Große Sprachmodelle können Gedichte schreiben und Code schreiben, haben aber oft Probleme mit Grundschulmathematik? Dieses Dilemma wurde endlich überwunden.
Kürzlich sah ich eine erstaunliche Aktion: Ein Forscher hat es geschafft, einen WASM (WebAssembly) Interpreter verlustfrei in die Modellgewichte des Transformers „einzubetten“!
Es ist nicht nur so einfach, dass „Modelle Werkzeuge verwenden“, sondern es läuft tatsächlich ein echter Computer direkt innerhalb des LLM.
💡Kernlogik: Eine hybride Architektur wie ein DSP-Chip, ähnlich der DSP-Architektur von TI:
Neuronale Netzwerke (ARM): Verantwortlich für logisches Denken, semantisches Verständnis und Sprachorganisation.
Eingebetteter Interpreter (DSP): Zuständig für hochpräzise, hochgeschwindigkeitsbeständige Berechnungen.
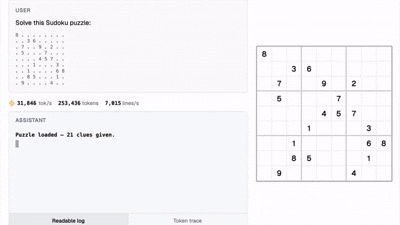
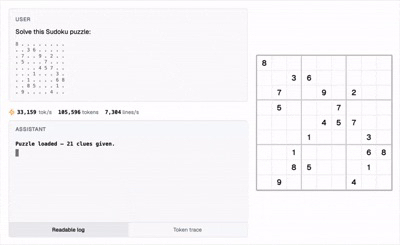
Wenn LLM auf das Problem stößt, ob 3.11 oder 3.8 größer ist, verlässt es sich nicht mehr auf das "Intuition"-Raten des nächsten Tokens, sondern ruft direkt die interne Rechenmaschine auf.
🚀Warum ist das wichtig?
100 % Genauigkeit: Selbst die schwierigsten Sudoku können in Sekundenschnelle gelöst werden, wodurch Berechnungsillusionen vollständig beseitigt werden.
Millionen Schritte Ausführung: Programme können Millionen Schritte im Modell intern ausführen, die Leistung ist überwältigend.
Anwendungen in allen Bereichen: Physiksimulation, Finanzmodellierung, kryptografische Berechnungen... Diese Bereiche, die extrem hohe Genauigkeit erfordern, kann LLM endlich wirklich erfüllen.
Es ist nicht mehr nur "generative KI", es ist "native computing KI". Die Menschheit ist einen Schritt näher an echter allgemeiner künstlicher Intelligenz (AGI)!
#KI #LLM #WebAssembly #Transformer #DeepLearning #AGI