

Ich habe heute Morgen zwei Anmeldeinformationen verglichen und etwas stimmte nicht überein.
Die gleichen Felder.
Die gleiche Struktur.
Verschiedene Schema-IDs.
Ich habe die erste überprüft.
Gültig. Aussteller aktiv. Alles löst sich sauber auf.
Ich habe die zweite überprüft.
Das gleiche Ergebnis.
Beide bestanden.
Beide sahen identisch aus.
Also habe ich etwas Einfaches versucht.
Ich habe eine Überprüfung gegen die erste Schema-ID mit den zweiten Anmeldeinformationen durchgeführt.
Nichts kam zurück.
Kein Fehler.
Einfach nichts.
Ich habe die Registrierungsadressen überprüft.
Verschieden.
Die gleiche Struktur wurde zweimal registriert.
Durch zwei verschiedene Adressen.
Zwei Schema-IDs.
Zunächst dachte ich, ich hätte Duplikate gezogen.
Also habe ich jeden einzelnen zurück zu seiner Registrierung verfolgt.
Sie waren keine Duplikate.
Es waren separate Registrierungen.
Die gleichen Felder.
Die gleiche beabsichtigte Struktur.
Völlig unabhängig.
Ich musste zurückgehen und überprüfen, ob ich nichts Offensichtliches übersehen hatte.
Das fühlte sich nicht richtig an.
Weil von außen nichts sie voneinander trennte.
Die gleichen Daten.
Das gleiche Format.
Gleiches Verhalten innerhalb ihres eigenen Schemas.
Aber ein Prüfer, der gegen eine Schema-ID überprüft, würde nie ein unter dem anderen ausgestelltes Anmeldeinformationen erkennen.
Ich habe länger daran geblieben, als ich wollte.
Überprüft, wie viele Anmeldeinformationen unter jedem Schema existierten.
Keine kleine Zahl.
Zwei Populationen.
Ausgestellt unter Schemata, die identisch aussahen.
Nicht in der Lage, gegenseitig zu verifizieren.
Das fühlte sich nicht richtig an.
Das ist der Punkt, an dem ich aufhörte anzunehmen, dass dies nur ein Duplikat war.
Für einen Moment dachte ich, das sei ein einmaliger Registrierungsfehler.
Dann habe ich ein weiteres Paar überprüft.
Das gleiche Muster.
Das war der Moment, in dem es klickte.
Schema-Fork.
Zwei unabhängige Populationen von Anmeldeinformationen.
Identische Struktur.
Verschiedener Registrant.
Andere ID.
Keine Brücke zwischen ihnen.
Von außen sind sie nicht unterscheidbar. Von innen hat die Verifizierungsschicht sie nie getroffen.
Ich habe weitergemacht.
Ich wollte sehen, wo das tatsächlich auftauchte.
Der erste Ort, an dem ich es bemerkte, war der Zugang.
Der Prüfer benötigte nie den Inhalt.
Das Schema war ausreichend.
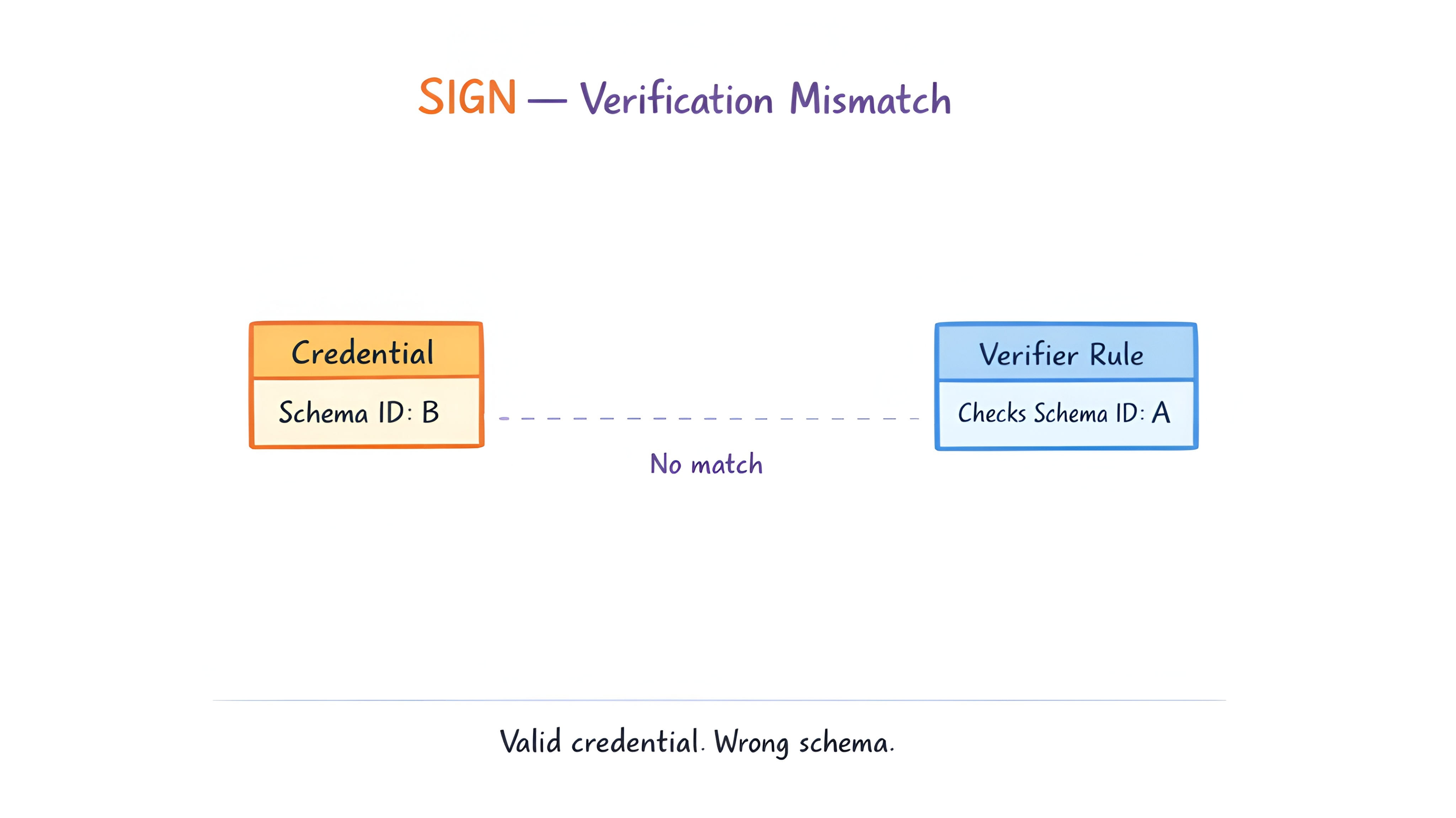
Und die Entscheidung geschah trotzdem.
Eine Bedingung überprüft gegen eine Schema-ID.
Ein unter dem anderen ausgestelltes Anmeldeinformationen registriert sich nicht.
Nicht weil es falsch ist.
Weil der Prüfer einen anderen Fork liest.
Die Entscheidung geschieht trotzdem.
Nur gegen die halbe Sicht.
Das blieb.
Dann Verteilung.
Eine Verteilung, die durch schema-spezifische Bestätigungen gesteuert wird, läuft sauber.
Eine Population besteht.
Der andere erscheint nicht einmal.
Nicht absichtlich ausgeschlossen.
Einfach... nicht gesehen.
Die Anmeldeinformationen existieren.
Das überprüfte Schema ist einfach nicht das ihre.
Konnte es nicht ignorieren.
Dann Vertrauen.
Zwei Aussteller, die auf das gleiche Schema hin arbeiten.
Die gleichen Felder.
Gleiche Absicht.
Ein Aussteller erkennt ein Anmeldeinformationen sofort.
Der andere führt die gleiche Überprüfung durch und erhält nichts zurück.
Beide denken, sie arbeiten nach dem gleichen Standard.
Sie sind es nicht.
Sie haben ohne es zu merken geforkt.
Einer akzeptiert.
Einer lehnt ab.
Gleiche Anmeldeinformationen.
Anderes Ergebnis.
Ich habe danach noch ein paar weitere Schema-Registrierungen überprüft.
Suchte nach strukturellem Überschneidungen zwischen verschiedenen Registranten.
Das Muster trat häufiger auf, als ich erwartet hatte.
Nicht überall.
Aber genug.
Besonders dort, wo mehrere Aussteller auf denselben Anwendungsfall hinarbeiteten.
Das war der Moment, in dem es nicht mehr wie ein Registrierungsfehler fühlte.
Und begann, wie ein strukturelles Muster auszusehen.
$SIGN hier nur dann von Bedeutung, wenn zwei Schemata mit identischer Struktur, aber unterschiedlichen Registranten als äquivalent von der Verifizierungsschicht erkannt werden können, ohne dass eine der Seiten von Grund auf neu aufbauen muss.
Weil der Fork im Moment still ist.
Nichts in der Bestätigung sagt dir, welche Population du ansiehst.
Und jede Berechtigungskontrolle, die einen Fork besteht und den anderen verpasst, trifft eine Entscheidung auf der Grundlage unvollständiger Informationen.
Wie viele Inhaber von Anmeldeinformationen scheitern gerade an der Verifizierung, nicht weil ihre Anmeldeinformationen falsch sind... sondern weil der Prüfer einen anderen Fork des gleichen Schemas liest?
#SignDigitalSovereignInfra #Sign
