
Plasma is not just another blockchain name in the market. It is a serious infrastructure layer built with one clear focus: stablecoin performance and high-reliability RPC services. When we talk about digital payments, cross-border transfers, or on-chain financial applications, the biggest problems are usually speed, cost, sync stability, and network reliability. Plasma is designed to solve exactly these issues at the infrastructure level.
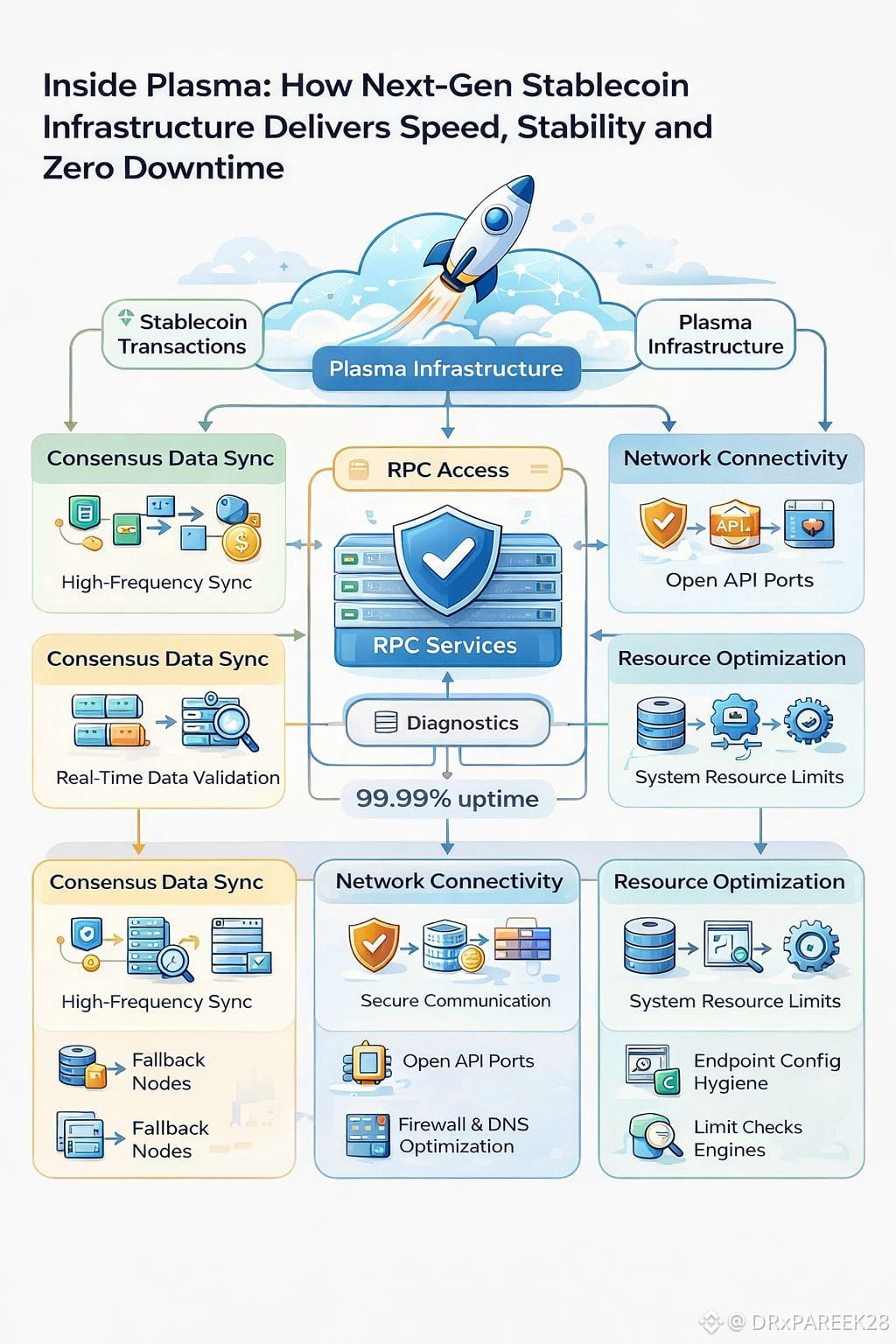
At its core, Plasma supports non-validator nodes that power RPC services for applications. These nodes are responsible for serving transaction data, balances, and blockchain state to wallets, exchanges, and payment apps. If these nodes are slow or unstable, the entire user experience suffers. That is why Plasma gives strong importance to synchronization, network connectivity, resource optimization, and configuration hygiene.
One of the most important areas in Plasma infrastructure is synchronization. If a node lags behind the network head, applications will receive outdated data. Plasma documentation clearly highlights that system load plays a major role here. CPU, memory, and disk I/O must be strong enough to handle high-frequency block production. If your database queries are slow or there is lock contention, the node cannot apply consensus state quickly. Even small delays in consensus endpoint latency can directly impact block ingestion speed. This is why monitoring block height versus network head, state application time per block, and latency to each consensus endpoint becomes critical.
Another common issue is complete sync stall. Many teams panic when syncing suddenly stops, but Plasma gives a very practical approach. First check disk space because full disks immediately halt database writes. Then verify endpoint connectivity and ensure DNS resolution, firewall rules, and routing are not blocking consensus traffic. Container resource limits also matter. If CPU or memory allocation is insufficient, the sync process may crash silently. Plasma specifically advises checking endpoint reachability, JWT token validity, allowlist status, and non-validator node version compatibility. These small configuration details can completely stop your node if ignored.
Network connectivity is another backbone of Plasma’s reliability. Required ports must be open for both consensus communication and RPC serving to applications. Many times, corporate firewalls, cloud security groups, or misconfigured iptables rules become hidden blockers. It is not only about opening ports; it is also about verifying outbound traffic permissions for consensus sync. Inside container environments, port reachability must be tested from both outside and inside the container to avoid surprises in production.
DNS failures may look small, but in distributed systems they break synchronization quickly. If consensus domains cannot resolve properly, the node cannot maintain sync. Plasma recommends confirming DNS resolution for all service domains, monitoring resolver latency, and adding fallback resolvers when required. In high-availability infrastructure, even a few seconds of DNS delay can reduce data freshness for RPC consumers.
Proxy and NAT environments add another layer of complexity. VPNs, proxies, and NAT rules can interfere with inbound RPC access or consensus sync. Proxy authentication rules must be validated carefully, and proper NAT port forwarding must be configured for inbound RPC traffic. Without correct routing, the node may appear online but actually remain unreachable for real traffic.
Configuration errors are also very common in real deployments. Incorrect consensus endpoints, malformed URLs, wrong JWT tokens, deprecated flags, or chain ID mismatches can prevent nodes from even starting. Plasma strongly encourages checking logs for configuration parse errors and unknown flags. Observability is treated as a first-class requirement. Log analysis helps track sync progress, RPC errors, consensus connectivity, and resource-related crashes. Increasing file descriptor limits through ulimit, systemd, or container runtime configs is also recommended to avoid unexpected failures under load.
Poor peer connectivity can reduce data freshness significantly. If connections to consensus endpoints are limited or unstable, block arrival lag increases. Monitoring active connections, disconnect rate, and failover behavior across multiple endpoints helps maintain performance. Plasma promotes maintaining baselines and tracking changes after upgrades or configuration modifications. This professional approach prevents silent performance degradation.
What makes Plasma powerful is not only its technology but its systematic troubleshooting mindset. It clearly states that most issues come from system resource limits, network connectivity problems, or misconfiguration. Instead of guessing, operators are encouraged to begin with basic health checks. This disciplined approach ensures stable RPC availability, reliable access to stablecoin transaction data, and high uptime for applications built on top.
In today’s digital economy, stablecoin infrastructure must be fast, secure, and always available. Plasma is positioning itself as a specialized backbone for that mission. It focuses on performance tuning, sync reliability, container optimization, network transparency, and clear diagnostics. For developers, it means predictable APIs. For businesses, it means reliable transaction data. For infrastructure teams, it means structured troubleshooting with measurable metrics.
Plasma is not about hype. It is about building strong backend foundations for stablecoin ecosystems. When infrastructure is stable, innovation becomes easy. And when RPC reliability is high, user trust automatically increases. That is the real power of Plasma in the evolving blockchain infrastructure landscape.

