入行到现在,我见过太多把几个开源模型套个API、发个代币就敢管自己叫“去中心化OpenAI”的PPT项目。大家都在二道贩子的生意里打转,拼命去卷英伟达的显卡,却选择性忽略了一个最致命的问题:
模型是公开的,算力是租来的,那决定AI生死的高质量数据,到底是谁的?
盯了很久的去中心化AI赛道,我最近把目光落在了 @OpenLedger 上。他们不跟风去炒作算力租赁,而是直接抄了AI巨头的后路,去啃最硬的骨头:高质量数据的确权与追溯。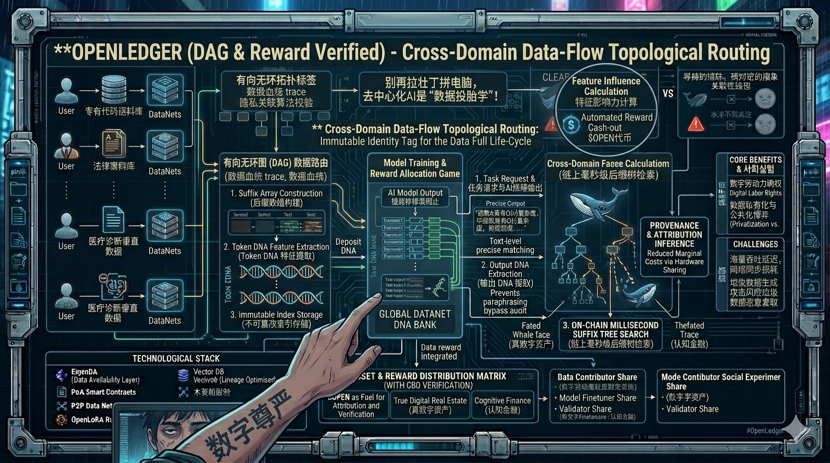
通俗点说,以前的去中心化AI是“拉壮丁拼电脑”,而OpenLedger要做的是“给数据发出生证明”。
别被宏大叙事骗了,聊聊白皮书里的硬核干货
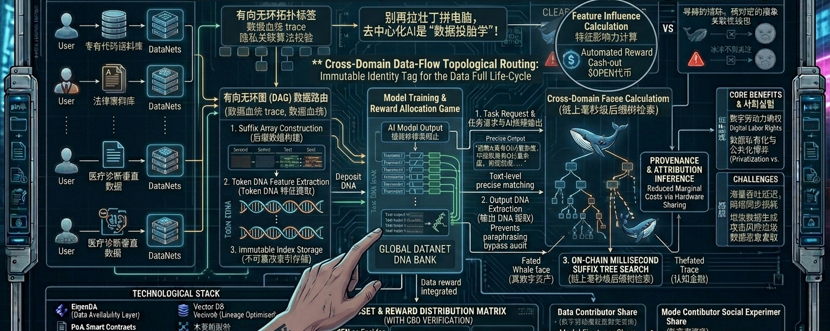
很多人看AI项目只看叙事,我习惯先扒代码和白皮书。在OpenLedger的底层架构里,除了大家熟知的去中心化存储,我注意到一个极少被市场提及、但极其关键的隐秘技术:**“跨域数据流拓扑路由”(Cross-Domain Data-Flow Topological Routing)**。$OPEN
别被这串长名词吓退,我们用大白话来翻译。
现在的AI大模型是个黑盒,数据喂进去,吐出来一个答案。在这个过程中,你的数据被清洗了多少次、跟哪些别人的数据发生了交叉混淆、最后对模型的贡献度是多少,根本是一笔糊涂账。这就好比你把一万斤优质小麦送进面包厂,最后出来的面包里有沙子、有别人的劣质面粉,厂家却拍拍屁股说分不清哪块面包是用你的面粉做的,拒绝给你分利润。
OpenLedger这套技术,本质上是在去中心化网络里构建了一个**“数据有向无环图(DAG)”的动态路由**。
当一份高质量的行业数据从你的本地节点出发,通过网络传输时,这个路由机制会像交警一样,不仅实时记录数据的传输轨迹,还能利用一种**隐式有向关联算法**,在不泄露数据隐私的前提下,把这份数据与其他数据的融合路径、演变过程全部打上拓扑标签。
这意味着,数据不仅在静态存储时有版权,在动态传输和交叉计算的“流动状态”下,依然带着你的身份钢印。这就是 $OPEN 区别于那些只做静态存储(如Filecoin或Arweave)或者单纯做算力调度(如Render)的底层逻辑。它管的是数据从“出生”到“变现”的全生命周期。
圈内的务实吐槽:理想很丰满,骨感在哪里?
作为老韭菜,我从来不相信有完美无缺的方案。OpenLedger的愿景听起来很性感,但实际落地时,有几个不得不面对的工程痛点。
用去中心化路由去追踪数据流,最大的敌人就是延迟和带宽损耗。AI训练需要的是极度高频、海量的数据吞吐。你在每一层数据流动中去记录拓扑结构、去生成可验证凭证,这本身就会带来巨大的计算开销。
如果网络节点不够稳定,或者全球路由节点的同步出现毫秒级的偏差,整个数据流的追踪链条就会断裂。如何在高并发的AI训练场景下,让这套复杂的拓扑路由跑得比传统的中心化服务器还要稳、还要快?这是团队必须在主网交出的答卷,而不是只停留在白皮书里的数学公式。
再者,数据投喂不是一次性的。数据会变旧,模型会过时。如何持续吸引源源不断的高质量原生数据,而不是一堆互联网垃圾信息,这极其考验其通证经济学在实际运行中的摩擦系数。
撕开技术表象,这其实是一场数字世界的“圈地运动”
跳出代码和代币经济学,我们从更高的维度来看看这场博弈。
现在的中心化AI巨头,本质上是在进行人类历史上最大规模的“数据掠夺”。他们拿着我们每天在互联网上产生的言论、文章、艺术创作,免费喂养他们的吞吐巨兽,最后封装成收费的商业服务再卖给我们。这是赤裸裸的数字殖民。
#OpenLedger 的出现,其真正的哲学价值在于**重构数字生产力与生产关系的契约**。
它通过技术手段把“数据”从一种可以被随意复制、任意掠夺的无主物,变成了具有独特物理属性、可追踪、可计价的数字资产。
这不仅仅是Web3对AI的一次技术补丁,它是一场关于数字主权的启蒙。未来,当大模型成为人类社会的底层基础设施时,我们每一个人,究竟是沦为被算法收割的数字农奴,还是成为共同持有AI资产的合伙人?
在这个技术狂飙却走向极权的时代,我们需要这样的反叛者。虽然前路漫长,甚至可能充满坎坷,但至少有人在底层协议的泥潭里,为普通人的数据尊严,钉下了第一根木桩。