Let’s just start with the obvious mess.
Data is everywhere, but nobody really owns it in a way that feels fair. Companies scrape it, users generate it, platforms profit from it, and most people don’t even think twice about it because that’s just how the internet has always worked. But now AI is sitting on top of all of it, chewing through everything, and the scale is getting a bit uncomfortable if you actually stop and look at it.
Everyone keeps talking like AI is magic. It’s not. It’s just trained on massive piles of human output. Text, images, code, conversations, clicks, behavior. All of it. And then a few companies turn that into billion-dollar systems. That part is real.
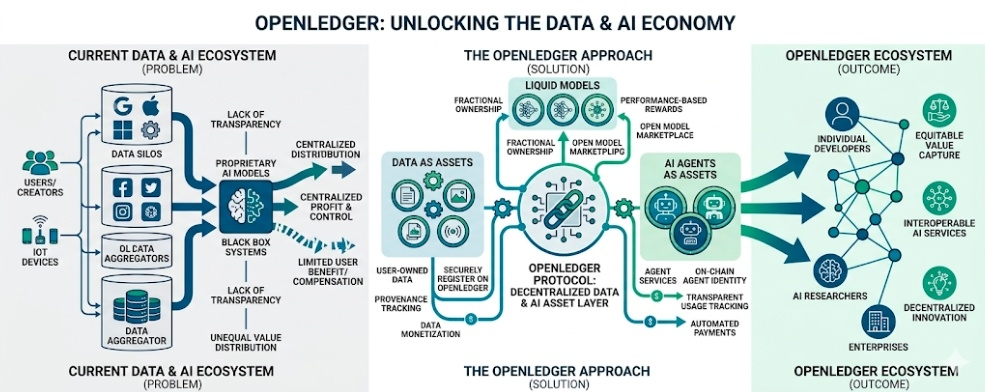
Now you’ve got projects like OpenLedger saying they want to fix the imbalance. Make data, models, and AI agents “liquid” like assets you can trade or monetize. On paper, that sounds like one of those ideas that gets thrown around a lot in crypto circles. You’ve heard it before. “We’re going to unlock value.” “We’re building the future economy.” Stuff like that.
But if you ignore the buzzwords for a second, the problem they’re pointing at is actually real.
Right now, data is locked up everywhere. It’s stuck inside platforms. You give it away just by using apps. You don’t see where it goes. You don’t get paid for it. You don’t even really get asked in any meaningful way. It just happens.
And AI makes that worse, not better.
Because now your data isn’t just used for ads. It’s used to train systems that can replace work. That changes the stakes a bit. But the system underneath hasn’t changed at all. It’s still the same setup. A few companies collect everything. Everyone else just feeds the machine.
OpenLedger is trying to say: what if that wasn’t the only way?
What if data could actually be treated like something that has ownership attached to it? What if models themselves could be traded or rewarded based on usage? What if AI agents that do work could be tracked and paid in a clear way instead of disappearing into some black box system?
That’s the idea anyway.
The reality is, this is where things get messy fast.
Because how do you even measure the value of data? One person’s browsing history doesn’t mean much alone. But millions of users together? That becomes something else entirely. Same with models. One tweak might improve performance, but how do you split credit between ten people who contributed in different ways over time?
It’s not clean. It’s not simple. And anyone telling you it is probably hasn’t tried to build it.
And then there’s the blockchain part.
Crypto people love to say blockchain fixes trust. Sometimes it does. Sometimes it just moves the trust problem somewhere else and adds complexity on top. That’s the uncomfortable truth nobody likes to say out loud in these discussions.
But the idea here is not crazy. If you actually want to track ownership of data, contributions to models, or usage of AI agents across systems that don’t trust each other, you need something transparent. A shared record. Otherwise everything falls back into centralized control again.
So yeah, blockchain shows up.
Now you’ve got OpenLedger sitting right in that intersection. AI on one side. Crypto on the other. And in the middle this idea that data, models, and agents should behave more like assets instead of invisible infrastructure.
Sounds neat. Also sounds like something that could go wrong in a lot of different ways.
Because let’s be honest. Most of these systems don’t fail because the idea was totally wrong. They fail because the execution gets complicated, incentives get messy, and real users don’t care unless it actually makes their life easier.
And that’s the part people keep skipping.
Nobody wakes up excited about “liquidity layers for AI assets.” They care if something works. If it saves time. If it pays fairly without turning into a headache. If it doesn’t require reading a whitepaper just to understand what’s going on.
If OpenLedger or anything like it actually wants to matter, it has to survive contact with reality. Not theory. Not token economics diagrams. Real usage. Real developers. Real data pipelines that don’t break every five minutes.
And honestly, that’s where most of these projects struggle.
Still, the underlying problem doesn’t go away just because the execution is hard.
AI is eating everything. Data is being generated nonstop. Value is being created in places people don’t really see. And the gap between who creates value and who captures it is still pretty wide.
You can ignore that for a while. Most people do. The system keeps running.
But it’s starting to feel like one of those things that won’t stay quiet forever.
So yeah, OpenLedger might be right about the problem. Whether it’s right about the solution is a different question entirely. That part is still open. And probably will be for a while.
