI systems begin influencing real-world decisions at scale.
If AI models eventually shape education, financial systems, healthcare workflows, hiring decisions, media creation, or public information, society will inevitably start asking difficult questions about trust.
People will want proof.
Where did this intelligence come from?
Who contributed to it?
What data shaped its behavior?
Can its training history be audited?
Right now, most AI systems operate like black boxes. We see outputs, but we rarely understand the invisible human contributions behind them.
And that leads directly into what might be OpenLedger’s most important concept: Proof of Attribution.
This was the moment where the project stopped feeling like “another AI crypto protocol” to me and started feeling philosophical.
Modern AI systems are trained on humanity itself.
Every day, billions of people contribute fragments of intelligence into the digital world — conversations, research, opinions, code, art, writing, tutorials, memes, translations, datasets, cultural context, emotional expression, and collective knowledge.
Yet once these contributions are absorbed into centralized AI systems, most people disappear from the equation entirely.
No visibility.
No ownership.
No attribution.
No participation in the value being created.
That imbalance feels increasingly difficult to ignore.
OpenLedger’s Proof of Attribution (PoA) attempts to address this by tracking how data contributions influence AI outputs and creating mechanisms where contributors can potentially receive recognition or rewards through the $OPEN ecosystem.
Importantly, it doesn’t feel like a perfect solution yet — and the project itself still appears early in its evolution — but the direction feels meaningful.
Because attribution may eventually become one of the defining conversations of the AI era.
For years, the dominant assumption around AI has been that whoever owns the most compute and the largest models wins. But over time, another question is emerging:
What if the real value comes from proving where intelligence originated?
That shift changes everything.
It reframes AI not merely as software, but as a collaborative economic system built on human contribution.
And honestly, that idea feels difficult to unsee once you start thinking about it seriously.
Another area where OpenLedger becomes particularly compelling is through Datanets.
Most people obsess over models, but data is the actual foundation of every intelligent system. A model is only as useful as the information it learns from.
Datanets introduces the idea that communities themselves can collaboratively build, organize, clean, and structure datasets optimized for large language models and AI systems.
The implications are enormous.
Imagine healthcare research communities building verified medical datasets together.
Or legal professionals organizing transparent legal archives for AI-assisted analysis.
Or multilingual communities preserving regional languages and cultural context that large centralized datasets often ignore.
Or financial analysts collectively refining high-quality market intelligence systems.
These are not unrealistic scenarios anymore.
And perhaps more importantly, decentralized data collaboration could create AI systems that are more globally representative instead of being dominated entirely by a handful of corporations controlling closed datasets.
That distinction matters.
Because whoever controls the data eventually shapes the intelligence.
Then there’s AI Studio, which honestly feels like the most approachable part of the ecosystem for normal users.
This is where OpenLedger starts bridging the gap between infrastructure and accessibility.
AI Studio gives creators, developers, entrepreneurs, and even curious newcomers an environment where they can build, customize, deploy, and potentially monetize AI agents without needing to master every layer of backend infrastructure from day one.
That accessibility is critical.
Mass adoption never comes from complexity.
Every major technological revolution eventually succeeds because the user experience becomes simple enough for ordinary people to participate comfortably.
The internet itself once felt deeply technical. Early websites were confusing. Setting up online services required patience and specialized knowledge. Over time, abstraction layers simplified everything.
The same transition still needs to happen for AI.
And projects focused on usability may become just as important as projects focused purely on model performance.
Of course, none of this guarantees success.
OpenLedger still faces the same difficult realities confronting nearly every ambitious AI infrastructure project: scalability challenges, verification accuracy, adoption hurdles, incentive manipulation risks, governance complexity, and regulatory uncertainty.
Proof of Attribution itself raises complicated questions.
How accurately can contribution influence truly be measured?
Can attribution systems be gamed?
How should rewards be distributed fairly?
What happens when models learn from billions of interconnected sources simultaneously?
These are not easy problems.
But even imperfect attempts feel valuable right now because the broader direction matters.
The AI economy is growing faster than society’s ability to define ownership, accountability, and contribution rights inside it.
And eventually, those questions will become impossible to avoid.
What makes OpenLedger interesting is not the promise that it has already solved everything.
It’s the recognition that these problems exist in the first place.
Because if artificial intelligence eventually becomes one of the largest economic systems humanity has ever created, then attribution may become more than a technical feature.
It may become a social requirement.
For decades, the internet monetized attention.
AI may monetize intelligence itself.
And if intelligence is being trained collectively by humanity, then perhaps the future conversation is not only about who builds the most powerful models — but whether the value created by those models should remain centralized under a small number of entities or evolve into something more collaborative, transparent, and community-driven.
I don’t think we fully know the answer yet.
But projects like OpenLedger are at least forcing the conversation to happen earlier than most people expected.
And honestly, that alone may end up being one of the most important contributions of all.
