Geschrieben von Qubic Scientific Team

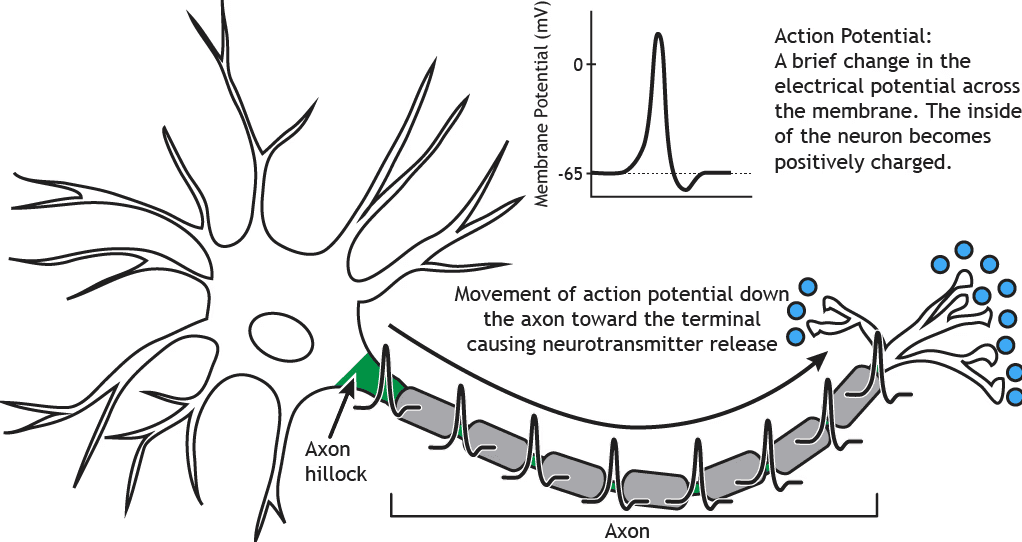
Das Gehirn ist dynamisch und nicht-binär
Biologische Gehirnnetzwerke funktionieren nicht als Entscheidungsschalter zwischen Aktivierung und Ruhe. In lebenden Systemen impliziert Inaktivität selbst Dynamik. Absolute "Ruhe" wäre mit dem Leben unvereinbar. Wie wir im ersten Kapitel gesehen haben, entfaltet sich das Leben in der Zeit.
Ein einzelnes Neuron kann als ein Alles-oder-Nichts-Ereignis erscheinen, das elektrischen Strom an ein anderes Neuron überträgt, um es zu hemmen oder zu erregen. Vor dieser Übertragung erhält das Neuron jedoch kontinuierlich positive und negative Eingaben in einem Bereich, der Dendriten genannt wird. Wenn die globale Summe dieser Eingaben einen bestimmten Schwellenwert überschreitet, tritt eine physikalische konformationale Veränderung auf, und der elektrische Strom breitet sich entlang des Axons zum nächsten Neuron aus. Die meiste Zeit findet die neuronale Verarbeitung unterhalb des Aktionsschwellenwerts statt, wo exzitatorische und inhibitorische Ströme kontinuierlich integriert werden.
In der rechnerischen Neurowissenschaft ist es gut etabliert, dass das Gehirn ein kontinuierliches dynamisches System ist, dessen Zustände sich sogar in Abwesenheit externer Stimuli entwickeln (Deco et al., 2009; Northoff, 2018).
Es gibt keine diskreten Ereignisse oder Rücksetzungen im Gehirn. Jeder externe Stimulus wirkt auf ein lebendes System, das bereits eine vorherige Konfiguration hat. Ein Stimulus kann einen erregenden oder hemmenden Zustand beeinflussen, aber niemals einen statischen. Es ist wie ein Ball auf einem Fußballfeld: die gleiche Bahn löst unterschiedliche Ergebnisse aus, abhängig von den dynamischen Positionen der Spieler. Mit einem identischen Pfad kann das Spiel scheitern oder zu einem entscheidenden Assist werden.
Die Mechanismen, die Neuronen unabhängig von unmittelbaren Stimuli aktiv halten, sind gut bekannt.
Einer davon besteht aus subthreshold Eingaben, die das Membranpotential verändern, ohne ein Aktionspotential zu erzeugen.
Andere umfassen stille Synapsen und dendritische Dornen, die latente Konnektivität zwischen Neuronen bewahren oder lokale Aktivierung fördern.
Der wichtigste Mechanismus betrifft metabotrope Rezeptoren, die mit Neurotransmittern verbunden sind, die den Kontext organisieren. Sie bestimmen nicht direkt, ob ein Aktionspotential ausgelöst wird. Stattdessen definieren sie, was relevant oder nicht relevant ist, welche Belohnungsvorhersage ein Stimulus trägt, welches Maß an Wachsamkeit oder Gefahr vorhanden ist, wie viel Neuheit im System existiert, welches Maß an nachhaltiger Aufmerksamkeit erforderlich ist, welches Gleichgewicht zwischen Exploration und Ausbeutung angemessen ist, was kodiert und was vergessen werden sollte, wie der interne Zustand reguliert wird und wann Impulskontrolle oder zeitliche Stabilität vorteilhaft ist.
Mit anderen Worten, metabotrope Rezeptoren implementieren eine Form von weisem Metakontroll. Sie sind keine Daten, sondern Parameter! Sie fungieren als dynamische Variablen, die das Verhalten des Systems anpassen. Sie ermöglichen es dem System, empfindlich auf die funktionale Bedeutung einer Situation (Neuheit, Relevanz, Belohnung oder Bedrohung) zu reagieren, ohne sofortige Antworten zu erfordern.
Zurück zur Fußballmetapher entsprechen metabotrope Rezeptoren den Teamtaktiken: zu entscheiden, wann man angreift oder verteidigt, das heißt, zu entscheiden, wie das Spiel gespielt wird.
Aus einer rechnerischen Perspektive operieren diese Mechanismen durch Zwischenzustände. Sie sind nicht binär (aktiv/inaktiv). Das System arbeitet in drei Modi: erregend, hemmend und ein Zwischenzustand, der keine unmittelbare Ausgabe produziert, aber zukünftige Dynamiken moduliert.
Wenn wir von Ternär in biologischen Gehirnnetzwerken sprechen, beziehen wir uns nicht auf eine mathematische Abstraktion oder Kalkül, sondern auf eine wörtliche funktionale Beschreibung, wie das Gehirn über Zeit das Gleichgewicht aufrechterhält.
Aus diesem Grund studiert die rechnerische Neurowissenschaft nicht primär Eingangs-Ausgangs-Zuordnungen, sondern vielmehr, wie sich Zustände kontinuierlich reorganisieren. Diese Zustände sind grundsätzlich prädiktiv in ihrer Natur (Friston, 2010; Deco et al., 2009).
LLMs sind binäre Berechnungen.
In großen Sprachmodellen macht das Konzept der Ternarität keinen Sinn. Lernen basiert grundsätzlich auf Fehler-Rückpropagation. Das heißt, sobald die Größe des Fehlers im Verhältnis zu den erwarteten Daten bekannt ist, passt ein Optimierungsalgorithmus die Parameter mithilfe eines externen Signals an.
Wie funktioniert das? Das Modell produziert eine Ausgabe, zum Beispiel die Vorhersage des wahrscheinlichsten nächsten Wortes: "Paris ist die Hauptstadt von ...". Wenn die Antwort Finnland ist, wird dies mit dem richtigen Wort aus dem Trainingssatz (Frankreich) verglichen. Aus diesem Vergleich wird ein numerischer Fehler berechnet. Dieser Fehler quantifiziert, wie weit die Vorhersage vom erwarteten Wert abweicht. Der Fehler wird dann in einen Gradienten umgewandelt, nämlich ein mathematisches Signal, das angibt, in welche Richtung und um wie viel die Parameter des Modells angepasst werden sollten, um den Fehler zu verringern. Die Gewichte werden nur rückwärts aktualisiert, nachdem die Ausgabe produziert und bewertet wurde.
Der Fehler wird a posteriori berechnet, die Gewichte werden so angepasst, dass die richtige Antwort Frankreich wird, und das System nimmt den Betrieb wieder auf, als ob nichts geschehen wäre.
In großen Sprachmodellen ist die Trennung zwischen Dynamik und Lernen besonders ausgeprägt. Während der Inferenz bleiben die Parameter fix; es gibt keine Online-Plastizität, keine Gewöhnung, keine Ermüdung und keine zeitabhängige Anpassung. Das System verändert sich nicht, indem es aktiv ist.
In der Fußballmetapher ähneln LLMs einem Trainer, der nach dem Spiel Fehler überprüft und Taktiken für das nächste anpasst. Aber während des Spiels selbst spielt das Team die vollen neunzig Minuten ohne Möglichkeit technischer oder taktischer Anpassungen!
Es gibt eine Strategie vor dem Spiel und eine Korrektur nach dem Spiel, aber keine Dynamik während des Spiels!
LLMs sind daher nicht ternär in einem funktionalen Sinne. Sie sind Matrizen von „Aufmerksamkeit“ (Transformatoren), die offline trainiert wurden (Vaswani et al., 2017). Dies ist keine quantitative Einschränkung, sondern ein ontologischer Unterschied.
Neuraxon und Aigarth ternäre Dynamik
Neuraxon führt ein grundlegend anderes Konzept ein. Seine grundlegende Einheit ist keine Eingangs-Ausgangsfunktion, wie bei LLMs, sondern ein interner kontinuierlicher Zustand, der sich über die Zeit entwickelt. In Neuraxon wird Erregung als +1 dargestellt, Hemmung als −1, und zwischen diesen beiden Zuständen gibt es einen neutralen Bereich, der durch 0 dargestellt wird.
In jedem Moment integriert das System den Einfluss aktueller Eingaben, der jüngsten Geschichte und interner Mechanismen, um eine diskrete trinomial Ausgabe (Erregung, Hemmung oder Neutralität) zu erzeugen.
Die Beziehung zwischen Zeit und Ternär ist zentral. Der neutrale Zustand stellt nicht die Abwesenheit von Berechnung oder Inaktivität dar, sondern eine subthreshold Phase, in der das System Einfluss ansammelt, ohne sofortige Ausgaben zu produzieren. Es ist vergleichbar mit einem dynamischen taktischen Wechsel in einem Fußballteam, unabhängig davon, ob es zu einem Tor für oder gegen führt.
Aigarth drückt dieselbe Logik auf struktureller Ebene aus. Nicht nur sind die Einheiten selbst ternär, sondern das Netzwerk kann wachsen, reorganisieren oder kollabieren, je nach seiner Nützlichkeit, und führt eine evolutionäre Dimension ein, die kontinuierliche Anpassung verstärkt. Die Kombination aus Neuraxon und Aigarth (Mikro-Makro) führt zu rechnerischen Geweben, die aktiv bleiben können (Intelligenz-Gewebe-Einheiten), was für Architekturen, die ausschließlich auf Rückpropagation basieren, unmöglich ist.
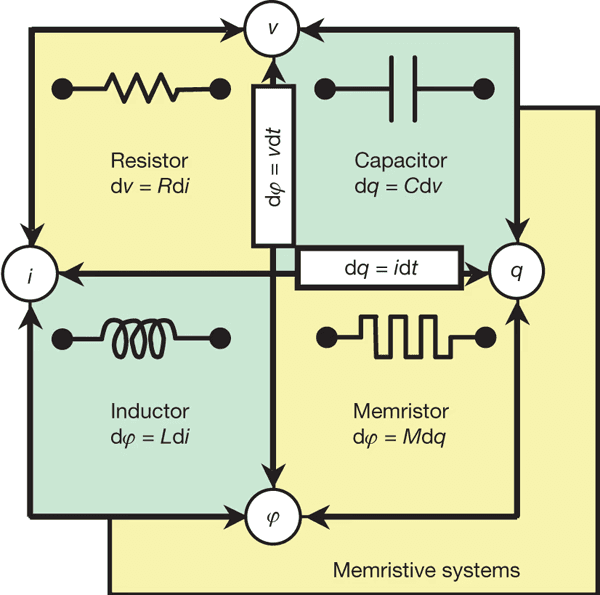
Die Hardware-Frage kann nicht ignoriert werden. Derzeit gibt es keine universelle ternäre Hardware, aber es gibt aktive Forschungsrichtungen in der ternären Logik, einschließlich multivalued Memristors und neuromorphe Berechnung basierend auf resistiven oder spintronischen Geräten (Yang et al., 2013; Indiveri & Liu, 2015). Diese Ansätze zielen darauf ab, den Energieverbrauch zu reduzieren und, was noch wichtiger ist, ternäre Berechnung im Einklang mit physischen, lebenden und kontinuierlichen Dynamiken zu erreichen.
Macht eine ternäre Architektur auch ohne dedizierte ternäre Hardware Sinn? Trotz dieser Einschränkung tut sie das, denn Architektur steht vor physischem Substrat. Durch die Gestaltung ternärer Systeme offenbaren wir die Unfähigkeit der binären Logik, eine dynamische Welt widerzuspiegeln. Gleichzeitig können ternäre Architekturen wie Neuraxon–Aigarth bereits Verbesserungen auf bestehender binärer Hardware erzielen, indem sie unnötige Aktivität reduzieren.
Referenzen
Deco, G., Jirsa, V. K., Robinson, P. A., Breakspear, M., & Friston, K. J. (2009). Das dynamische Gehirn: Von spikenden Neuronen zu neuronalen Massen und kortikalen Feldern. PLoS Computational Biology, 5(8), e1000092.
Friston, K. (2010). Das Prinzip der freien Energie: Eine einheitliche Gehirntheorie? Nature Reviews Neuroscience, 11(2), 127–138.
Indiveri, G., & Liu, S.-C. (2015). Gedächtnis und Informationsverarbeitung in neuromorphen Systemen. Proceedings of the IEEE, 103(8), 1379–1397.
Northoff, G. (2018). Das spontane Gehirn: Vom Geist-Körper-Problem zu einer Neurophänomenologie. MIT Press.
Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Aufmerksamkeit ist alles, was Sie brauchen. Fortschritte in den Systemen zur Verarbeitung neuronaler Informationen, 30.
Yang, J. J., Strukov, D. B., & Stewart, D. R. (2013). Memristive Geräte für das Rechnen. Nature Nanotechnology, 8(1), 13–24.
\u003ct-120/\u003e\u003ct-121/\u003e