
Easy to admire the first dedicated model. It answers in the correct domain, feels crisper than a general model and gives a creator something convincing to display . The pain starts when you require a second specialty model, then a tenth. If every fine-tuned variant requires its own entire serving stack, specialization ceases to be a product advantage and becomes an infrastructure bill.
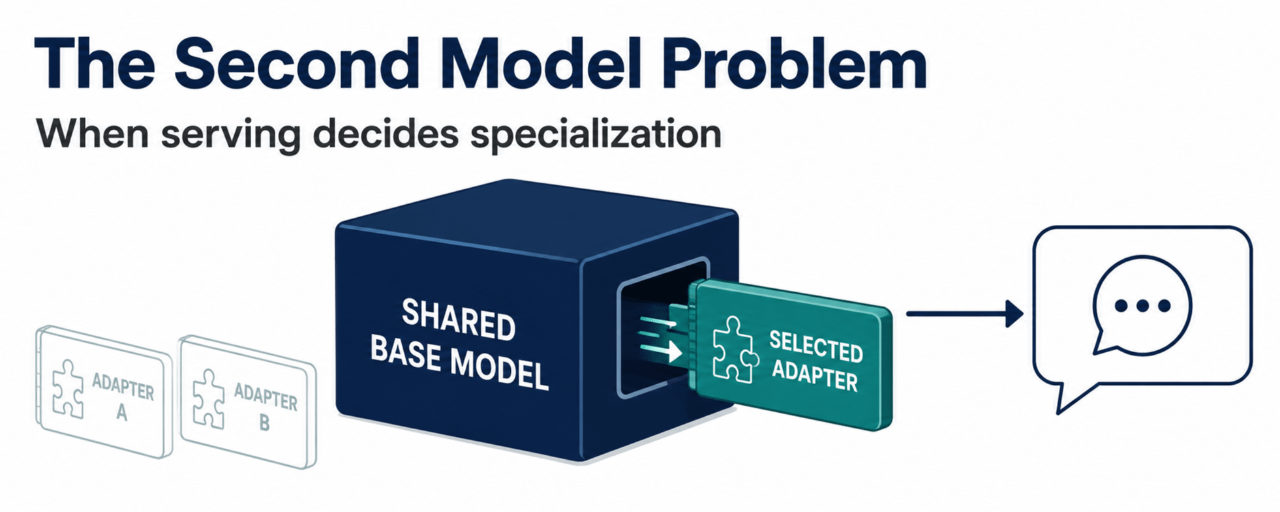
That’s why I’m more interested in OpenLoRA surface of OpenLedger than another broad claim of smarter AI. It's about the awful time when a model has already been made usable. OpenLoRA is designed to host fine-tuned LoRA adapters that sit on top of a common base model, instead than deploying each specialized model as a distinct heavyweight unit. In an actual product decision the distinction is considerable. A constructor can maintain expanding precise capability or start scaling it down when serving becomes too awkward to carry.
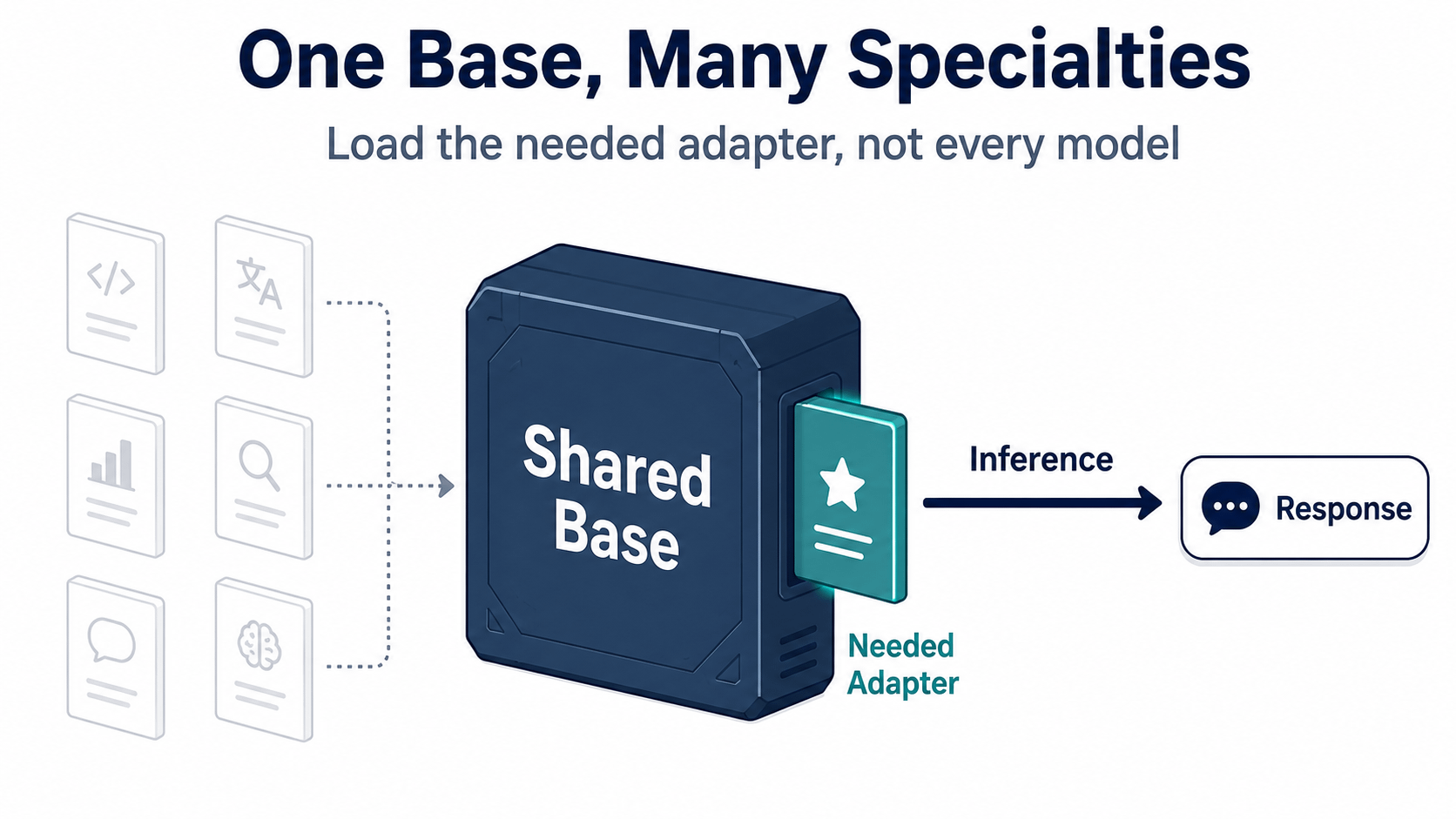
The main thing is not to train one new specialty. It’s calling the proper one when a user really requests for it.
OpenLoRA dynamically loads the required adaptor, merges it into the basic model for inference, and then unloads it after the response to free up GPU RAM. The constructor doesn’t have to store every expert variation in memory, waiting for its turn. OpenLedger phrases this as serving thousands of fine-tuned models on one GPU. I took that as a hard product claim. It says that the narrow usefulness should be able to multiply without having a separate machine sitting behind each narrow model.
This is where specialization either remains outside a demo or is gently trimmed. One assistant may seem easy to its users and require multiple narrow adapters behind it. You need one specialist for one request, another specialized for the next. If the deployment layer can only do that by duplicating infrastructure, then the builder is driven to fewer choices and blunter replies. The offering is becoming less particular while returning users are asking for more specific tasks.
OpenLoRA bets a bit more specifically. Make the base model common. Obtain the adaptor required for the request. Combine at inference. Free the memory after the response. That’s not a nebulous promise of AI becoming more personalised. It's a serving decision that attempts to avoid each new specialty becoming a new permanent hardware load.
This is also why OpenLoRA is a cleaner OpenLedger angle than simply praising fine-tuning. ModelFactory explores the fine tweaking surface. OpenLoRA follows that moment where a trained model either becomes repeatedly useable, or becomes another asset that is too clumsy to serve widely. A builder doesn’t win because there’s a model. The win only happens when a number of specialized models can keep answering without each one requiring another deployment to sustain.
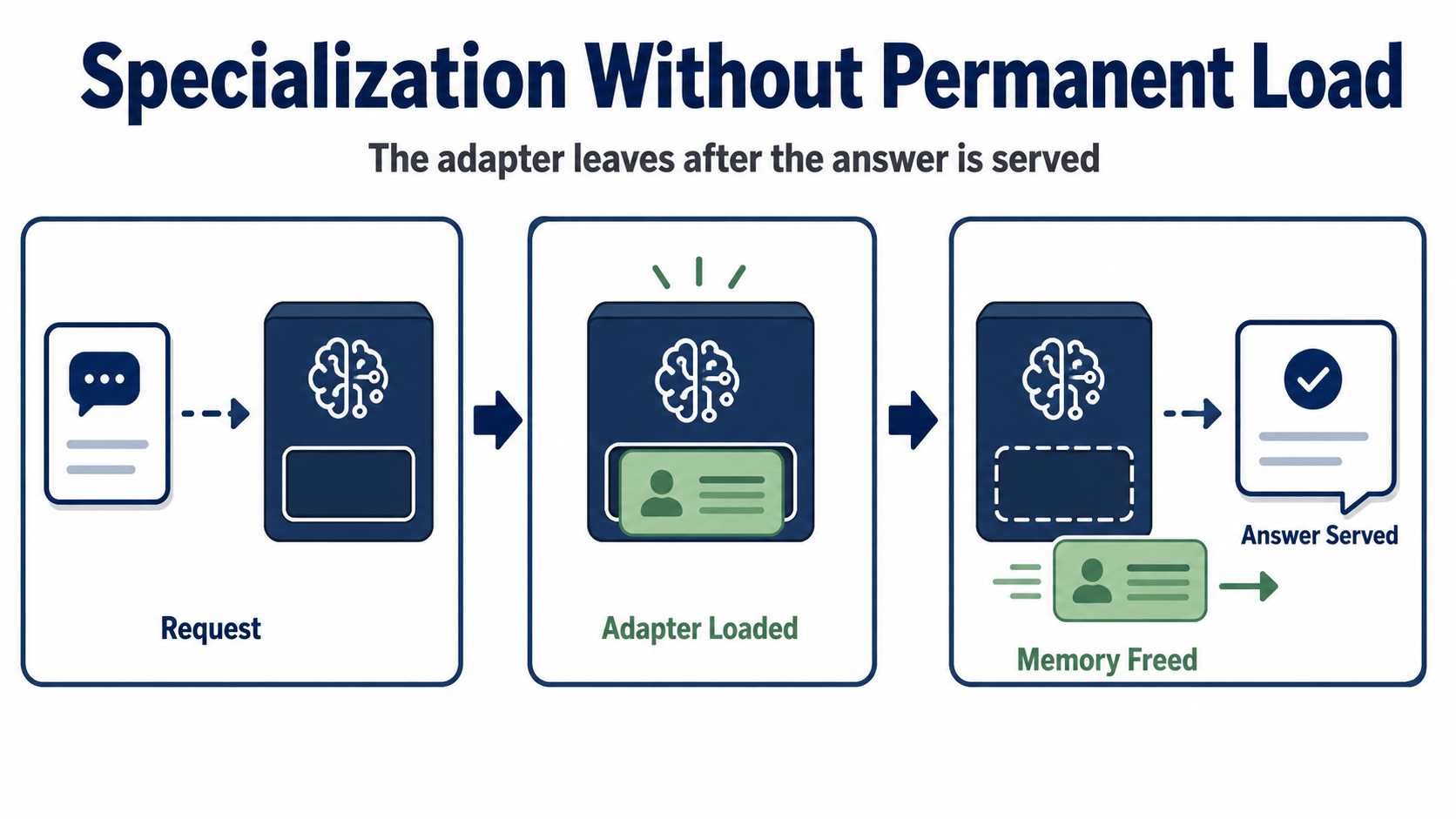
There is one test which I would not soften. Clean architecture: dynamic loading. But real demand is not so civil. Requests are not equally spaced. Some adapters will be called often, some rarely, and users rate the product by reaction speed and output quality, not by a beautiful serving diagram. OpenLoRA only matters if it’s doing that switching pressure when you’re actually requesting several specialty paths, not just storing and available.
A specialty model that can’t be served economically is not a product yet. It’s a successful experiment, but someone has to keep paying for the discomfort.
If OpenLoRA can pass the test of actual switching demand, then an OpenLedger builder won't have to choose between being particular and being deployable. If it doesn’t, every new expertise is another justification not to add the intelligence consumers came for.
#OpenLedger @OpenLedger $OPEN $NEAR $SOL
