



Wie der Meister Leonardo da Vinci einst sagte: "Lernen erschöpft den Geist nie." Aber im Zeitalter der künstlichen Intelligenz scheint es, dass das Lernen möglicherweise die Ressourcen unseres Planeten an Rechenleistung erschöpfen könnte. Die KI-Revolution, die bis 2030 voraussichtlich über 15,7 Billionen Dollar in die globale Wirtschaft pumpen wird, basiert grundlegend auf zwei Dingen: Daten und der schieren Kraft der Berechnung. Das Problem ist, dass die Skalierung von KI-Modellen in einem atemberaubenden Tempo wächst, wobei die für das Training benötigte Rechenleistung sich etwa alle fünf Monate verdoppelt. Dies hat einen massiven Engpass geschaffen. Eine kleine Handvoll riesiger Cloud-Unternehmen hält die Schlüssel zum Königreich, kontrolliert das Angebot an GPUs und schafft ein System, das teuer, genehmigungspflichtig und ehrlich gesagt ein bisschen fragil für etwas so Wichtiges ist.
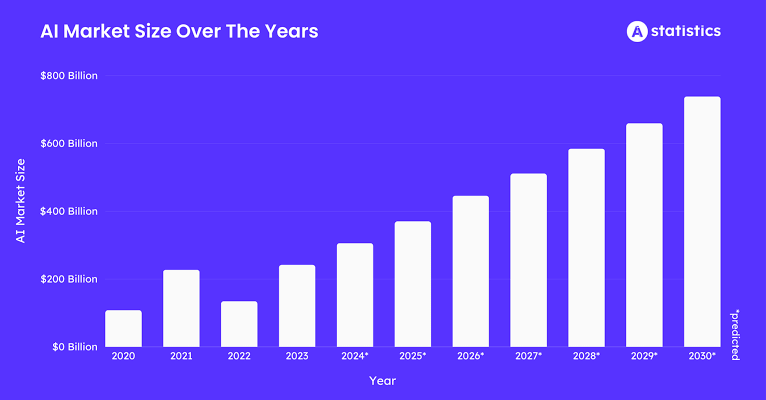
Hier wird die Geschichte interessant. Wir erleben einen Paradigmenwechsel, eine aufkommende Arena namens dezentrales KI (DeAI) Modelltraining, die die Kernideen von Blockchain und Web3 nutzt, um diese zentrale Kontrolle herauszufordern.
Schauen wir uns die Zahlen an. Der Markt für KI-Trainingsdaten wird bis 2025 etwa 3,5 Milliarden Dollar erreichen, mit einer Wachstumsrate von etwa 25 % pro Jahr. Alle diese Daten müssen verarbeitet werden. Der Blockchain-KI-Markt selbst wird bis 2025 voraussichtlich fast 681 Millionen Dollar wert sein, mit einer gesunden Wachstumsrate von 23 % bis 28 % CAGR. Und wenn wir das größere Bild betrachten, wird der gesamte Bereich der dezentralen physischen Infrastruktur (DePIN), in dem DeAI Teil davon ist, voraussichtlich 32 Milliarden Dollar im Jahr 2025 überschreiten.
Was das alles bedeutet, ist, dass die Gier der KI nach Daten und Rechenleistung eine enorme Nachfrage schafft. DePIN und Blockchain treten ein, um das Angebot bereitzustellen, ein globales, offenes und wirtschaftlich intelligentes Netzwerk zum Aufbau von Intelligenz. Wir haben bereits gesehen, wie Token-Anreize Menschen dazu bringen können, physische Hardware wie drahtlose Hotspots und Speicherlaufwerke zu koordinieren; jetzt wenden wir dasselbe Spielbuch auf den wertvollsten digitalen Produktionsprozess der Welt an: die Schaffung künstlicher Intelligenz.
I. Der DeAI-Stack
Der Drang nach dezentraler KI ergibt sich aus einer tiefen philosophischen Mission, ein offeneres, widerstandsfähigeres und gerechteres KI-Ökosystem aufzubauen. Es geht darum, Innovation zu fördern und der Konzentration von Macht entgegenzuwirken, die wir heute sehen. Befürworter ziehen oft zwei Arten der Weltorganisation in Betracht: ein "Taxis", das eine zentral entworfene und kontrollierte Ordnung ist, im Gegensatz zu einem "Kosmos", einer dezentralen, emergenten Ordnung, die aus autonomen Interaktionen wächst.

Ein zentralisierter Ansatz für KI könnte eine Art "Autocomplete für das Leben" schaffen, bei dem KI-Systeme subtil menschliche Handlungen anstoßen und Stück für Stück unsere Fähigkeit, selbst zu denken, untergraben. Dezentralisierung ist das vorgeschlagene Gegenmittel. Es ist ein Rahmen, in dem KI ein Werkzeug zur Förderung des menschlichen Wohlstands ist, nicht zur Steuerung desselben. Durch die Verteilung der Kontrolle über Daten, Modelle und Rechenleistung zielt DeAI darauf ab, die Macht zurück in die Hände von Nutzern, Schöpfern und Gemeinschaften zu legen und sicherzustellen, dass die Zukunft der Intelligenz etwas ist, das wir teilen, nicht etwas, das einigen wenigen Unternehmen gehört.
II. Dekonstruktion des DeAI-Stacks
Im Kern können Sie KI in drei grundlegende Teile zerlegen: Daten, Berechnung und Algorithmen. Die DeAI-Bewegung dreht sich darum, jede dieser Säulen auf einer dezentralen Grundlage neu aufzubauen.
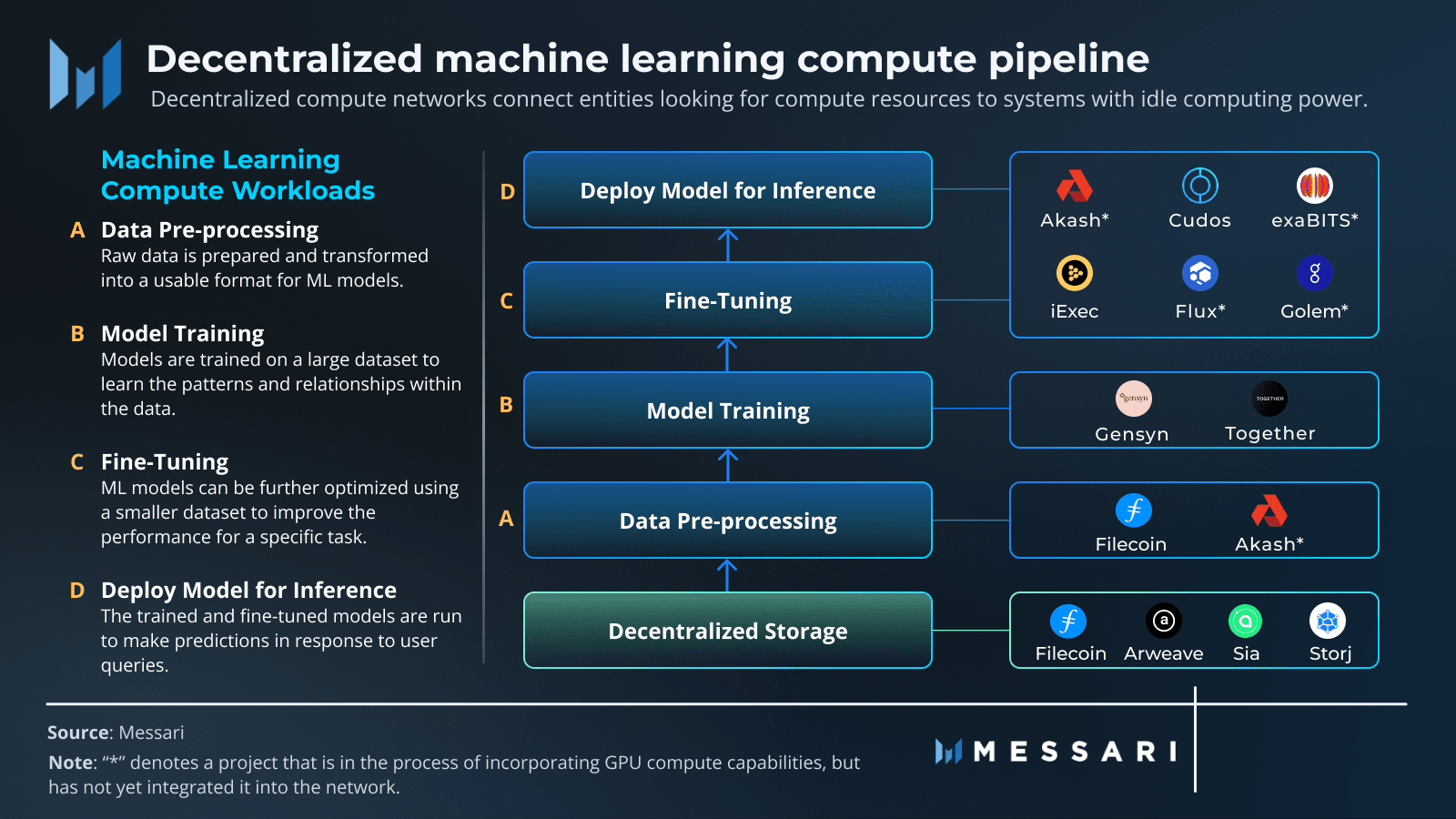
❍ Säule 1: Dezentrale Daten
Der Treibstoff für jede leistungsstarke KI ist ein massiver und vielfältiger Datensatz. Im alten Modell wird diese Daten in zentralisierten Systemen wie Amazon Web Services oder Google Cloud eingeschlossen. Dies schafft einzelne Ausfallpunkte, Zensurrisiken und erschwert es Neulingen, Zugang zu erhalten. Dezentrale Speichernetzwerke bieten eine Alternative und bieten ein dauerhaftes, zensurresistentes und verifizierbares Zuhause für KI-Trainingsdaten.
Projekte wie Filecoin und Arweave sind hier Schlüsselakteure. Filecoin nutzt ein globales Netzwerk von Speicheranbietern, die mit Tokens incentiviert werden, um Daten zuverlässig zu speichern. Es verwendet clevere kryptografische Beweise wie Proof-of-Replication und Proof-of-Spacetime, um sicherzustellen, dass die Daten sicher und verfügbar sind. Arweave hat einen anderen Ansatz: Sie zahlen einmal, und Ihre Daten werden für immer auf einem unveränderlichen "permaweb" gespeichert. Indem Daten in ein öffentliches Gut verwandelt werden, schaffen diese Netzwerke eine solide, transparente Grundlage für die KI-Entwicklung und stellen sicher, dass die für das Training verwendeten Datensätze sicher und für alle zugänglich sind.
❍ Säule 2: Dezentrale Berechnung
Der größte Rückschlag in der KI besteht derzeit darin, Zugang zu leistungsstarker Rechenleistung, insbesondere GPUs, zu erhalten. DeAI geht dieses Problem direkt an, indem es Protokolle erstellt, die Rechenleistung aus der ganzen Welt, von handelsüblichen GPUs in den Wohnungen der Menschen bis hin zu untätigen Maschinen in Rechenzentren, sammeln und koordinieren können. Dies verwandelt Rechenleistung von einer knappen Ressource, die man von einigen Gatekeepern mieten muss, in eine flüssige, globale Ware. Projekte wie Prime Intellect, Gensyn und Nous Research bauen die Marktplätze für diese neue Rechenwirtschaft.
❍ Säule 3: Dezentrale Algorithmen & Modelle
Die Beschaffung der Daten und der Rechenleistung ist das Eine. Die eigentliche Arbeit besteht darin, den Prozess des Trainings zu koordinieren, sicherzustellen, dass die Arbeit korrekt erledigt wird, und alle zur Zusammenarbeit in einer Umgebung zu bringen, in der man nicht unbedingt jemandem vertrauen kann. Hier kommt eine Mischung aus Web3-Technologien zusammen, um den operativen Kern von DeAI zu bilden.
Blockchain & Smart Contracts: Denken Sie an diese als das unveränderliche und transparente Regelbuch. Blockchains bieten ein gemeinsames Hauptbuch, um nachzuvollziehen, wer was getan hat, und Smart Contracts setzen die Regeln automatisch durch und vergeben Belohnungen, sodass Sie keinen Mittelsmann benötigen.
Federated Learning: Dies ist eine Schlüsseltechnologie zum Schutz der Privatsphäre. Es ermöglicht KI-Modellen, auf Daten zu trainieren, die an verschiedenen Standorten verstreut sind, ohne dass die Daten jemals bewegt werden müssen. Nur die Modellaktualisierungen werden geteilt, nicht Ihre persönlichen Informationen, was die Benutzerdaten privat und sicher hält.
Tokenomics: Dies ist der wirtschaftliche Motor. Tokens schaffen eine Mini-Ökonomie, die Menschen für wertvolle Beiträge belohnt, sei es Daten, Rechenleistung oder Verbesserungen der KI-Modelle. Dadurch werden die Anreize aller Beteiligten auf das gemeinsame Ziel ausgerichtet, bessere KI zu entwickeln.
Die Schönheit dieses Stacks liegt in seiner Modularität. Ein KI-Entwickler könnte einen Datensatz von Arweave abrufen, das Netzwerk von Gensyn für verifizierbares Training nutzen und dann das fertige Modell in einem spezialisierten Bittensor-Subnetz bereitstellen, um Geld zu verdienen. Diese Interoperabilität verwandelt die Teile der KI-Entwicklung in "Intelligenz-Legos" und entfacht ein viel dynamischeres und innovativeres Ökosystem, als es jede einzelne, geschlossene Plattform jemals könnte.
III. Wie dezentrales Modelltraining funktioniert
Stellen Sie sich vor, das Ziel ist es, einen weltklasse KI-Koch zu schaffen. Der alte, zentralisierte Weg besteht darin, einen Lehrling in einer einzigen, geheimen Küche (wie der von Google) mit einem riesigen, geheimen Kochbuch einzuschließen. Der dezentrale Weg, unter Verwendung einer Technik namens Federated Learning, ist mehr wie das Führen eines globalen Kochclubs.
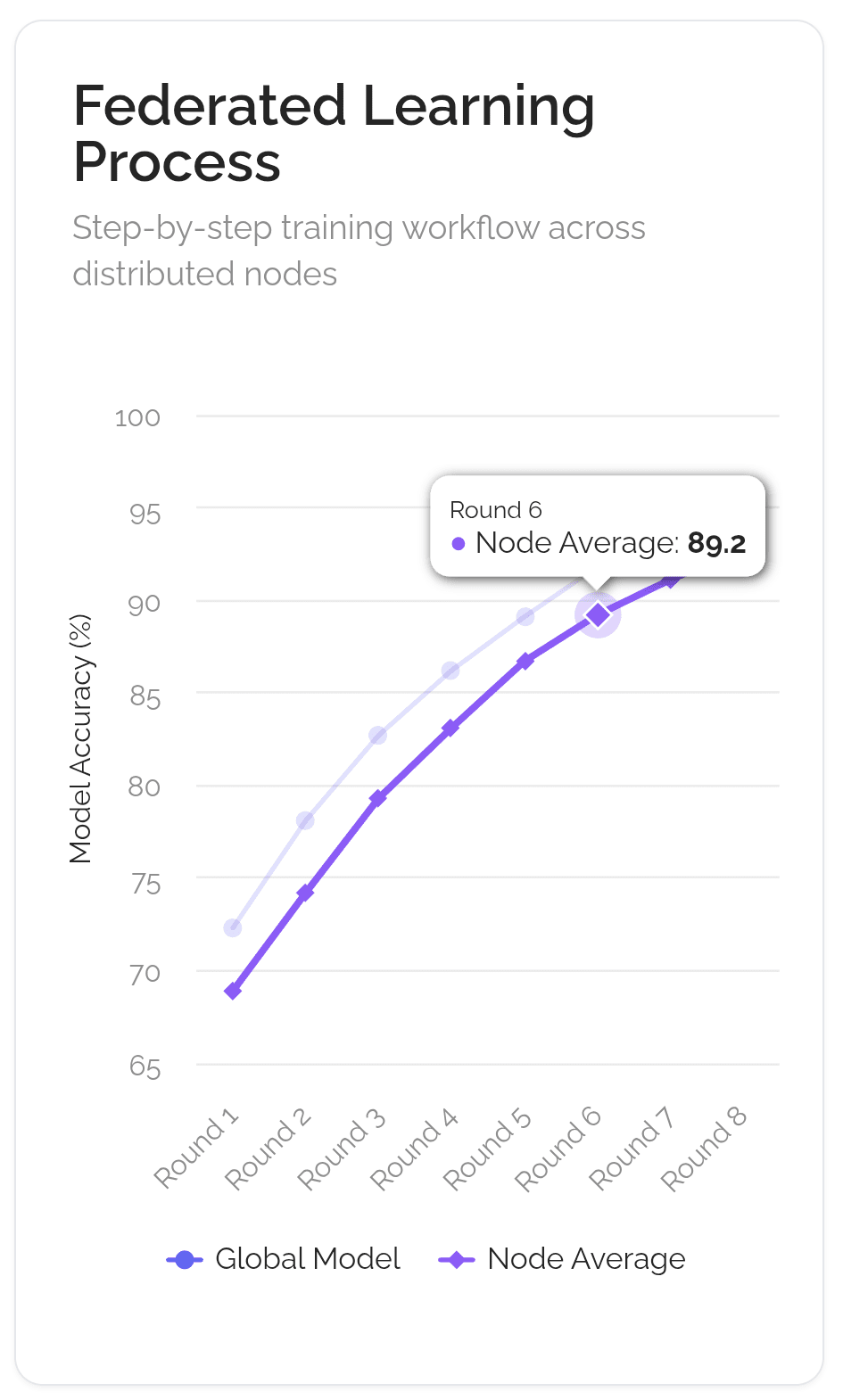
Das Hauptrezept (das "globale Modell") wird an Tausende von lokalen Köchen auf der ganzen Welt gesendet. Jeder Koch probiert das Rezept in seiner eigenen Küche aus, mit seinen einzigartigen lokalen Zutaten und Methoden ("lokale Daten"). Sie teilen ihre geheimen Zutaten nicht; sie machen nur Notizen, wie sie das Rezept verbessern können ("Modellaktualisierungen"). Diese Notizen werden zurück zum Clubhauptquartier gesendet. Der Club kombiniert dann alle Notizen, um ein neues, verbessertes Hauptrezept zu erstellen, das für die nächste Runde versendet wird. Das Ganze wird von einer transparenten, automatisierten Clubsatzung (der "Blockchain") verwaltet, die sicherstellt, dass jeder Koch, der hilft, Anerkennung und eine faire Belohnung erhält ("Token-Belohnungen").
❍ Schlüsselmechanismen
Diese Analogie entspricht eng dem technischen Arbeitsablauf, der diese Art von kollaborativem Training ermöglicht. Es ist eine komplexe Angelegenheit, aber sie reduziert sich auf einige Schlüsselmechanismen, die alles möglich machen.
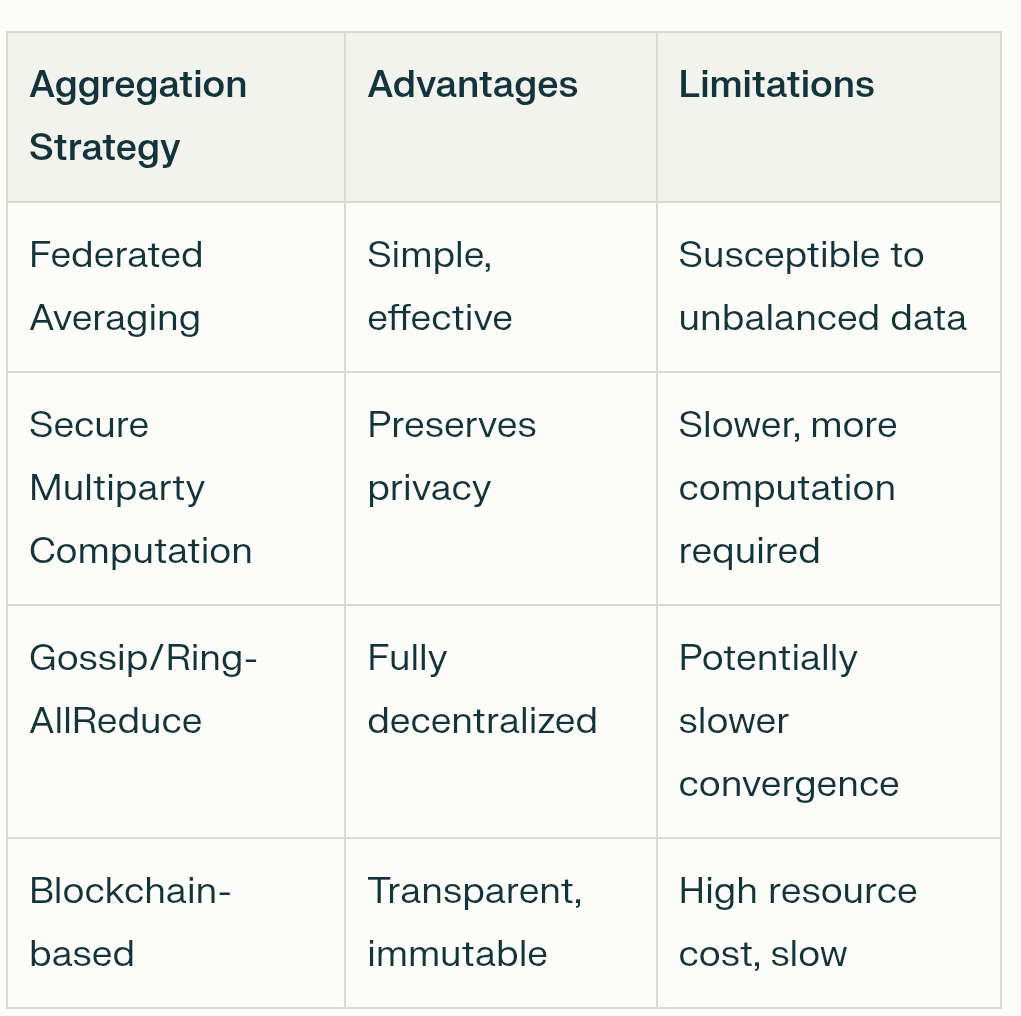
Verteilte Datenparallelität: Dies ist der Ausgangspunkt. Anstatt dass ein riesiger Computer einen riesigen Datensatz verarbeitet, wird der Datensatz in kleinere Stücke aufgeteilt und über viele verschiedene Computer (Knoten) im Netzwerk verteilt. Jeder dieser Knoten erhält eine vollständige Kopie des KI-Modells, mit dem er arbeiten kann. Dies ermöglicht eine enorme Menge an paralleler Verarbeitung, die die Dinge dramatisch beschleunigt. Jeder Knoten trainiert seine Modellkopie mit seinem einzigartigen Datenausschnitt.
Low-Communication-Algorithmen: Eine große Herausforderung besteht darin, all diese Modellkopien synchron zu halten, ohne das Internet zu verstopfen. Wenn jeder Knoten ständig jede kleine Aktualisierung an jeden anderen Knoten senden müsste, wäre das unglaublich langsam und ineffizient. Hier kommen Low-Communication-Algorithmen ins Spiel. Techniken wie DiLoCo (Distributed Low-Communication) ermöglichen es Knoten, Hunderte von lokalen Trainingsschritten für sich selbst durchzuführen, bevor sie ihren Fortschritt mit dem breiteren Netzwerk synchronisieren müssen. Neuere Methoden wie NoLoCo (No-all-reduce Low-Communication) gehen noch weiter und ersetzen massive Gruppensynchronisationen durch eine "Gossip"-Methode, bei der Knoten ihre Aktualisierungen nur regelmäßig mit einem einzigen, zufällig ausgewählten Peer im Durchschnitt bilden.
Kompression: Um die Kommunikationslast weiter zu reduzieren, verwenden Netzwerke Kompressionstechniken. Das ist wie das Komprimieren einer Datei, bevor man sie per E-Mail verschickt. Modellaktualisierungen, die einfach große Listen von Zahlen sind, können komprimiert werden, um sie kleiner und schneller zu versenden. Quantisierung beispielsweise reduziert die Genauigkeit dieser Zahlen (zum Beispiel von einem 32-Bit-Gleitkommawert auf einen 8-Bit-Ganzzahlwert), was die Datenmenge um den Faktor vier oder mehr mit minimalen Auswirkungen auf die Genauigkeit verringern kann. Pruning ist eine weitere Methode, die unwichtige Verbindungen im Modell entfernt, wodurch es kleiner und effizienter wird.
Anreiz und Validierung: In einem vertrauenslosen Netzwerk muss sichergestellt werden, dass alle fair spielen und für ihre Arbeit belohnt werden. Dies ist die Aufgabe der Blockchain und ihrer Token-Ökonomie. Smart Contracts fungieren als automatisierte Treuhand, die Token-Belohnungen an Teilnehmer verteilt, die nützliche Rechenleistung oder Daten beitragen. Um Betrug zu verhindern, verwenden Netzwerke Validierungsmechanismen. Dies kann beinhalten, dass Validierer zufällig einen kleinen Teil der Berechnung eines Knotens erneut ausführen, um ihre Richtigkeit zu überprüfen, oder kryptografische Beweise verwenden, um die Integrität der Ergebnisse sicherzustellen. Dies schafft ein System des "Proof-of-Intelligence", bei dem wertvolle Beiträge verifizierbar belohnt werden.
Fehlertoleranz: Dezentrale Netzwerke bestehen aus unzuverlässigen, global verteilten Computern. Knoten können jederzeit offline gehen. Das System muss in der Lage sein, dies zu bewältigen, ohne dass der gesamte Trainingsprozess abstürzt. Hier kommt die Fehlertoleranz ins Spiel. Frameworks wie Prime Intellects ElasticDeviceMesh ermöglichen es Knoten, dynamisch an einem Training teilzunehmen oder es zu verlassen, ohne eine systemweite Ausfall zu verursachen. Techniken wie asynchrone Checkpoints speichern regelmäßig den Fortschritt des Modells, sodass das Netzwerk schnell vom zuletzt gespeicherten Zustand wiederhergestellt werden kann, falls ein Knoten ausfällt, anstatt von Grund auf neu zu starten.
Dieser kontinuierliche, iterative Arbeitsablauf verändert grundlegend, was ein KI-Modell ist. Es ist kein statisches Objekt mehr, das von einem Unternehmen erstellt und besessen wird. Es wird zu einem lebenden System, einem Konsenszustand, der ständig von einem globalen Kollektiv verfeinert wird. Das Modell ist kein Produkt; es ist ein Protokoll, das kollektiv von seinem Netzwerk gewartet und gesichert wird.
IV. Dezentrale Trainingsprotokolle
Der theoretische Rahmen der dezentralen KI wird jetzt von einer wachsenden Anzahl innovativer Projekte implementiert, von denen jedes eine einzigartige Strategie und technischen Ansatz verfolgt. Diese Protokolle schaffen eine wettbewerbsorientierte Arena, in der verschiedene Modelle von Zusammenarbeit, Verifizierung und Anreizsetzung im großen Maßstab getestet werden.
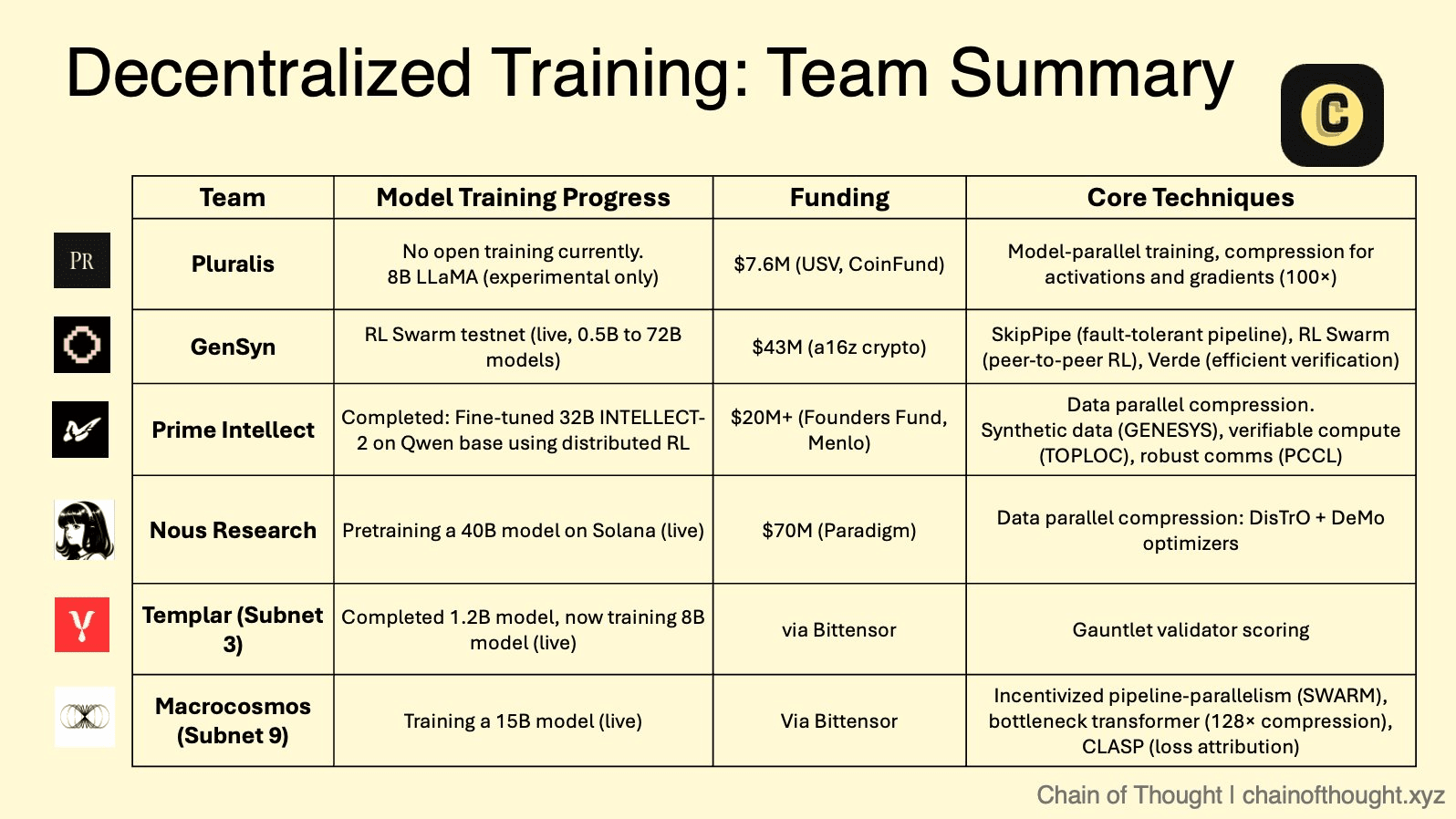
❍ Der modulare Marktplatz: Bittensors Subnetz-Ökosystem
Bittensor operiert als ein "Internet der digitalen Waren", ein Meta-Protokoll, das zahlreiche spezialisierte "Subnets" beherbergt. Jedes Subnetz ist ein wettbewerbsorientierter, anreizgetriebener Markt für eine spezifische KI-Aufgabe, von der Textgenerierung bis zur Protein-Faltung. Innerhalb dieses Ökosystems sind zwei Subnetze besonders relevant für das dezentrale Training.

Templar (Subnetz 3) konzentriert sich darauf, eine genehmigungsfreie und antifragile Plattform für dezentrales Vortraining zu schaffen. Es verkörpert einen reinen, wettbewerbsorientierten Ansatz, bei dem Miner Modelle trainieren (derzeit bis zu 8 Milliarden Parameter, mit einem Fahrplan in Richtung 70 Milliarden) und basierend auf der Leistung belohnt werden, was einen unaufhörlichen Wettlauf zur Herstellung der bestmöglichen Intelligenz antreibt.

Macrocosmos (Subnetz 9) stellt eine erhebliche Evolution mit seiner IOTA (Incentivised Orchestrated Training Architecture) dar. IOTA geht über isolierte Konkurrenz hinaus und fördert orchestrierte Zusammenarbeit. Es verwendet eine Hub-and-Spoke-Architektur, bei der ein Orchestrator das Daten- und Pipeline-parallele Training über ein Netzwerk von Minern koordiniert. Anstatt dass jeder Miner ein ganzes Modell trainiert, werden ihnen spezifische Schichten eines viel größeren Modells zugewiesen. Diese Arbeitsteilung ermöglicht es dem Kollektiv, Modelle in einem Umfang zu trainieren, der weit über die Kapazität eines einzelnen Teilnehmers hinausgeht. Validierer führen "Schattensichtprüfungen" durch, um die Arbeit zu überprüfen, und ein detailliertes Anreizsystem belohnt die Beiträge fair und fördert eine kollaborative, aber rechenschaftspflichtige Umgebung.
❍ Die verifiable Compute-Schicht: Gensyns vertrauensloses Netzwerk
Gensyns Hauptaugenmerk liegt darauf, eines der schwierigsten Probleme im Bereich zu lösen: verifizierbares maschinelles Lernen. Ihr Protokoll, das als benutzerdefinierter Ethereum L2 Rollup entwickelt wurde, ist darauf ausgelegt, kryptografische Nachweise für die Korrektheit von tiefen Lernberechnungen, die auf unzuverlässigen Knoten durchgeführt werden, bereitzustellen.

Eine wichtige Innovation aus Gensyns Forschung ist NoLoCo (No-all-reduce Low-Communication), eine neuartige Optimierungsmethode für das verteilte Training. Traditionelle Methoden erfordern einen globalen "all-reduce"-Synchronisierungsschritt, der einen Engpass schafft, insbesondere in Netzwerken mit niedriger Bandbreite. NoLoCo beseitigt diesen Schritt vollständig. Stattdessen verwendet es ein gossip-basiertes Protokoll, bei dem Knoten regelmäßig ihre Modellgewichte mit einem einzelnen, zufällig ausgewählten Peer im Durchschnitt bilden. Dies, kombiniert mit einem modifizierten Nesterov-Momentum-Optimierer und zufälliger Aktivierungsweiterleitung, ermöglicht es dem Netzwerk, effizient ohne globale Synchronisierung zu konvergieren, was es ideal für das Training über heterogene, internetverbundene Hardware macht. Gensyns RL Swarm-Testnetzanwendung demonstriert diesen Stack in Aktion und ermöglicht kollaboratives Verstärkungslernen in einem dezentralen Umfeld.
❍ Der globale Rechenaggregator: Prime Intellects offenes Framework
Prime Intellect entwickelt ein Peer-to-Peer-Protokoll, um globale Rechenressourcen in einem einheitlichen Marktplatz zu aggregieren und effektiv ein "Airbnb für Berechnungen" zu schaffen. Ihr PRIME-Framework ist für fehlertolerantes, leistungsstarkes Training in einem Netzwerk von unzuverlässigen und global verteilten Arbeitern konzipiert.
Das Framework basiert auf einer angepassten Version des DiLoCo (Distributed Low-Communication)-Algorithmus, der es Knoten ermöglicht, viele lokale Trainingsschritte durchzuführen, bevor eine weniger häufige globale Synchronisierung erforderlich ist. Prime Intellect hat dies mit bedeutenden technischen Durchbrüchen ergänzt. Das ElasticDeviceMesh ermöglicht es Knoten, dynamisch an einem Training teilzunehmen oder es zu verlassen, ohne das System zum Absturz zu bringen. Asynchrone Checkpoints in RAM-unterstützten Dateisystemen minimieren Ausfallzeiten. Schließlich entwickelten sie benutzerdefinierte int8 all-reduce-Kerne, die die Kommunikationslast während der Synchronisierung um den Faktor vier reduzieren und so die Bandbreitenanforderungen drastisch senken. Dieser robuste technische Stack ermöglichte es ihnen, das weltweit erste dezentrale Training eines Modells mit 10 Milliarden Parametern, INTELLECT-1, erfolgreich zu orchestrieren.
❍ Das Open-Source-Kollektiv: Nous Researchs gemeinschaftsgetriebener Ansatz
Nous Research fungiert als ein dezentrales KI-Forschungskollektiv mit einem starken Open-Source-Ethos und baut seine Infrastruktur auf der Solana-Blockchain auf, die für ihre hohe Durchsatzrate und niedrigen Transaktionskosten bekannt ist.
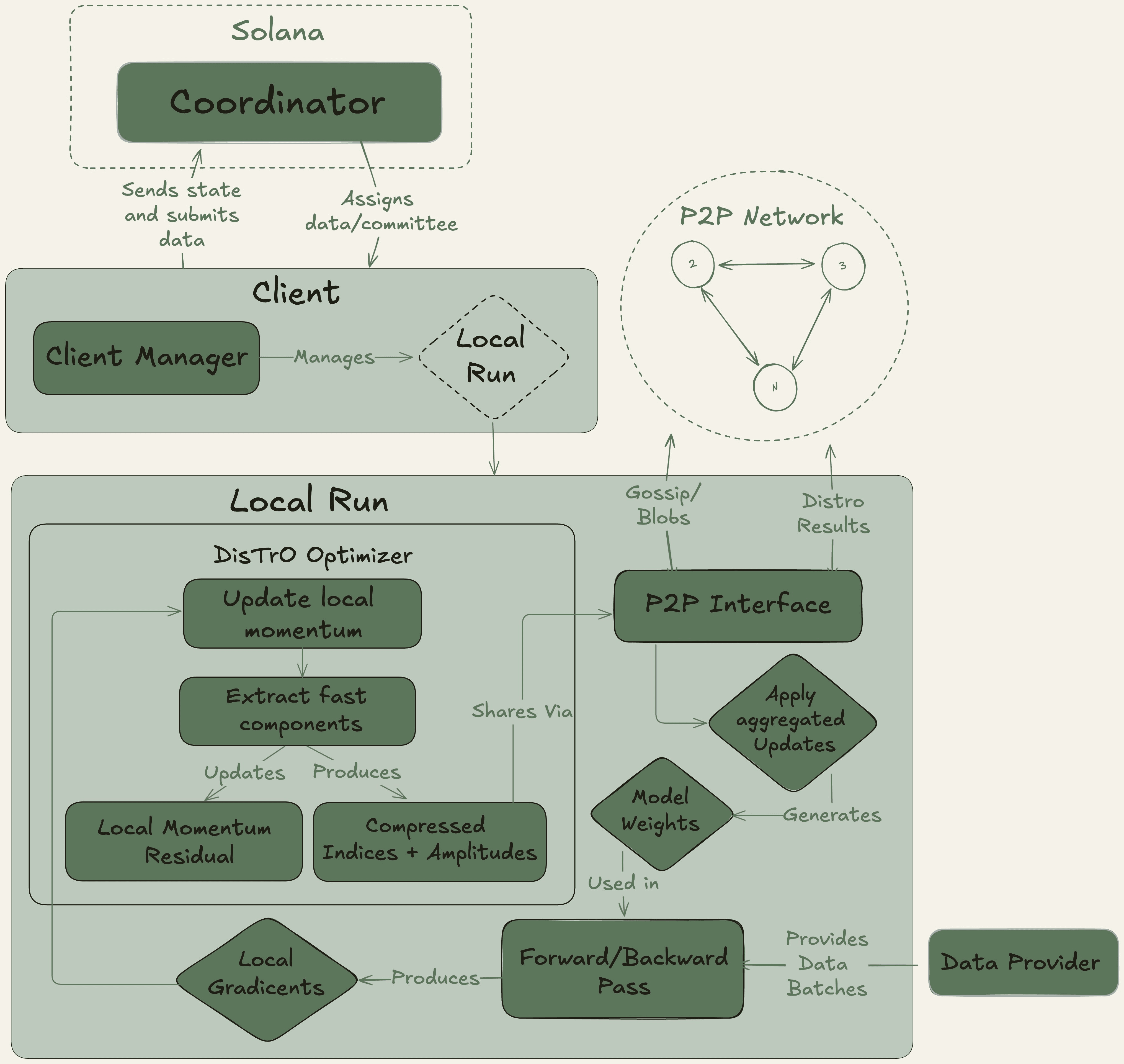
Ihre Hauptplattform, Nous Psyche, ist ein dezerniertes Trainingsnetzwerk, das von zwei Kerntechnologien betrieben wird: DisTrO (Distributed Training Over-the-Internet) und seinem zugrunde liegenden Optimierungsalgorithmus, DeMo (Decoupled Momentum Optimization). Entwickelt in Zusammenarbeit mit einem Mitbegründer von OpenAI, sind diese Technologien für extreme Bandbreiteneffizienz ausgelegt und beanspruchen eine Reduzierung von 1.000x bis 10.000x im Vergleich zu herkömmlichen Methoden. Dieser Durchbruch macht es möglich, an großangelegtem Modelltraining mit handelsüblichen GPUs und Standard-Internetverbindungen teilzunehmen, wodurch der Zugang zur KI-Entwicklung radikal demokratisiert wird.
❍ Die pluralistische Zukunft: Pluralis AIs Protokoll-Lernen
Pluralis AI geht eine höherstufige Herausforderung an: nicht nur, wie man Modelle trainiert, sondern wie man sie mit vielfältigen und pluralistischen menschlichen Werten auf eine datenschutzfreundliche Weise in Einklang bringt.

Ihr PluralLLM-Framework führt einen auf föderiertem Lernen basierenden Ansatz zur Präferenzabgleichung ein, eine Aufgabe, die traditionell von zentralisierten Methoden wie Reinforcement Learning from Human Feedback (RLHF) durchgeführt wird. Mit PluralLLM können verschiedene Benutzergruppen ein Präferenzprognosemodell gemeinsam trainieren, ohne jemals ihre sensiblen, zugrunde liegenden Präferenzdaten zu teilen. Das Framework verwendet föderierte Durchschnittswerte, um diese Präferenzaktualisierungen zu aggregieren, was schnellere Konvergenz und bessere Abstimmungswerte als zentralisierte Methoden ermöglicht und gleichzeitig sowohl Datenschutz als auch Fairness wahrt.
Ihr übergreifendes Konzept des Protokoll-Lernens stellt weiter sicher, dass kein einzelner Teilnehmer das vollständige Modell erhalten kann, wodurch kritische Fragen des geistigen Eigentums und des Vertrauens, die bei der kollaborativen KI-Entwicklung bestehen, gelöst werden.
Während die Arena des dezentralen KI-Trainings eine vielversprechende Zukunft birgt, ist ihr Weg zur breiten Akzeptanz mit erheblichen Herausforderungen verbunden. Die technische Komplexität des Managements und der Synchronisierung von Berechnungen über Tausende unzuverlässiger Knoten bleibt ein gewaltiges ingenieurtechnisches Hindernis. Darüber hinaus schafft der Mangel an klaren rechtlichen und regulatorischen Rahmenbedingungen für dezentrale autonome Systeme und kollektiv besessenes geistiges Eigentum Unsicherheit für Entwickler und Investoren gleichermaßen.
Letztendlich müssen diese Netzwerke, um langfristige Lebensfähigkeit zu erreichen, über Spekulation hinauswachsen und echte, zahlende Kunden für ihre Rechenleistungen gewinnen, wodurch nachhaltige, protokollgesteuerte Einnahmen generiert werden. Und wir glauben, dass sie am Ende die Straße überqueren werden, noch bevor unsere Spekulationen eintreten.