在区块链搞AI的这帮人,90%都在倒卖算力。今天租个显卡,明天搭个矿池,名义上叫去中心化算力,实际上就是个批了区块链外衣的云服务中介。稍微懂点行的人心里都清楚,真正的AI巨头缺的根本不是你手里那几张散碎的显卡,它们缺的是能喂饱模型的、干净的、有版权的数据。现在的互联网大厂天天在干嘛?在用各种法律条款和技术防火墙把自己的数据圈起来,不给外部的模型爬取。这导致中小AI开发者只能在公网上捡垃圾,吃别人剩下的数据残渣。
我盯了@OpenLedger 很久,它让我觉得有意思的地方在于,它不跟那帮算力贩子去卷硬件,而是直接把手术刀切进了数据源的腹地。但这项目现在的宣发方向有点偏,天天在讲去中心化数据管道,把好端端的技术讲成了无聊的说明书。
 别看那些花哨的概念,直白聊聊它的数据确权
别看那些花哨的概念,直白聊聊它的数据确权
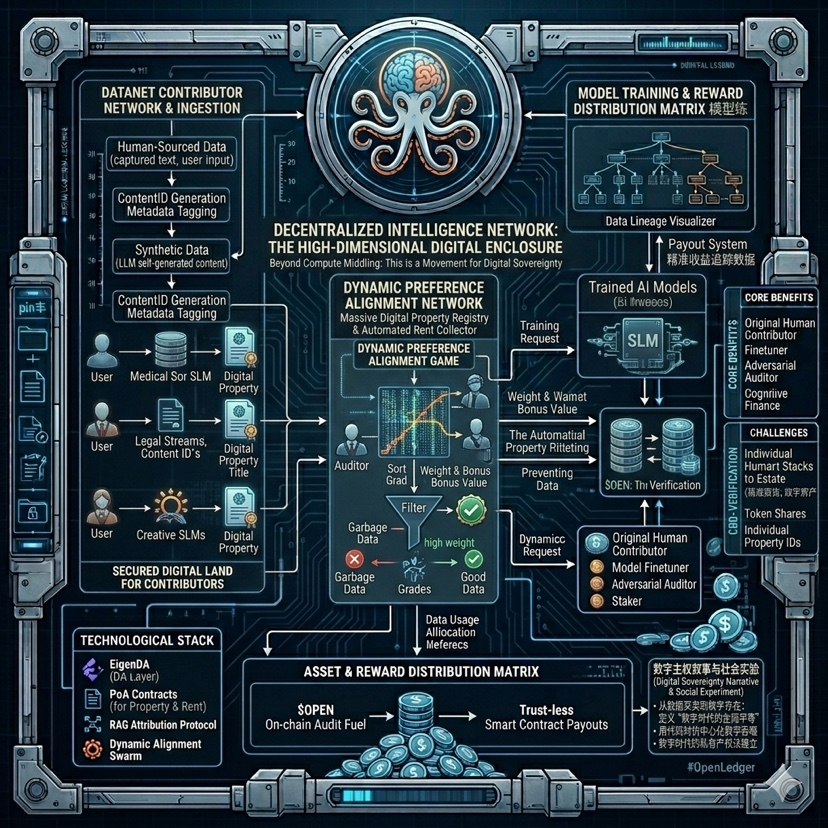
很多人看技术白皮书看得头大,其实OpenLedger的核心逻辑可以用一个很市俗的类比来解释:它就像是给数据世界发“房产证”和“收租器”。
普通的去中心化存储只管把数据存下来,但没人管这个数据是谁的、被谁用了、创造了多少价值。OpenLedger整了一套数据归属引擎。简单来说,你贡献了一段聊天记录或者一份专业报告,它的系统会通过底层的加密逻辑,把你的数据打包成一个独一无二的资产凭证。当某家AI大模型公司在训练的时候用了你的数据,这套引擎就能精准地追踪到,并且自动把收益结算给你。
这解决了一个行业痛点:凭什么谷歌、微软拿我们的公开言论去训AI,赚得盆满钵满,而作为数据生产者的我们连一分钱网费都报销不了?
### 白皮书里藏着的杀手锏:动态偏好对齐网络
如果只是做数据存取和分发,那它顶多是个升级版的网盘。我仔细翻了他们的底层设计,发现了一个之前很少被市场提及的硬核机制:动态偏好对齐网络。
这个概念听起来很学术,说白了就是AI数据领域的“大众点评”加“实时质检员”。现在的AI训练有个巨大的坑,叫数据污染。如果有人恶意投喂垃圾数据或者带有偏见的信息,AI就会变傻甚至变疯。大厂的做法是雇佣成千上万的廉价人工去搞“人类反馈强化学习”,成本高得吓人。
OpenLedger这套机制是用去中心化的节点,对上传的数据进行实时的质量博弈和动态对齐。节点不仅要验证数据的真实性,还要评估数据对特定AI模型训练的“营养价值”。高质量的数据会获得更高的权重和奖励,垃圾数据则会被直接过滤并扣除节点的保证金。
这种设计极其硬核,它把原本需要靠中心化大厂砸几十亿美金才能维持的数据清洗流水线,直接变成了一个由经济利益驱动的、自运转的去中心化博弈场。这才是真正用密码学逻辑去解决AI生产力瓶颈的玩法。
作为一个在行业里摸爬滚打多年的老韭菜,我从来不信什么完美的童话。OpenLedger的逻辑听上去很性感,但实际落地的难度不亚于在荒漠上建大厦。
最大的难点就在于冷启动。AI巨头们有成熟的数据采购渠道,它们凭什么要放弃现有的合规供应商,跑来一个去中心化的网络里买数据?而且,数据隐私也是个巨大的火药桶。如何在保护用户隐私的前提下,把数据喂给AI,这中间的零知识证明技术只要稍微出一点工程落地上的差错,整个信任体系就会瞬间坍塌。
现在的市场都在追求快钱,这种需要沉下心来做底层数据治理的项目,往往在早期会因为技术太重、故事太干而显得有些吃力。
从数据买卖到数字存在
如果把视线拉得更远一点,@OpenLedger 正在尝试构建的东西,在哲学层面上其实是在重新定义“数字时代的生而平等”。
在传统的互联网语境下,我们每个人都是数字农奴。我们在社交媒体上发出的每一句话、上传的每一张照片,都在无形中成了科技巨头们的免费养料。我们在互联网上辛勤耕作,最后却连自己数字身份的数字所有权都没有。
$OPEN 当AI时代全面到来,如果数据依然被垄断,人类的智慧结晶将被异化为少数资本的生产工具。$OPEN 的尝试,本质上是在用代码对抗这种中心化的数字吞噬。它试图在混乱、无序且弱肉强食的数字丛林里,为每一个普通的个体拉起一道确定性的边界。
这不仅仅关乎于你能通过贡献数据拿到多少代币回报,而是关乎于在这个肉身逐渐被数字化取代的未来,你创造的每一秒数字痕迹,究竟是属于你自己,还是属于某台冰冷的、位于大厂机房里的超级服务器。这场关于数字主权的叙事,才刚刚揭开序幕。