There was a time when I had almost stopped paying attention to data infrastructure projects, not because the field had lost its importance, but because I had seen the same unfair pattern too many times. A project would begin with people doing the most invisible and difficult work, collecting raw data, cleaning broken parts, labeling information, adding context, refining weak points, and fine tuning models so that the final system could become more useful. But as the chain moved upward, the trace of that effort would slowly become weaker. By the time the model looked intelligent and the product started receiving attention, the earlier layers had almost disappeared from the story. The final output would be celebrated, while the foundation that made it possible would be treated like something already consumed. This is why Openledger caught my attention in a different way. It touches a problem that has been sitting under the surface of the data economy for a long time: how to make sure that contribution does not fade after one use, but remains connected to the value it continues to create.
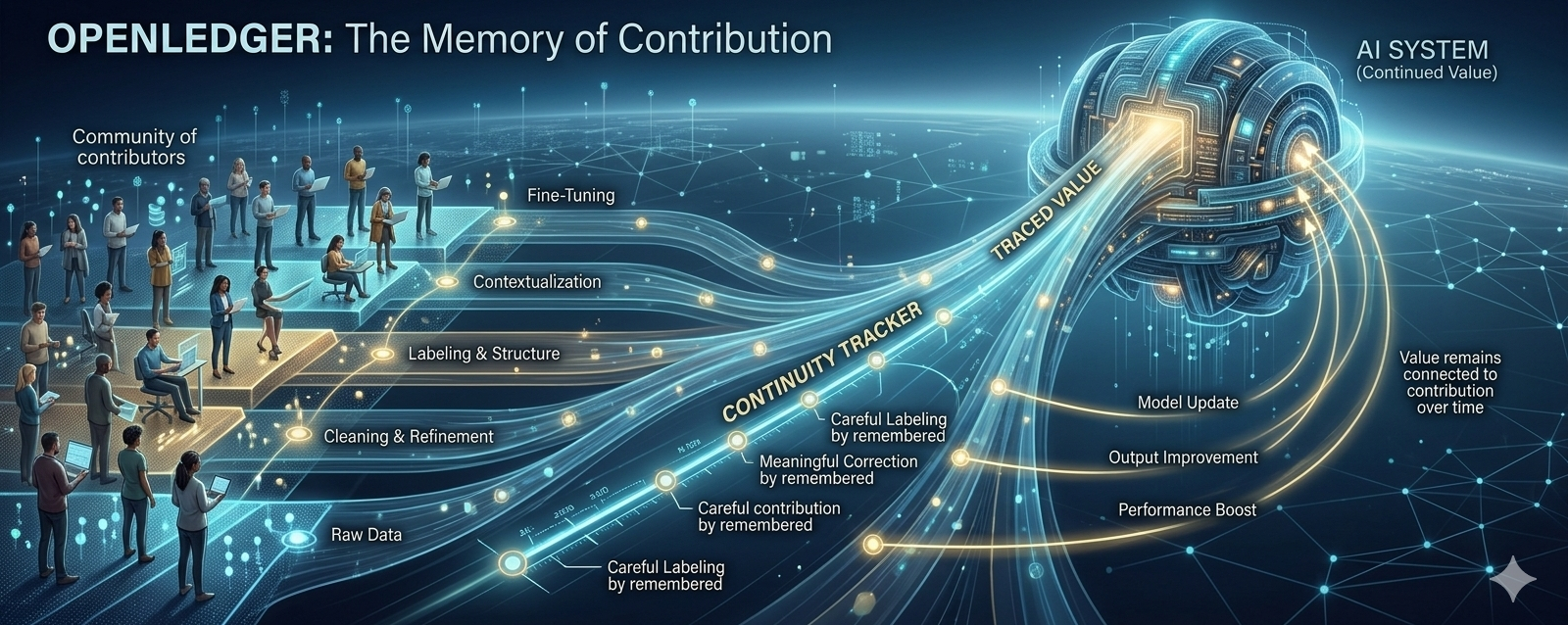
What makes Openledger interesting to me is that it pushes against the old idea that data only matters at the moment it is fed into a system. That view feels incomplete now, because data does not become valuable in a single step. It passes through many hands and many layers before it becomes useful enough to improve a model. Raw data gains strength after cleaning. Cleaning becomes more meaningful when labeling gives it structure. Labeling becomes more powerful when context is added. Context becomes valuable when it improves fine tuning and helps the system produce better results. In most systems, these layers are treated as temporary stages, useful only until the next layer takes over. Openledger feels different because it seems to focus on preserving the relationship between these stages, so that earlier contribution is not completely separated from the final output. That continuity is important, because without it, value keeps moving upward while the people and processes that created it become harder to see.
From a builder’s point of view, the strongest part of Openledger is not just the idea of distributing value. Many projects talk about that, and the words can easily become soft if there is no real mechanism behind them. What feels more serious here is the idea of giving contribution a kind of memory. A good data sample should not be treated as something that existed once and then disappeared into the system. A careful label, a meaningful correction, a useful context layer, or a fine tuned improvement should not lose its identity the moment a new output is produced. If that contribution continues to support future results, then the infrastructure should be able to remember its role. This is where Openledger becomes more than a storage idea. It starts to look like an attempt to build a system where contribution can keep living through the next cycle of usefulness, instead of being reduced to a one time input.
This matters because the market has become too comfortable with extraction that looks normal from the outside. Contributors appear at the beginning, the system absorbs their effort, the model becomes stronger, and then the final layer receives most of the attention. The work done in between becomes compressed into a vague background process, even though the final result would not exist in the same way without it. Openledger does not attract me because it tells a more emotional story about fairness. It attracts me because it is trying to deal with the structure of the problem itself. A promise that contributors will benefit someday is easy to make, but a mechanism that can actually retain the trace of effort is much harder to build. That is why I value the direction of Openledger more than ordinary community language. It is trying to make contribution something the system can continue to recognize, not just something the narrative mentions when it is convenient.
The difficult part is that this kind of problem cannot be solved by adding a few formal recognition layers on top of the system. If contribution is going to remain meaningful in later cycles, Openledger has to solve several hard problems together. It has to identify which contribution actually improved the system, not just who participated. It has to connect that contribution to real effectiveness in the output, not just record it as activity. And it has to keep this whole process working at scale without turning the infrastructure into a heavy bookkeeping machine. This balance is not simple. If the tracking is too weak, the contribution becomes blurry again. If the tracking is too complicated, the system becomes slow and difficult to use. The credibility of Openledger will depend on whether it can keep this logic strong, practical, and scalable at the same time.
This is where I think Openledger enters one of the hardest and most important areas of data infrastructure. Many systems are good at gathering more data, but they are much weaker at understanding which data still has long term value. More data can make a warehouse look bigger, but it does not always make the model better. Some information keeps creating usefulness across cycles. Some only increases volume. Some fine tuned layers genuinely improve performance, while others simply sit inside the system without producing much change. Openledger is interesting because it moves directly into this difficult space, where the history of contribution becomes part of how quality is understood. That is a meaningful shift. It suggests that the future of data infrastructure should not only be about collecting more, but about knowing what actually continues to matter.
The irony is that the market usually rewards the things that are easiest to explain. A rising chart, a user growth number, or a simple performance claim can create attention much faster than a mechanism designed to remember effort. But the harder thing is often the more important thing. Openledger does not only need to prove that data entered the system. It needs to show that the data, the context, the labels, and the fine tuned layers still retain a role when new outputs are formed. That is a much more demanding standard, and it places real pressure on the project’s architecture. For me, this is exactly why the project is worth watching. It is not relying only on a surface image. It is entering a problem that is difficult to prove, difficult to scale, and difficult to simplify without losing meaning.
After watching many cycles in this industry, I have become less impressed by systems that only know how to collect effort and then claim the final result as intelligence. Real durable value does not come from gathering more input alone. It comes from building an infrastructure where each meaningful layer of contribution can remain connected to the value it helps create. That is why I keep following Openledger. Not because everything has already been proven, and not because the idea is easy to execute, but because it is trying to fix an old flaw in the AI and data economy: the way lower layer effort often disappears as soon as the value has been extracted from it. The important question now is whether Openledger can turn the memory of contribution into a real foundation for the value that comes next.
