I stumbled across Mira Network the way most new crypto projects show up now, half mentioned in a thread where everyone seems to be arguing about different things at once. What made me stop wasn’t the token or the branding. It was a small line in their own explanation: when you turn verification into a neat, standardized question, you also make it easier to guess.
That’s not something you write unless you’ve spent serious time thinking about incentives and how they fail. The second you reward accuracy, you also give people a reason to look accurate as cheaply as possible. And that’s where the clean story starts to crack.
If autonomous AI is the direction we’re moving in, systems that don’t just suggest but actually execute, then accuracy stops being optional. It becomes a cost center. You either pay for validation up front in compute and coordination, or you pay later when mistakes surface without warning and without refunds.
Mira seems built around that tension. It doesn’t treat correctness as a default setting. It treats it as something that has to be funded and enforced.
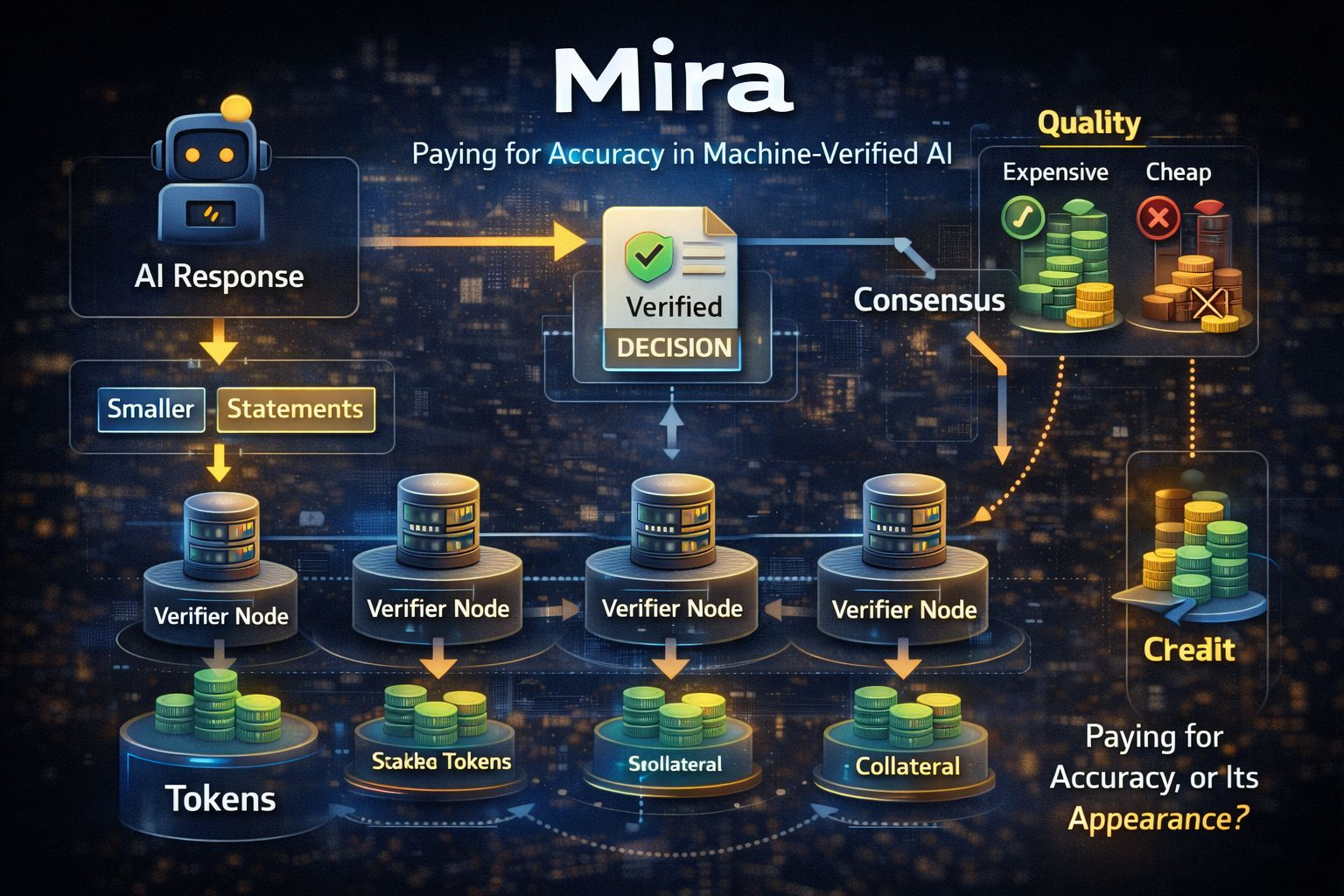
The outline is straightforward, even if the mechanics aren’t. An AI produces an answer. Mira breaks that answer into smaller claims that can be checked. Those claims are sent to multiple independent verifiers, models run by different operators. Their responses are compared. If enough of them agree, the system returns the answer along with proof that consensus was reached.
On the surface, it sounds like a more bureaucratic chatbot. Not just an answer, but an answer with paperwork attached.
In reality, the paperwork is the product.
When humans leave the loop, trust doesn’t disappear. It relocates. Instead of trusting a person, you trust a process. Instead of trusting one model, you trust a collection of them. What Mira is really offering is a record you can point to later, especially when someone asks why an automated system made a certain decision.
It does carry a compliance flavor, and that makes sense. AI is no longer just drafting emails. It’s wired into systems where mistakes have real consequences. A chatbot inventing a policy detail is irritating. An automated agent misreading a contract or freezing the wrong account is something else entirely. That’s operational risk.
What makes it worse is how clean those mistakes look in real time. The output sounds calm and certain. Nothing in the tone hints at doubt. You only discover the flaw after the action has already been taken, when fixing it costs more than preventing it would have.
So the question shifts. It’s no longer “can the model do this?” It’s “how do we stop it from being confidently wrong?”
Mira’s technical roots suggest that concern came first. A late 2024 paper on ensemble validation showed that combining two or three models can push accuracy from the low seventies into the nineties. After that, the gains taper off. But the paper is blunt about the tradeoffs. More models mean more compute, more latency, and more structured prompts to keep comparisons workable.
Reliability can be improved. It just isn’t free.
That’s where crypto comes in, not as branding, but as infrastructure for incentives. If independent operators are running verification models, they’re paying real costs. Hardware, API calls, maintenance. They need compensation. At the same time, the network has to assume someone will eventually look for shortcuts.
So the uncomfortable problem surfaces: how do you know a verifier actually did the work?
In proof of work systems, you can see the computation. In AI verification, you can’t. If a model answers a multiple choice check correctly, you don’t know whether it reasoned carefully or guessed. With four options, random guessing still hits 25 percent of the time. Over enough attempts, even sloppy behavior can look profitable unless the system makes that strategy expensive.
Mira’s answer is staking and penalties. Verifiers lock up collateral. If they repeatedly diverge from the network’s consensus or behave in suspicious patterns, they risk losing that stake. The idea is to make guessing a losing game over time.
But here’s the harder truth: agreement isn’t the same as correctness.
If most verifiers share similar blind spots, which models often do, they can align around the same wrong answer. If prompts subtly guide them toward a certain framing, they can converge just like students who all misread a question and circle the same option. In that case, penalties enforce conformity, not truth.
So Mira’s real reliability depends on diversity. Not cosmetic variety, but meaningful differences in models, training data, and failure patterns. If the verifier set is genuinely varied, consensus carries weight. If it’s mostly the same system under different labels, consensus becomes amplification.
There’s also the question of Mira verifying itself. A network built on the promise of scrutiny eventually has to accept scrutiny. Audits, disclosures, operational transparency. Some monitoring pages suggest that widely advertised assurances aren’t always as visible as outsiders might expect. That doesn’t prove anything is wrong. It does highlight how fragile the word “verified” can be when applied to your own infrastructure.
Growth metrics add another layer. Millions of users. Billions of tokens processed. Huge query counts. Impressive, maybe. But metrics like that blur easily. A “user” might not be a unique individual. “Tokens processed” can spike for technical reasons. “Queries” might include everything from critical checks to minor background calls.
The real question isn’t how busy the network looks. It’s whether it meaningfully reduces risk where mistakes are expensive.
And then there’s cost. Multi model verification adds compute and delay. In finance, insurance, or legal settings, that surcharge can make sense. In consumer apps, it’s harder to justify. Reliability only matters if someone keeps paying for it.
That’s where the token has to do real work. It secures the network through staking. It incentivizes operators. It sets a price for verification that developers are willing to absorb. If fees are too high, usage drops. If rewards are too low, quality drops. If staking is too strict, participation narrows. If it’s too loose, shortcuts become rational.
There’s no permanent equilibrium. It’s ongoing calibration.
Strip away the branding, and Mira is essentially proposing this: correctness is an expense you choose to bear upfront. You don’t just trust a single model’s answer. You run it through a defined verification process and keep the receipt.
That could be genuinely valuable. It could also slide into ritual, a certificate that looks reassuring without changing much underneath.
If it works, it will feel boring. Developers will route high stakes decisions through it because it’s cheaper than cleaning up errors. The token will fade into the background. The API will quietly do its job.
If it doesn’t, the failure won’t be dramatic. It will be gradual. Operators optimizing for rewards. Developers lowering thresholds to save money. Consensus standing in for truth. Certificates everywhere, meaning less than they appear to.
From the outside, both scenarios might look like progress. More autonomous agents. More verified decisions. More activity.
The real difference is harder to see. Are teams actually buying accuracy, or just the appearance of it?
That’s the tension Mira is trying to formalize. Not intelligence. Not automation. Just the costly, unglamorous work of being right when it matters.
@Mira - Trust Layer of AI #Mira $MIRA
