I have noticed that a lot of AI and crypto infrastructure discussions tend to follow the same pattern. A new framework appears, people immediately describe it as the missing piece that will solve complexity, and for a while it feels like everything is moving toward a cleaner and more efficient future. Then reality arrives. Systems become larger, interactions become more complicated, and the original promise starts looking less straightforward than it did during the excitement phase.
That was one of the reasons I kept thinking about Model Context Protocol (MCP).
When MCP started gaining attention, many people treated it as the coordination layer AI systems had been waiting for. The idea sounded compelling. Different models, tools, and agents would communicate through common standards. Information could move more easily between systems. Workflows would become more predictable. Coordination would become simpler.
But after watching how teams actually operated once the initial excitement settled, something else stood out. A surprising number of builders quietly returned to command-line environments and simpler execution paths. Not because the command line is elegant or modern. It is not. They returned because coordination itself turned out to be expensive.
Every new connection creates dependencies. Every dependency creates additional state. Every piece of state creates history that needs to be maintained. As systems accumulate information, they do not simply become smarter. They become heavier. Every interaction starts carrying traces of everything that came before it. Context grows. Relationships grow. Complexity grows.
That observation eventually changed how I looked at OpenLedger.
Initially, I saw OpenLedger the same way many people do today. An attribution layer for AI. A system designed to track where data comes from, who contributed to model development, and how rewards should be distributed across participants. Contributors provide data, validators verify activity, builders create applications, and the OPEN token functions as the economic layer connecting those interactions.
On the surface, that seems like a straightforward story about transparency and fair compensation.
The longer I thought about it, the less convinced I became that attribution itself is the most interesting part of the equation.
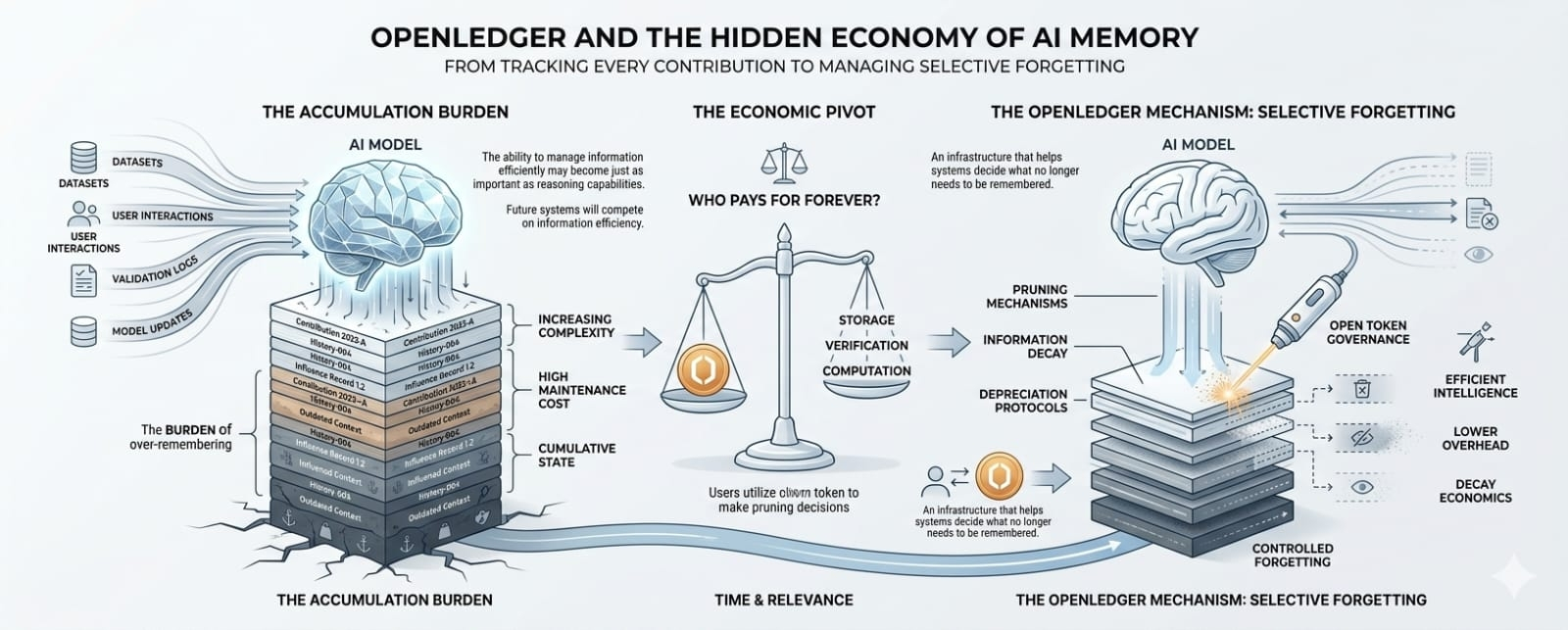
The real challenge begins when information accumulates at scale.
Tracking contributions sounds simple when discussing a few participants or a limited dataset. It becomes something entirely different when millions of interactions, datasets, models, updates, and outputs are constantly influencing one another. Modern AI systems are not built from isolated inputs. They are built from overlapping layers of influence. Information combines with other information. Training effects overlap. Retrieval systems continuously introduce new context. Data that was valuable yesterday may become irrelevant tomorrow. Some contributions matter for a short period and then disappear into the background. Others continue influencing outcomes in ways that are difficult to measure directly.
That makes the idea of perfectly tracking contribution much harder than it initially appears.
Crypto communities often discuss fair attribution as if it is a mathematical problem waiting to be solved. In reality, influence is messy. Intelligence creation is rarely linear. Models absorb countless signals simultaneously. Trying to isolate exactly who deserves credit for a specific outcome becomes increasingly difficult as systems grow.
At the same time, incentives inevitably shape behavior.
We have seen this repeatedly across crypto markets. When rewards are attached to specific activities, participants begin optimizing for the rewards themselves. Liquidity mining encouraged people to optimize liquidity mining. Airdrops encouraged users to optimize airdrop farming. Social incentives encouraged engagement optimization.
AI attribution systems will likely face similar pressures.
If contributors are rewarded based on measurable influence, many participants will naturally begin optimizing for measurable influence. That does not necessarily mean they are optimizing for useful intelligence creation. Those are not always the same thing.
Low-value datasets can flood systems. Synthetic content can generate additional synthetic content. Contributors can learn how to maximize attribution metrics without necessarily improving outcomes. Incentives attract participation, but they do not always attract the kind of participation originally intended.
What interests me even more is the assumption hiding underneath most AI infrastructure discussions.
There seems to be a widespread belief that more information automatically creates more value.
Larger datasets are viewed as better. Longer memory is viewed as better. More personalization is viewed as better. More tracking is viewed as better. More persistence is viewed as better.
I am not sure that assumption holds indefinitely.
Human institutions already provide evidence that information carries costs. Companies spend enormous amounts of money storing data, securing data, auditing data, managing data, and complying with regulations related to data. Information is not free. Keeping information creates obligations. It creates maintenance requirements. It creates risks.
The more information a system retains, the greater the burden associated with preserving it.
That burden may become one of the defining challenges of advanced AI systems.
Imagine every contribution to an AI network as a layer of sediment. Every dataset adds another layer. Every training cycle adds another layer. Every retrieval event adds another layer. Every attribution record adds another layer. Over time, these layers accumulate beneath the system.
Initially, accumulation feels beneficial because more information often improves performance.
Eventually, however, accumulation starts producing friction.
Old contributions remain preserved even when they are no longer relevant. Historical relationships continue existing long after their usefulness has faded. Verification requirements expand. Storage requirements increase. Governance becomes more complicated. Attribution becomes harder to manage. Systems begin carrying historical baggage that may no longer contribute meaningful value.
At that point, information starts behaving less like an asset and more like a liability.
This is where OpenLedger became genuinely interesting to me.
Not necessarily as a marketplace for remembering.
Potentially as a framework that forces people to think about forgetting.
That idea feels strangely underexplored.
Most AI conversations focus on how to preserve information. Far fewer discussions focus on how information should decay over time. Yet almost every successful complex system relies on some form of selective forgetting. Human memory works that way. Organizations work that way. Markets work that way.
Not everything remains relevant forever.
Some information becomes obsolete. Some information becomes expensive to maintain. Some information becomes legally risky. Some information becomes computationally inefficient.
Eventually someone has to decide whether maintaining that information is still worth the cost.
That is where economics enters the conversation.
Who decides what information remains?
Who decides what information expires?
Who pays for maintaining historical influence records?
Who benefits when information is preserved?
Who benefits when information disappears?
Those questions may sound philosophical today, but they are likely to become increasingly practical as AI infrastructure matures.
The more I think about it, the more I suspect future AI systems will compete not only on intelligence but also on information efficiency.
Intelligence matters.
Reasoning quality matters.
Model capabilities matter.
But the ability to manage information efficiently may become just as important.
The systems that succeed may not be the systems that remember everything. They may be the systems that understand what deserves to be remembered and what no longer justifies the cost of preservation.
That possibility also changes how I think about the OPEN token.
For any infrastructure token, the important question is not whether people speculate on it. Speculation exists everywhere. The more important question is whether participants need to acquire the token repeatedly because the underlying system requires continuous maintenance.
Infrastructure demand behaves differently from speculative demand.
Storage requires maintenance.
Validation requires maintenance.
Coordination requires maintenance.
Governance requires maintenance.
If attribution systems become important for AI networks, those requirements may create recurring demand. If information management itself becomes a long-term challenge, recurring demand becomes even more interesting.
Crypto markets are extremely effective at generating narratives. They are less effective at distinguishing between temporary excitement and sustainable utility.
That distinction becomes important when evaluating infrastructure projects.
The story surrounding OpenLedger is often presented as decentralized AI, attribution tracking, contributor rewards, and transparent intelligence creation. Those ideas are important. They are easy to understand. They fit existing market narratives.
What I find more interesting is the question sitting underneath all of them.
What happens when remembering becomes expensive?
What happens when attribution histories become larger than the value they create?
What happens when preserving influence relationships costs more than maintaining the intelligence itself?
At some point, future AI systems may need mechanisms for information depreciation, influence pruning, historical cleanup, and controlled forgetting.
If that happens, the most valuable infrastructure may not be the infrastructure that helps systems remember everything.
It may be the infrastructure that helps systems decide what no longer needs to be remembered.
That is the question I keep returning to whenever I think about projects like OpenLedger.
Not who pays to remember.
Who pays to stop remembering before information itself becomes the burden nobody can afford to carry anymore.
