说真的,初次翻阅OpenLedger的白皮书,我满脑子就俩字:画饼。通篇全是什么打破数据孤岛、智能体变现这类的华丽辞藻,在这个阿猫阿狗都敢自称DePIN龙头的周期里,难免让人审美疲劳。但作为在这个圈子里蹚过无数雷的老韭菜,深知偏见会让人踏空,索性我直接跑了个节点,亲测一下这个@OpenLedger 究竟是真核弹还是哑炮。
官方吹得最猛的,当属那个叫Datanets的基建。他们的构想挺宏大:号召全网网民一起攒语料、做标注,专门用来喂那些垂直领域的SLM模型,只要干活了就能凭借那个“归属权证明”分到肉吃。单看这套逻辑,直接把Web2巨头垄断桌子给掀了,确实能让人听得热血沸腾。
不过,等我真把闲置主机挂上去跑OpenLedger的采集程序时,滤镜碎了一地。那令人发指的同步进度,真是卡得我怀疑人生。必须承认,把庞杂的数据处理任务分散给散户的烂网络,跟人家大厂那种顶配机房比起来,效率差了十万八千里,根本不在一个维度。
更让人吐槽无力的是它的防作弊规则:你想当劳工贡献算力,竟然还得先掏钱锁仓一部分OPEN代币。这就好比去工地搬砖,包工头让你先交几万块进场费一样荒谬。官方美其名曰保障语料纯净度,但这么高昂的准入条件,无疑把满腔热血的散户直接拒之门外了。
当然,踩归踩,OpenLedger的技术底子还是有些东西的,特别是它的OpenLoRA框架。现在市面上诸如Render之类的项目,基本干的都是显卡租赁的粗活,说白了就是个算力中介。而OpenLedger是让一堆微调过的分支模型共同挂靠在一个母体底座上运作。我盯着后台的性能消耗看了好几天,这种“拼单合租”的模式的确大幅度削减了硬性支出,吞吐量也拉上去了。
只可惜,生不逢时,去中心化AI这条街早就人满为患了。放眼望去,隔壁Bittensor(TAO)早把护城河挖得深不见底,子网里天天都有真实的资金和流量在奔涌。相比之下,OpenLedger更像个精美的PPT演示沙盘。那个ModelFactory操作面板倒挺讨喜,点几下就能炼丹,可现实是,根本没什么真正的开发者在上面跑业务。没有B端老板买单,你攒再多数据也是白搭。
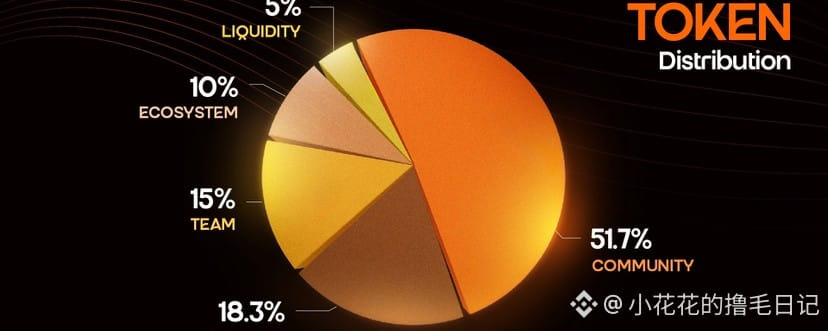
在这泥潭里摸爬滚打了大半个月,趁着现在AI风口还在狂吹,我赶紧去翻了#OpenLedger 的代币经济学,结果惊出一身冷汗。表面上看总量死死卡在10亿枚,分给社区的比例也不小,似乎是个有格局的团队。但致命的定时炸弹就埋在今年,准确说是2026年的秋天,也就是9月份。
届时,那些机构和创始团队熬过了12个月的冷静期,天量的筹码将迎来解禁。足足有超3亿枚的OPEN会如同开闸放水一般进入市场流通。
大家自己掂量掂量,以目前$OPEN的盘面价折算,等同于每个月都有几百万美金的货往外砸。大伙应该没忘OpenLedger去年刚上Binance时的高光时刻吧,逼近两美元后直接腰斩再脚踝斩,暴跌超八成。如今这波反弹,纯粹是因为庄家手里的牌被冻着,盘子轻好拉升而已。
等到九月大门一开,面对成百上千倍的账面浮盈,指望这些风投资本家发善心不套现?做梦去吧。
总而言之,OpenLedger试图打造去中心化HuggingFace的宏伟叙事,听起来确实很香。但在冰冷的二级市场里,再牛逼的技术也扛不住排山倒海的抛压。如果熬到9月,它的生态里还没能憋出个能大规模消耗$OPEN 的杀手级应用,那满溢出来的筹码绝对会把后进场的接盘侠活埋。
经历这番彻头彻尾的调研,我愈发敬畏这个嗜血的市场。至于OpenLedger最终是成为颠覆赛道的真神,还是沦为无人问津的赛博坟墓,就让接下来的链上数据去验证吧。我的策略很简单:死守本金,作壁上观,绝对不碰那些带血的筹码。
