i went through the datanet forking documentation a few days ago and the mechanism was more thoughtfully designed than most AI data infrastructure projects bother to build — actually. version control for community datasets. the ability to branch from an existing datanet, improve the data quality, specialize for a narrower domain, and run as an independent contributor community. for a six-month-old mainnet this is more data infrastructure sophistication than most comparable protocols ship in their first year.
then i traced what happens to attribution when a fork succeeds.
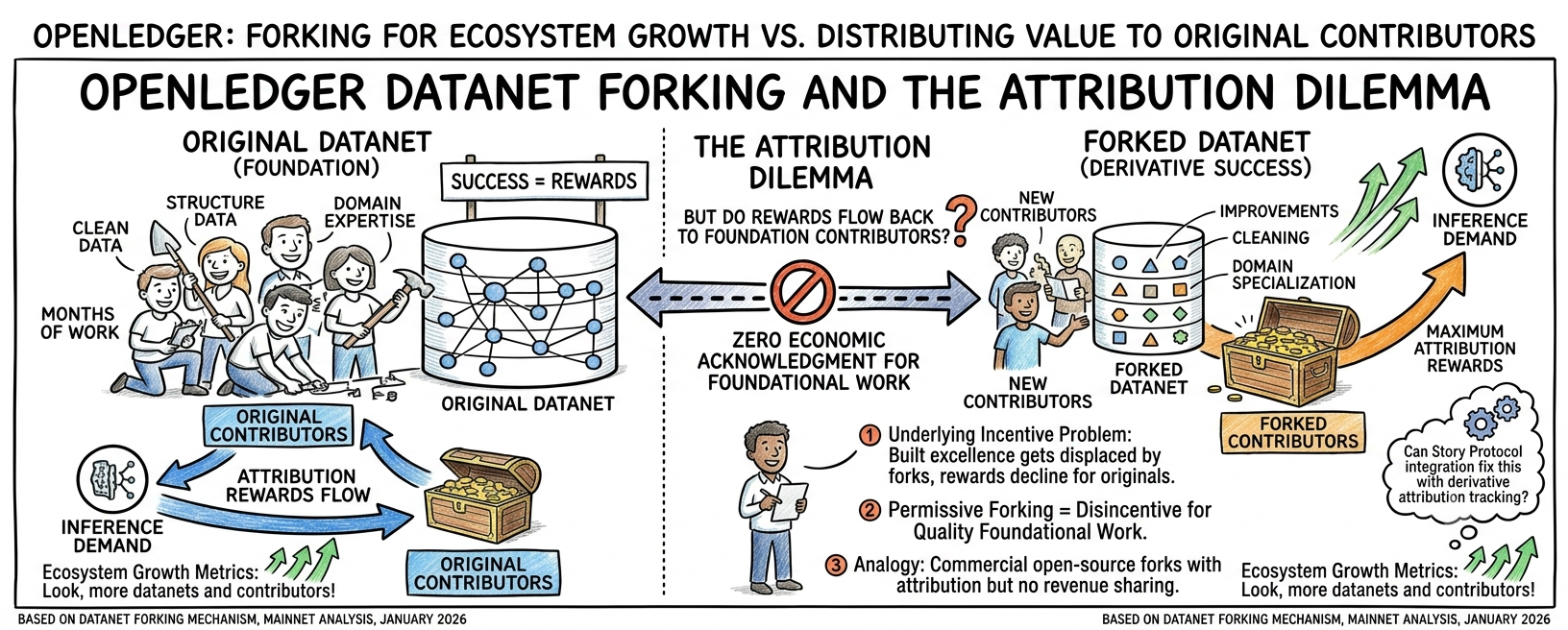
a datanet gets forked. the fork takes the original data as its starting point. new contributors join the fork, add domain-specific improvements, clean existing entries, restructure the dataset. the fork's model outperforms the original. developers prefer the forked datanet's outputs. inference demand flows to the fork. attribution rewards flow to the fork's contributors.
nothing flows to the contributors who built the original datanet the fork was built on. 🔍
that attribution boundary matters in a specific way that the forking metrics don't reveal. from the outside, a successful fork looks like pure ecosystem growth — more datanets, more contributors, more specialized models, more inference demand. those are all genuine positive signals. what the metrics don't show is the distribution of value within that growth. the original contributors who spent weeks or months building foundational domain data — data good enough that someone decided it was worth forking — receive no economic acknowledgment that their work seeded the fork's success. the fork's attribution records start fresh. the original contributors' influence on the fork's outputs is real but invisible to the attribution system.
the specific consequence this creates is a contributor incentive problem that only surfaces over time. in the short term no individual contributor notices. their original datanet is still generating attribution events. their rewards are still flowing. the fork is someone else's datanet. but as the fork attracts more inference demand and the original datanet's relative usage declines — because the fork is genuinely better — the original contributors find themselves in a paradox: they built something good enough to fork, which caused the fork to succeed, which caused their own rewards to decline. the better their original work was, the more likely it is that a fork displaced them.
i watched something structurally similar happen with open source software licensing in the early 2000s. developers built foundational libraries under permissive licenses. commercial products forked those libraries, improved them, built businesses on top of them. the original developers received attribution in the form of acknowledgment but no economic participation in the commercial success their foundational work enabled. the permissive license was technically correct. the economic outcome felt structurally wrong to developers who built the foundation. it created a specific disincentive for quality foundational work — if your work is good enough to be forked commercially, you receive no benefit from the fork.
openledger's datanet forking mechanism has the same structural shape. the fork is technically legitimate. the attribution records are technically accurate for the fork's own contributors. the foundational contributors are simply outside the attribution boundary. and that boundary creates a specific incentive to build mediocre datanets rather than excellent ones — because excellent datanets attract forks that capture the value you created without sharing it with you.
the genuinely strong element here is that the story protocol compliance partnership from january 2026 is specifically designed to track data usage and attribution across derivative works. that partnership exists in part because the legal AI training data problem involves exactly this question — when a dataset derived from original creative work generates value, who gets credited. if story protocol's attribution framework extends to datanet forking within openledger, the foundational contributor attribution problem may already have a legal and technical solution being built in parallel with the protocol's forking mechanics.
there is a version of this where i'm wrong. openledger could have implemented fork attribution — a mechanism that traces a portion of a fork's attribution rewards back to the original datanet's contributors, weighted by how much of the fork's data originated from the parent. if that mechanism exists and is running, foundational contributors receive ongoing economic participation in forks that built on their work. the attribution engine update from january 2026 was specifically designed to maintain data-output links as models evolve — extending that thinking to fork boundaries would be the natural next step. what i couldn't find in the public documentation was confirmation that fork attribution exists as a distinct feature.
what i'd want to see is not a description of how forking works. an actual public example of a forked datanet where the original datanet's contributors received attribution rewards from the fork's inference activity — showing the specific on-chain mechanism that connected fork usage to parent attribution. that record, appearing from any datanet fork that has reached meaningful inference volume since mainnet launched, would tell me whether openledger built its forking mechanism to grow the ecosystem while protecting foundational contributors or simply to grow the ecosystem. its absence means the forking system isn't exploitative — it's just incomplete. exploitative would be intentional. incomplete just means the incentive hasn't been designed all the way through yet.
