

Okay, hier ist die Sache.
Du versuchst, Daten zu erstellen, die nachweisbar, tragbar und tatsächlich über völlig unterschiedliche Systeme nutzbar sind. Klingt einfach, wenn du es schnell sagst. Ist es nicht. Überhaupt nicht.
Im Mittelpunkt davon stehen die Bestätigungen. Das ist die Kernidee. Du nimmst eine Behauptung, strukturierst sie richtig, signierst sie und machst sie überprüfbar.
Fertig.... Das ist das Fundament, auf dem alles andere aufbaut.
Aber ehrlich gesagt sind die Speicheroptionen der Punkt, an dem sich das alles real anfühlt.
Du kannst die gesamten Daten on-chain ablegen, wenn du maximalen Vertrauen möchtest.
Sauber. Keine Mehrdeutigkeit. Auch... teuer. Also, schmerzhaft teuer, wenn du das in großem Maßstab machst. Oder du gehst den anderen Weg, verankerst einfach einen Hash on-chain und hältst die tatsächlichen Daten irgendwo off-chain, wie Arweave. Viel günstiger. Immer noch verifizierbar. Oder du mischst beides, je nachdem, worauf du Wert legst.
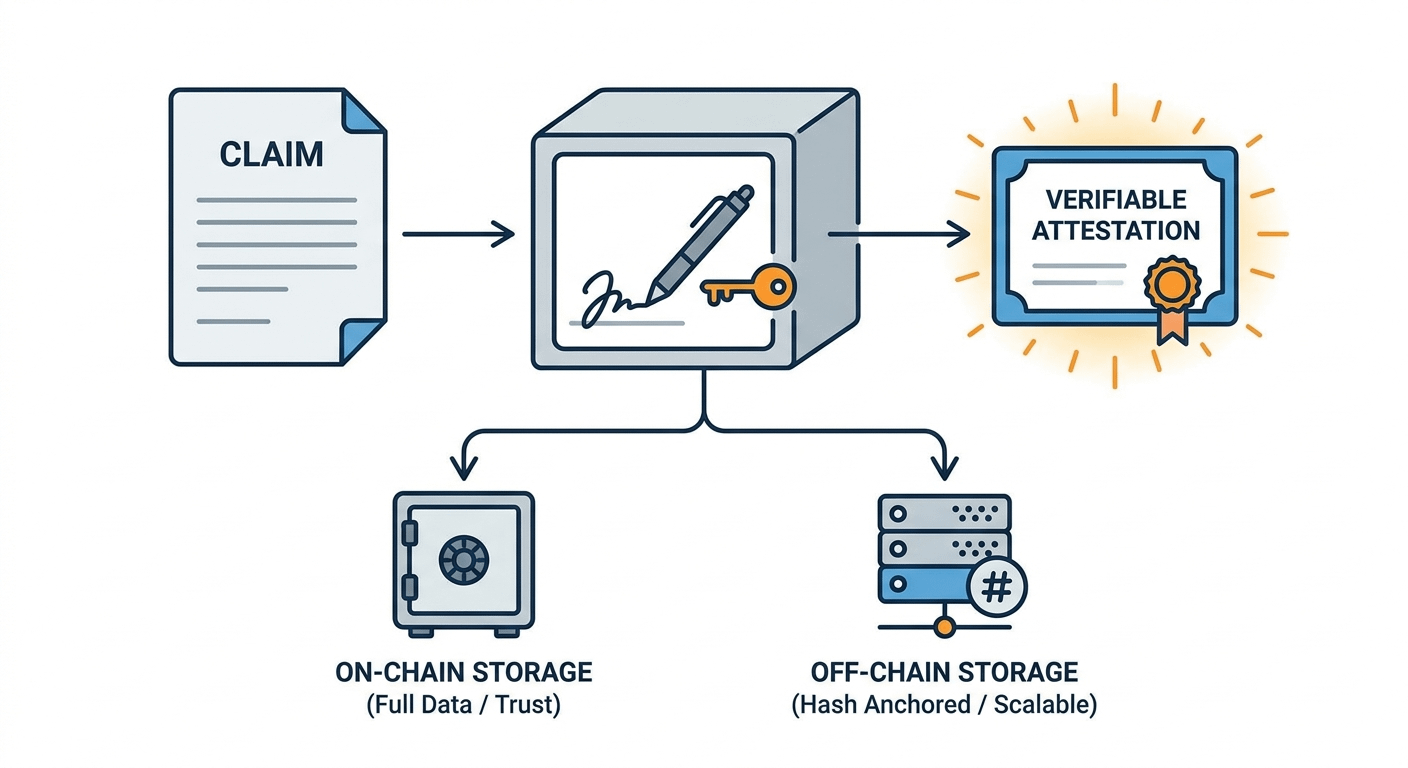
Diese Flexibilität ist wichtiger, als die Leute zugeben.
Dann hast du Schemata, die alles zusammenhalten. Und ja, „Schemata“ klingt langweilig. Ist es nicht. Sie sind im Grunde gemeinsame Vorlagen, auf die sich jeder im Voraus über die Struktur einigt, und plötzlich schreibst du nicht immer wieder die gleiche Validierungslogik über verschiedene Ketten hinweg neu.
Ich habe das getan. Zu oft. Es ist eine Verschwendung.
Das behebt das.
Unter der Haube verwenden sie asymmetrische Kryptografie und Zero-Knowledge-Beweise. Das bedeutet, du musst keine Rohdaten offenlegen. Du beweist einfach etwas darüber.
Wie, du kannst beweisen, dass du über 18 bist, ohne deinen Ausweis zu zeigen.
Das ist die Art von Dingen, die offensichtlich klingt, sobald man sie hört, aber es ist tatsächlich ein großes Ding.
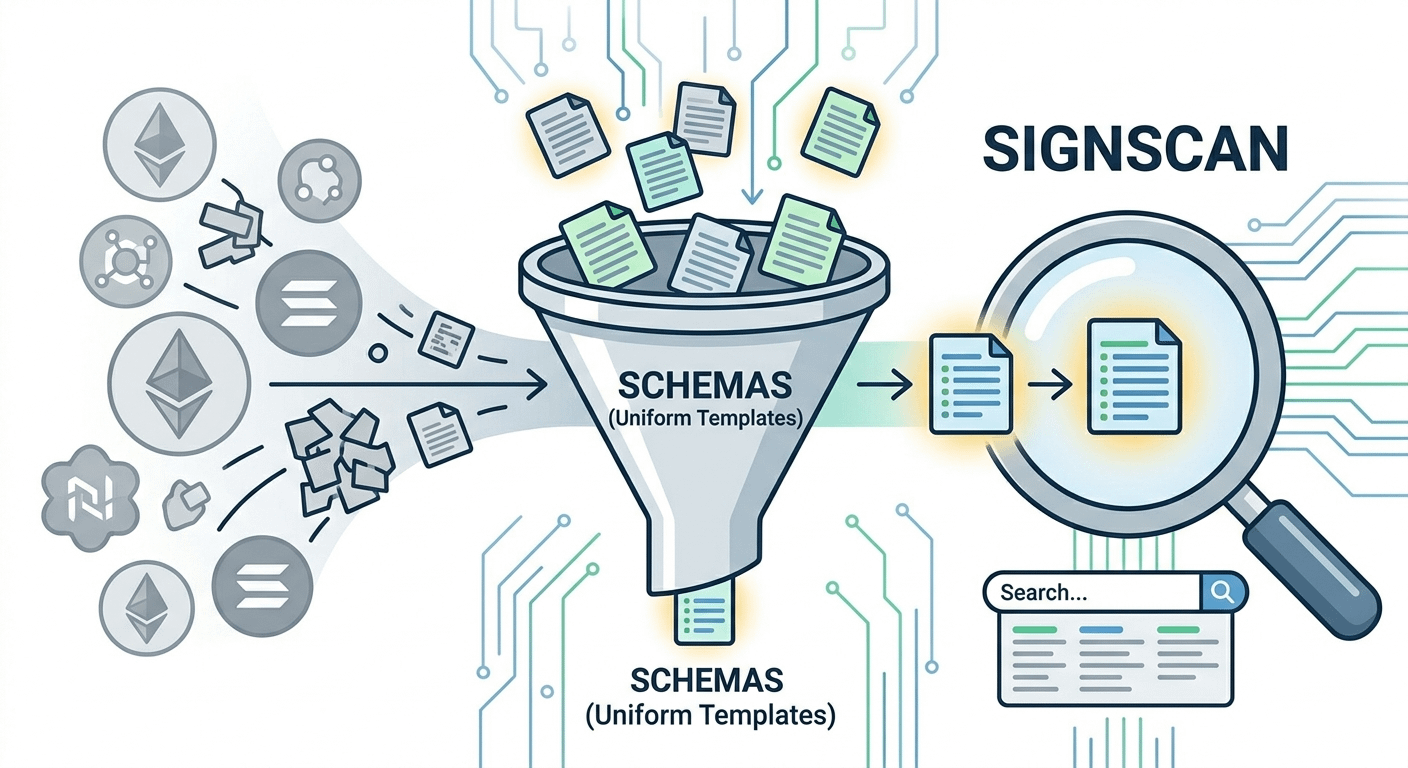
Und dann gibt es SignScan. Das hat mich einen Moment innehalten lassen. Es ist im Grunde ein Explorer für Bestätigungen über Ketten hinweg. Ein Ort. Alles abfragen.
Warum gab es das nicht früher?
Im Ernst. Anstatt deine eigenen Indexer zu bauen oder APIs zusammenzuflicken, die jede zweite Woche brechen, greifst du einfach eine Schicht an und machst weiter. Das allein spart eine Menge Ingenieurzeit.
Aber lass uns über den Teil sprechen, der mir im Kopf herumgeht.
Das Cross-Chain-Verifikationssetup. Das mit Lit Protocol und TEEs.
Denn hier fallen die Dinge normalerweise auseinander.
Brücken?
Chaotisch.....
Orakel?
Auch chaotisch. Alles, was versucht, „Wahrheit“ zwischen Ketten zu bewegen, tendiert dazu, entweder zu stark zu zentralisieren oder unter Druck zu brechen. Ich habe gesehen, dass dies mehr als einmal passiert ist.
Also hat mich ihr Ansatz aufmerksam gemacht.
Hier ist, wie ich es verstehe.
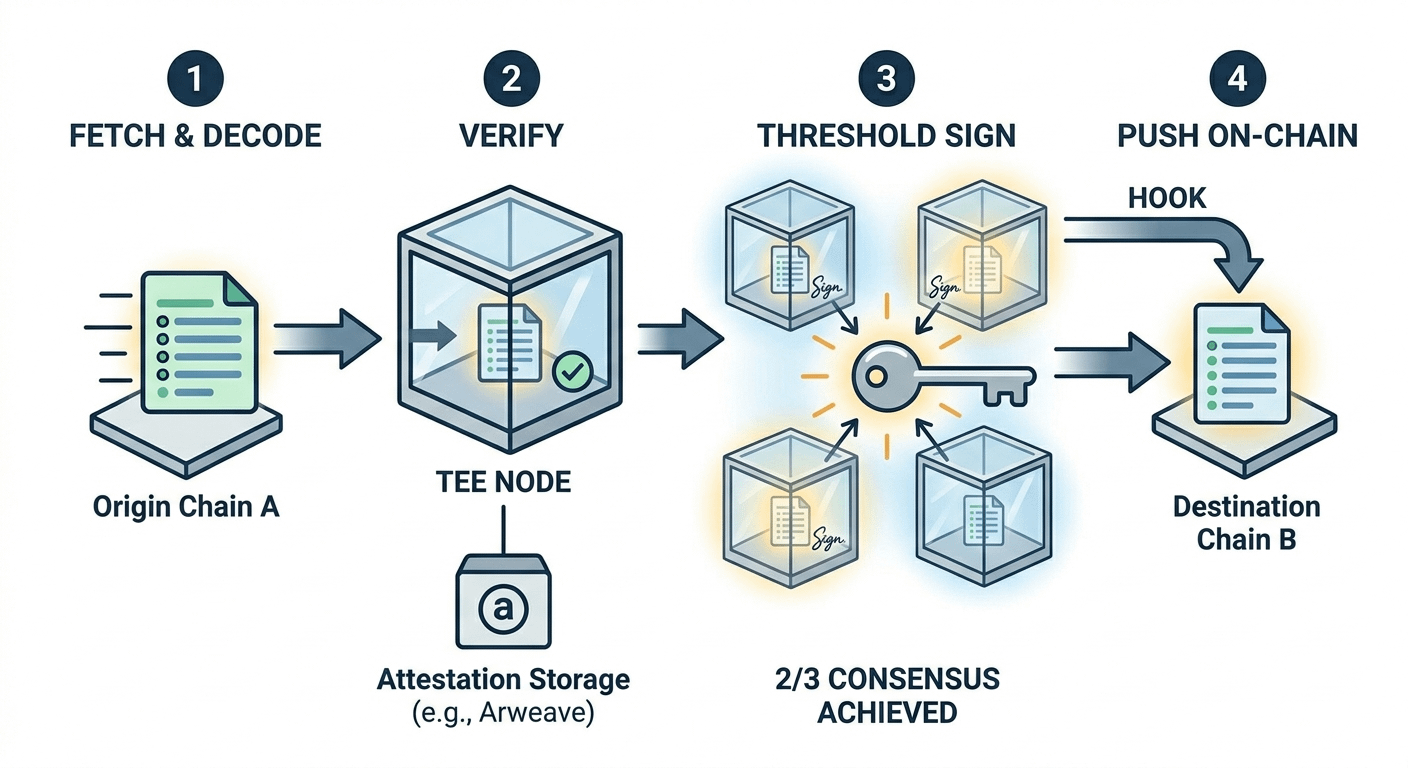
Du hast TEE-Knoten, vertrauenswürdige Ausführungsumgebungen. Denk an versiegelte Boxen. Code läuft darin, niemand mischt sich ein, und du vertraust dem Output, weil die Box selbst abgeschlossen ist.
Jetzt skaliere das. Du verlässt dich nicht auf eine Box. Du hast ein Netzwerk von ihnen.
Wenn Chain B etwas von Chain A verifizieren möchte, tritt einer dieser Knoten ein. Er erfasst Metadaten, dekodiert sie, zieht die tatsächliche Bestätigung (vielleicht von Arweave, vielleicht von woanders) und verifiziert sie.
Dann kommt der wichtige Teil.
Es genehmigt es, aber nicht allein.
Du brauchst einen Schwellenwert. Etwa zwei Drittel des Netzwerks müssen zustimmen, bevor diese Signatur irgendetwas bedeutet. Sobald sie diesen Schwellenwert erreichen, aggregieren sie die Signatur und schieben sie über einen Hook zurück on-chain zur Zielkette.
Also ja, der Fluss sieht so aus:
abrufen → dekodieren → verifizieren → Schwellenwertsignatur → on-chain pushen
Es ist eine Pipeline. Sauber auf Papier.
Und ich werde ehrlich sein, ich bin beeindruckt. Und ein wenig unbehaglich.
Denn ja, es ist verteilt. Es vermeidet einen einzelnen Relayer. Es stützt sich auf tatsächliche kryptografische Garantien anstelle von Vertrau mir, Bro-Setups. Das ist solide Technik.
Aber... es gibt viele bewegliche Teile.
Was passiert, wenn ein Schritt verzögert?
Oder eine Datenquelle verlangsamt sich?
Oder ändert eine Kette ihre Kodierung und niemand aktualisiert den Parser auf der anderen Seite?
Das sind die Dinge, über die die Leute nicht genug sprechen.
Du koordinierst Systeme, die kaum zu Standards übereinstimmen. Und jetzt erwartest du, dass sie sich unter Last sauber synchronisieren?
Hier wird es knifflig.
Vor allem haben sie Signchain, ihr eigenes L2. Basierend auf dem OP-Stack, der Celestia für die Datenverfügbarkeit nutzt. Nichts Wildes hier. Das ist das Standardhandbuch: Berechnungen außerhalb der Kette verlagern, Kosten senken, die Dinge skalierbar halten.
Es funktioniert. Punkt.
Sie haben über eine Million Bestätigungen durch das Testnetz geschoben. Hunderttausende von Nutzern auch. Das ist nicht klein. Es zeigt, dass das System etwas Druck bewältigen kann.
Aber lass uns realistisch sein.
Testnetze wehren sich nicht.
Mainnets tun das.
Hier zeigen sich die Randfälle. Hier schmerzt die Latenz. Hier brechen Annahmen auf Weisen, die niemand geplant hat.
Trotzdem... ich mag, was ich sehe.
Es steckt echtes Denken dahinter. Tatsächliche Kompromisse. Nicht nur Hype oder vage Versprechungen. Jemand hat sich hingesetzt und die schwierigen Teile durchgearbeitet.
Ich frage mich nur, was passiert, wenn die Dinge seltsam werden.
Weil sie das immer tun.
Wir werden sehen.
#SignDigitalSovereignInfra @SignOfficial $SIGN
