The more I look at decentralized AI, the more I think many people are focusing on the wrong layer.Most discussions revolve around models.
Which model is faster?
Which model is smarter?
Which model has more parameters?
Those are important questions, but they assume the model itself is the center of the ecosystem.
I’m not sure that assumption holds forever.Because as AI systems become more capable, a different challenge starts appearing: trust.
Where did the training data come from?Who owns it?How was it licensed?Who contributed to the model?Can its decisions be verified?Can its outputs be audited?These questions become increasingly important as AI moves closer to real economic activity.
That is one reason OpenLedger has caught my attention recently.
Not because it is launching the largest model.Not because it is making the loudest announcements.But because much of its recent activity seems focused on the infrastructure surrounding AI rather than the model itself.
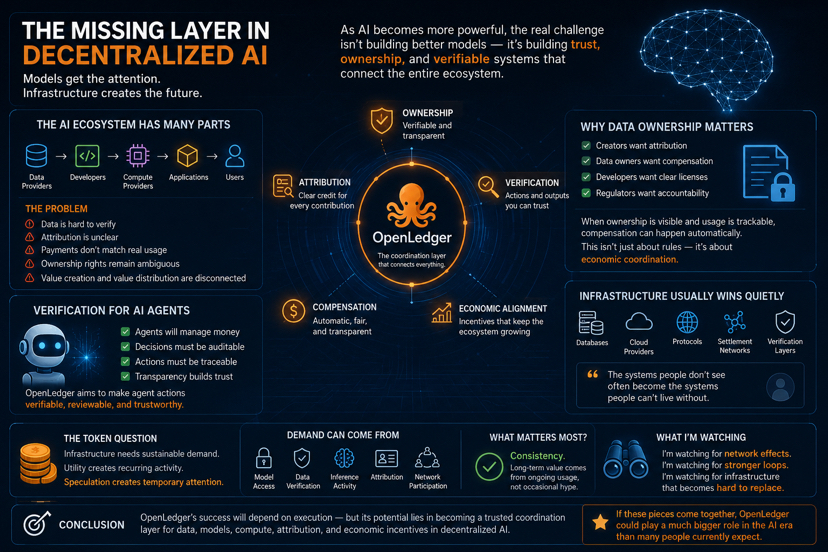
The Missing Layer In Decentralized AI
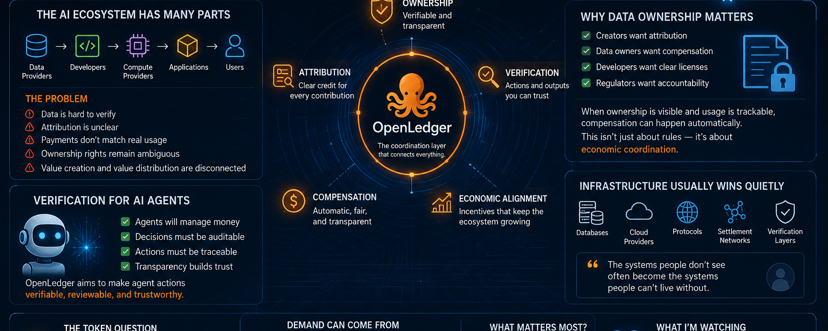
Most AI ecosystems require several components to function.Data providers create datasets.Developers train models.Compute providers supply processing power.
Applications integrate AI into products.Users consume the outputs.The problem is that these components often operate independently.
Data may be difficult to verify.Attribution may be unclear.Payments may be disconnected from actual usage.Ownership rights may remain ambiguous.
As a result, value creation and value distribution frequently become disconnected.This is where OpenLedger appears to be positioning itself.
Rather than competing directly as another AI application, it seems to be building mechanisms that connect these different layers together.
Why Data Ownership MattersOne development that stands out is OpenLedger’s collaboration with Story Protocol.
The broader AI industry continues to struggle with intellectual property questions.Creators want attribution.Data owners want compensation.Developers want clear licensing frameworks.
Regulators want accountability.
Most existing systems handle these requirements poorly.
Information gets collected, reused, transformed, and redistributed with limited visibility into where it originally came from.
OpenLedger’s approach appears to focus on creating clearer ownership pathways.
If ownership can be verified and usage can be tracked, rewarding creators becomes much simpler. Instead of relying on trust or manual agreements, compensation can happen automatically whenever content is used. But the real significance is not just about following rules. It is about creating a system where people who contribute valuable work have a clearer path to being recognized and rewarded for it.It creates a clearer and more direct connection between the people who contribute and the value their contributions generate.It is about making sure the people who create value are easier to identify and reward when their work contributes to the ecosystem.It is about creating a system where contributions are easier to recognize, track, and reward in a transparent way.It creates a clearer connection between contribution and reward, making participation easier to recognize and incentivize.It is about creating a system where ownership, usage, and compensation are connected in a much more transparent and efficient way.
It is economic coordination.When ownership becomes visible, participation incentives often become stronger.Why Verification Matters For AI Agents
Another area worth watching is autonomous agents.AI agents are increasingly being discussed as future participants in financial systems.$OPEN #OpenLedger @OpenLedger 
They may allocate capital.
Execute trades.
Manage portfolios.
Optimize strategies.
The challenge is obvious.
Traditional AI systems often function as black boxes.Users see outcomes without understanding the reasoning behind them.That may be acceptable for some applications.It becomes much more problematic when money is involved.
OpenLedger’s emphasis on verifiable actions suggests an attempt to address this problem.
If agent decisions can be tracked, reviewed, and analyzed, users gain greater visibility into how outcomes are generated.
Transparency does not eliminate risk.But it can make risk easier to evaluate.Infrastructure Usually Wins Quietly
One pattern I continue noticing across technology cycles is that infrastructure projects rarely attract the same attention as consumer-facing products.
Users notice applications.Developers notice infrastructure.That distinction matters.Many of the most valuable technology layers are not the products people interact with directly.
They are the systems operating underneath.
Databases.
Cloud providers.
Communication protocols.
Settlement networks.
Verification layers.
The same dynamic may emerge within AI.The projects creating coordination mechanisms could become just as important as the projects creating models.That possibility makes OpenLedger interesting to observe.
Recent integrations involving cloud infrastructure, compute resources, and AI-related partnerships suggest an effort to strengthen the broader ecosystem rather than simply launch isolated products.
The Token Question Infrastructure alone is not enough.Every crypto project eventually faces the same question.Does the network create sustainable demand?
This is where execution becomes important.
A token gains long-term relevance when it becomes necessary for meaningful activity inside the ecosystem.That activity could involve data verification.
Model access.
Inference.
Attribution.
Whether that demand comes from model access, data verification, inference activity, or participation in the network matters less than one thing: does it happen consistently? Long-term value is usually created by ongoing usage, not occasional bursts of activity.Speculation can create temporary attention.
Utility creates recurring activity.The distinction becomes clearer over time.
What I Am Watching I am less interested in short-term market reactions and more interested in whether OpenLedger’s infrastructure becomes increasingly difficult to replace.
That usually happens when networks create interconnected relationships between participants.Data providers contribute because there is demand.
Developers build because quality data exists.
Applications launch because useful models are available.Users participate because the applications solve real problems.When those loops begin reinforcing themselves, ecosystems become more resilient.
When they fail to form, growth often slows regardless of initial excitement.
Conclusion OpenLedger may ultimately succeed or fail based on execution.
That remains true for every infrastructure project.
But I do not think the project should be viewed solely through the lens of AI narratives or market cycles.
The more interesting question is whether it can become a trusted coordination layer connecting data, models, compute, attribution, and economic incentives.
If that happens, OpenLedger may end up occupying a much larger role in decentralized AI than many people currently expect.
And if it does not, the reason will likely have less to do with model performance and more to do with whether the ecosystem around those models becomes strong enough to sustain itself.$OPEN #OpenLedger @OpenLedger