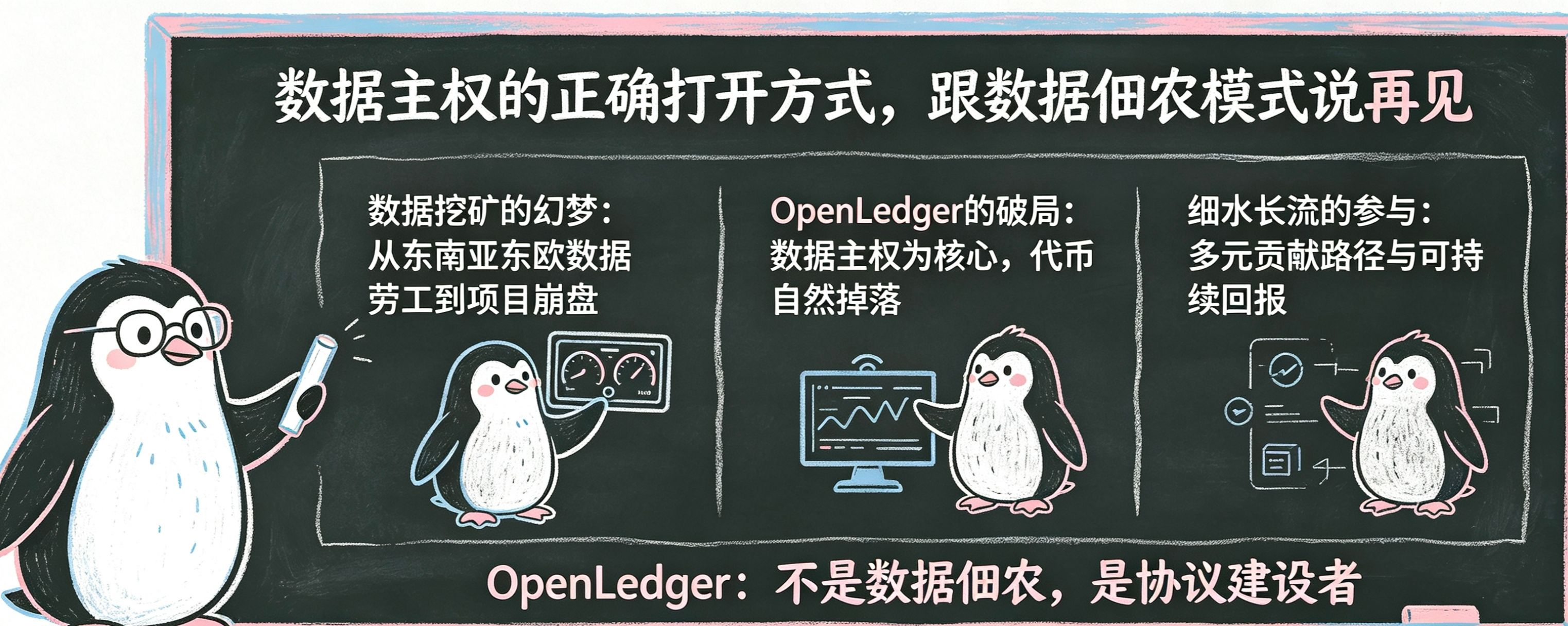
数据挖矿这个概念刚出来的时候,很多人以为自己终于能靠刷手机、跑节点、填表单赚到钱了。那时候东南亚和东欧冒出一大批"数据劳工",每天盯着仪表盘上传数据、刷验证量,像数字佃农一样给平台交租子,指望月底结算的代币能覆盖电费和生活费。结果不到两年,这批项目死得七七八八,代币归零的速度比数据上传速度还快,参与者不仅没赚到钱,反而把时间和电费搭了进去。现在回头看,那种模式根本不是数据民主,是数据佃农制,平台拥有数据,用户出卖劳动力,换回来的代币还随时可能变成废纸。
问题出在根子上。当网络变成纯粹的代币分发机器,当用户的每一次点击、每一次上传、每一次验证都只是为了换钱,数据本身的价值就被架空了,剩下的只有KPI和焦虑。这种数据佃农模式的死法千篇一律:代币激励远超真实数据需求,价格崩盘,佃农撤退,项目凉透。过去几年这个剧本在数据赛道重复了太多次,Storage、Compute、Bandwidth,每个赛道都倒过一批,换汤不换药。
@OpenLedger 走的是另一条路。它没有一上来就喊"来挖矿暴富",而是先解决一个真问题:你的数据到底归谁?在这个基础上再谈经济回报,顺序很重要。你参与OpenLedger不是为了当佃农,你是为了验证数据归因、扫描测试网数据流、调试轻节点参数、提交协议改进提案。这些事本身就有技术参与感,代币是你做这些事的过程中自然掉落的副产品,不是你打开Dashboard的唯一理由。
这种设计最值钱的地方在于,它把数据主权和代币收益剥成了两层。你的数据贡献、你的验证记录、你的节点信誉,这些价值不会因为代币价格涨跌而消失。我自己2026年还在用OpenLedger,OPEN的价格从高点跌下来不少,但我没退坑,因为我在这个网络里积累的数据归因记录和验证信誉是实打实的,即使明天代币归零,这些链上足迹仍然证明我参与过这个协议的早期建设。这跟那些纯靠币价活着的数据矿工完全不同,他们的参与价值是挂在代币价格上的,价格崩了人就散了,OpenLedger让建设者的价值沉淀在协议里,而不是悬浮在K线图上。
回报节奏也是反着来的。老式数据挖矿追求集中爆发,今天跑满带宽明天就想回本;OpenLedger的回报是渗透式的、长尾的,每天扫描的数据流、提交的验证结果、参与的治理投票,单项收益都不高,但加起来稳定可预期。这种"细水长流"让参与者的心态从"挖完就跑"变成"长期持有",你不是在打工,你是在入股一个正在生长的数据协议。而且贡献路径很多,数据扫描、归因验证、节点维护、测试网反馈、文档翻译,每条路都能拿到回报,但 none 能让你一夜暴富,这种多元性逼着你选自己真正擅长的方向,而不是所有人都挤在一条最卷的赛道上内卷。$BTC
更关键的是,OpenLedger没有绑架你的时间。老式数据挖矿要求7×24小时在线,机器不能停,人也不能睡;OpenLedger的任务池和验证周期设计让每天的有效参与时间有自然上限,花一两个小时做完核心验证,剩下的时间该干嘛干嘛。这种设计承认了人的真实生活状态:没人愿意把生命耗在仪表盘前面。$ETH
但说实话,这套模式也有硬伤。回报分散意味着单位时间收益确实不高,如果你是ROI优先的投机者,OpenLedger会让你觉得"这币怎么不拉盘"。它吸引的不是想快速翻倍的赌徒,而是愿意把协议参与当长期爱好的建设者,后者的池子天然比前者小,这是OpenLedger在规模化上的天花板,改机制也改不了。
另一个隐患是,边贡献边赚的可持续性仍然跟代币价格挂钩。如果OPEN跌到接近零,经济回报可以忽略不计,到时候即使协议本身有价值,币价带来的情绪污染也会劝退一批人。OpenLedger在测试网阶段做了锁仓和通胀控制,但2026年整个加密市场都不温不火,外部环境不是团队能控制的,这是真考验。
总的来说,$OPEN 在方向上走出了数据佃农的老路,把数据主权和使用价值放回了中心,代币只是锦上添花。这个思路比大多数同行清醒,但经济韧性、建设者规模、协议深度这三个问题还需要时间验证。如果你想找一个能踏踏实实参与一两年的数据协议,顺便赚点零花钱,OpenLedger值得放进观察名单。但如果你是来赌快钱的,说实话,这篇文章对你没用,#openledger 从一开始就不是为赌徒设计的。