
General AI is useful, but sometimes it feels like walking into a huge public library.
There is a lot of knowledge inside.
You can ask almost anything.
You can get a decent answer.
You can move across topics quickly.
But when the problem becomes specific, a public library is not always enough.
If a machine breaks, you do not want a general book about engineering. You want the exact manual for that machine. If a trader is studying a market, they do not want random financial theory. They want the right signals, the right context, and the right data for that market.
That is the difference between general AI and specialized AI.
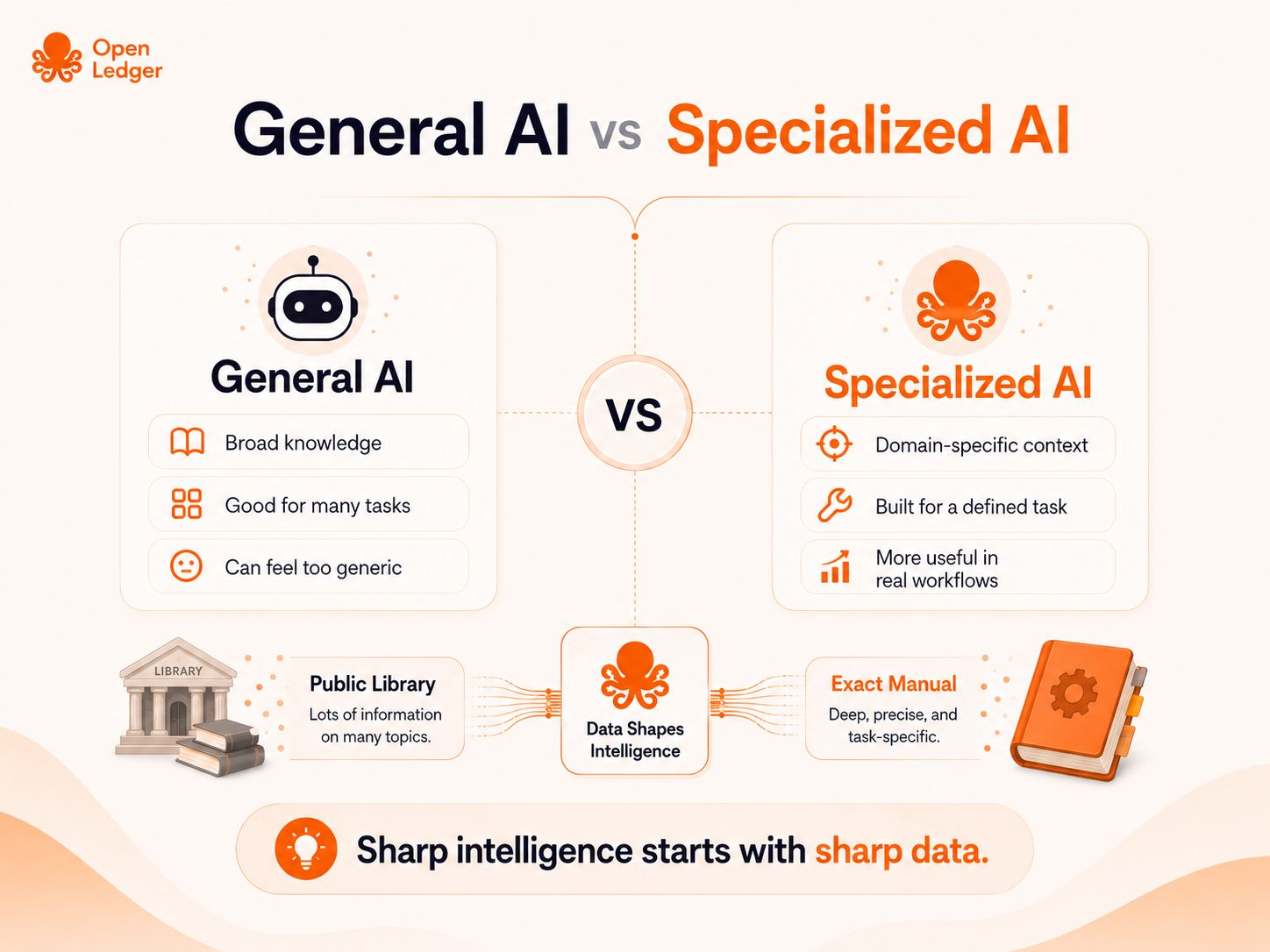
General AI can be broad.
Specialized AI needs to be sharp.
And sharp intelligence usually starts with sharp data.
This is where OpenLedger becomes interesting to me.
I see this mistake a lot when people talk about AI. They keep comparing models like they are racing cars, but they forget to ask what kind of road those cars are driving on.
A powerful model still needs the right data path.
Most people still talk about AI like the model is everything. Bigger model, faster model, smarter model. But the model is only one part of the story. The data behind it decides how useful that intelligence becomes in the real world.
Bad data creates weak output.
Generic data creates generic intelligence.
Specialized data can create specialized value.
That is why OpenLedger’s focus on data, models, and agents makes sense.
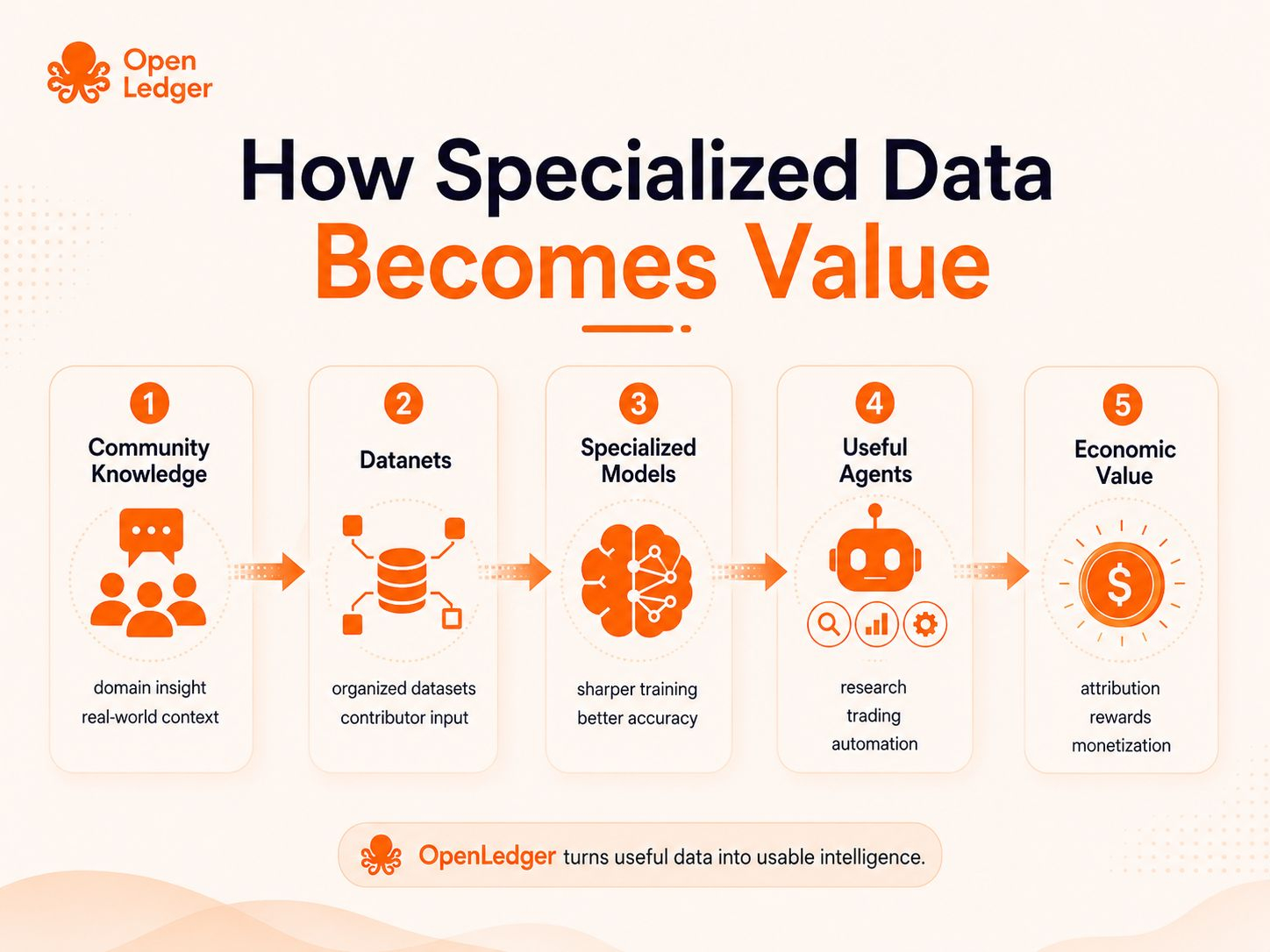
OpenLedger is building around the idea that AI assets should not stay hidden or locked in the background. Data, models, and agents can become traceable, usable, and monetizable parts of the AI economy.
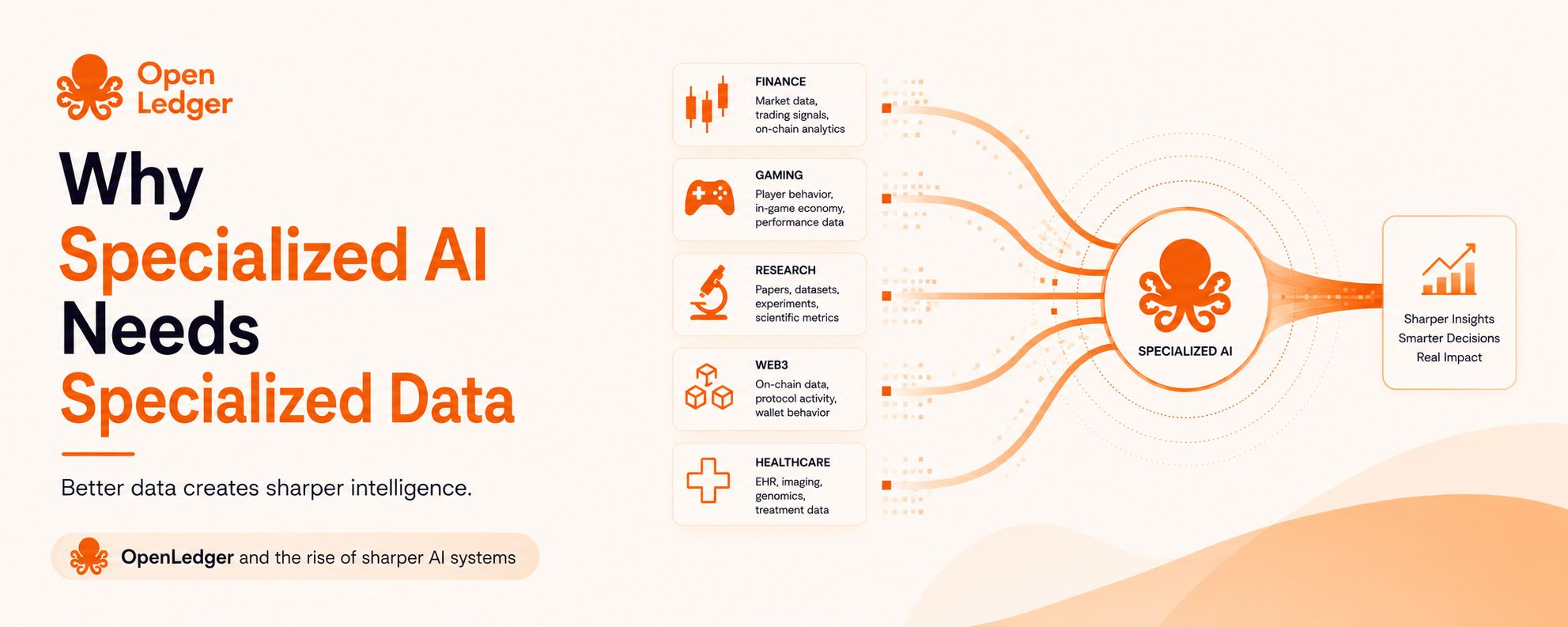
The Datanets idea is important here because specialized AI needs organized data from people who actually understand the domain. A gaming community may know what data matters inside a game. A trading community may understand market behavior better than a random dataset. A developer community may know what makes an agent useful for a specific workflow.
This is how AI can become more practical.
Not by making one model pretend to know everything.
But by creating sharper intelligence layers around real use cases.
A healthcare AI tool needs medical-specific data.
A trading agent needs market-specific context.
A research assistant needs trusted sources.
A Web3 agent needs wallet, protocol, and onchain understanding.
The more specific the job becomes, the more important the data layer becomes.
And this timing matters.
AI is moving from simple chat boxes into agents that can research, trade, automate, and make decisions inside real workflows. Once AI starts doing serious work, the quality of the data behind it becomes harder to ignore.
A weak data layer can create weak decisions, even if the model looks impressive on the surface.
For me, this is where OpenLedger’s relevance becomes stronger than the normal AI narrative.
It is not only talking about smarter models.
It is looking at the system behind the model:
Who provides the data?
How does that data improve intelligence?
How do models use it?
How do agents create value from it?
And how can contributors be recognized?
That is a better question than just asking which model is bigger.
Because if contributors provide useful data, they should not disappear from the value chain. If a dataset improves a model, there should be a way to recognize that contribution. If an agent uses that model to create value, the system should have clearer attribution and reward paths.
Without that, AI becomes another black box.
The output looks smart, but the value behind it stays invisible.
OpenLedger is trying to make that hidden layer more visible.
Of course, this only works if execution is strong. Specialized AI depends on real data quality, active builders, useful models, and agents that people actually want to use. A weak dataset will not become valuable just because it is onchain.
That is the risk side, and it matters.
But the direction is worth watching.
The next AI race may not only be about who builds the biggest model.
It may be about who builds the best data network behind the model.
And if AI moves deeper into trading, gaming, research, automation, and Web3 agents, specialized data may become one of the most valuable assets in the whole system.
That is why OpenLedger feels interesting to me.
It is not selling AI as a buzzword.
It is focusing on the layer that can make AI more useful, more traceable, and more rewarding for the people who help build it.
General AI gives people access to the library.
Specialized AI gives them the right manual.
But the next question is bigger:
Who wrote the manual, who improved it, and who should earn when it creates value?
That is the part OpenLedger is trying to make visible onchain.
And honestly, I think this is the kind of AI infrastructure people may only appreciate properly after agents become part of daily workflows.
