
Der Ausgangspunkt für diesen Artikel ist ganz einfach: Ich möchte meine Methodik zum Verständnis des Pyth Networks so klar und wiederverwendbar wie möglich darlegen; gleichzeitig möchte ich es in den Kontext der größeren Markt- und institutionellen Anwendungen einordnen. In den letzten Jahren habe ich die Evolution von Orakeln und den Weg zur Datenkommerzialisierung langfristig verfolgt und eine einfache, aber nützliche Einschätzung entwickelt: Was in der Datenversorgungskette wirklich wichtig ist, ist nicht die dekorative 'Dezentralisierung', sondern die vertrauenswürdige Produktion und die verifizierbare Lieferung. Wenn Angebot und Nachfrage auf der Kette in einer überprüfbaren Weise direkt interagieren können, wird es leichter, den Wert stabil zu erfassen.
Hier bei mir ist Pyth nicht "ein weiteres Preisfutterkomponente", sondern eine Produktionslinie für Preisdaten, die von der Quelle bis zur Multi-Chain-Verteilung reicht. Das traditionelle Modell ähnelt mehr einem "Zweitransmitter", bei dem Aggregatoren, Scraper und Zwischenknoten Informationen schichtweise weiterleiten; Verzögerungen, Unsicherheiten und Nicht-Nachverfolgbarkeit werden oft zu einem Nährboden systemischer Risiken. Pyth verwendet ein First-Party-Datenmodell, das es Börsen, Market Makern und professionellen Datenanbietern ermöglicht, direkt on-chain zu signieren und zu veröffentlichen; dann aggregiert, validiert und berechnet Pythnet das Vertrauensintervall und verteilt es bedarfsorientiert an Anwendungen wie Kreditvergabe, Optionen, synthetische Vermögenswerte, Indizes usw. Ich fasse diesen Weg zusammen: Wir sind kein Lautsprecher, sondern bauen eine "verifizierbare Preisproduktionslinie" auf.
Ein, die Obergrenze der Strecke und die realen Bedürfnisse.
Der Wert der Marktdatenbranche kommt von zwei Enden: Auf der einen Seite die Qualität und Zeitnähe der Quelle, auf der anderen Seite die Verwendbarkeit und Kostenempfindlichkeit der Verbraucher. Im traditionellen Finanzwesen sind Datenverteilung und Echtzeitkurse langfristig stabile kostenpflichtige Kategorien; im Übergang zur Krypto-Welt hat sich die Nachfrage nicht geändert, sondern die Anforderungen an "Verifizierbarkeit" und "Programmierung" sind gestiegen. Kreditvergabe- und Clearingstrategien benötigen niedrigere Verzögerungen und stabile Aktualisierungen; die Preisgestaltung von Optionen hängt von vernünftigen Volatilitätsschätzungen ab; synthetische Vermögenswerte erfordern unter hoher Volatilität Preiskonsistenz. Diese Grundbedürfnisse haben eine anhaltende Nachfrage nach hochwertigem Preisfutter geschaffen und sind mein grundlegender Antrieb für kontinuierliche Forschung und Kreation. Pyths Vision, aus DeFi heraus, zielt auf einen breiteren Markt für Datenservices; ich glaube, das ist der "schwierige, aber richtige" Weg.
Zwei, die Umsetzbarkeit von Produkten und Architekturen zerlegen.
Ich habe die Gewohnheit, jedes Datenprodukt in fünf Segmente zu zerlegen: Rohproduktion, vertrauenswürdige Veröffentlichung, Aggregationsprüfung, Verteilung und Abrechnung, Feedback-Optimierung. Bei Pyth stammt die Rohproduktion von erstklassigen Börsen, Market Makern und professionellen Datenanbietern; sie treten als "Herausgeber" on-chain auf, jede Nachricht trägt eine Quellensignatur, was die Nachverfolgbarkeit gewährleistet. Die vertrauenswürdige Veröffentlichung basiert auf Pythnet, führt Duplikatsreduzierung, Reinigung und Zeitstempel-Ausrichtung durch und berechnet das Vertrauensintervall basierend auf Mehrquellen-Daten. Nach der Aggregationsprüfung werden die Preisaktualisierungen über Cross-Chain-Kanäle an die Anwendungen auf den verschiedenen Chains verteilt; das "Abonnement- und Anfrage"-Verfahren ermöglicht es den Nutzern, die Triggerfrequenz basierend auf Kosten- und Zeitpräferenzen zu bestimmen und unnötige Transaktionen und blockchain-basiertes Rauschen zu reduzieren. Dieses Design vereint die beiden scheinbar gegensätzlichen Indikatoren "Geschwindigkeit" und "Robustheit" unter einem einzigen Ingenieurziel. Aus meiner praktischen Erfahrung kann ich sagen, dass Entwickler, solange sie die Feldstruktur, Zeitgenauigkeit und Vertrauensintervalle des Preisobjekts verstehen, die Integration reibungslos abschließen können.
Die folgende Strukturdiagramm zeigt die Schlüsselstellen und verifizierbaren Punkte des Datenflusses von der Quelle zur Anwendung, um die Kommunikation über Details und Grenzen mit dem Team zu erleichtern.
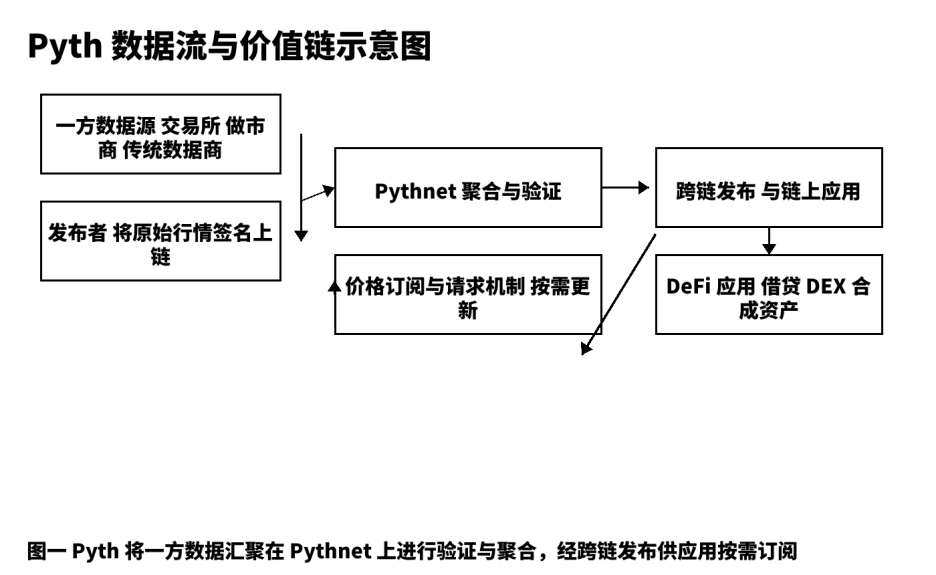
Drei, Fünf-Dimensionen-Vergleich und Strategieauswahl.
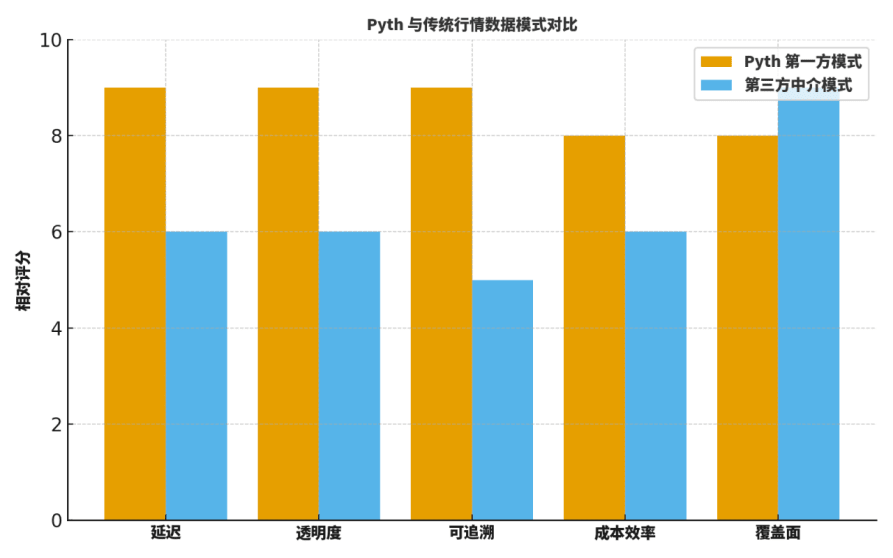
Viele Kollegen fragen: Was sind die Unterschiede zwischen Pyth und traditionellen "vermittelnden Orakeln" oder etablierten Datenanbietern? Ich vergleiche normalerweise aus fünf Dimensionen: Verzögerung, Transparenz, Nachverfolgbarkeit, Kosten-effizienz und Abdeckung.
Erstens, was die Verzögerung betrifft, reduziert der direkte First-Party-Transport signifikant die Zwischenstufen, was sich in schnelleren Aktualisierungen äußert;
Zweitens, was die Transparenz und Nachverfolgbarkeit betrifft, bieten Quellensignaturen und verifizierbare Aggregationsprozesse eine feinkörnige Sichtbarkeit;
Drittens, was die Kosteneffizienz betrifft, entfallen viele externe Abruf- und mehrstufige Weiterleitungskosten;
Viertens, was die Abdeckung betrifft, haben traditionelle Giganten in historischen Kategorien und regionaler Verteilung immer noch Vorteile;
Fünftens, was die Ingenieurzusammenarbeit betrifft, ist Pyths "on-demand subscription" vorteilhaft für die Kopplung mit Risiko-Parametern und Alarmsystemen.
Daher ist die Strategie nicht "einheitsbrei", sondern in entscheidenden Szenarien wird Pyth bevorzugt: Kreditvergabe, Clearing, Optionen, synthetische Vermögenswerte usw. sind die "Musterzimmer", die ich bei der Auswahl am meisten schätze.
Um den Lesern zu helfen, eine Intuition zu entwickeln, gebe ich ein "relatives Bewertungs"-Vergleichsdiagramm, das keine absoluten Schlussfolgerungen ist, aber sehr gut als Ausgangspunkt für Diskussionen und Rückschau-Templates geeignet ist.
Vier, die "zweite Phase" im Fahrplan: institutionelle Datenabonnements.
In der Praxis der Inhaltserstellung und Beratung teile ich den Pyth-Weg in zwei miteinander verbundene Phasen:
In der ersten Phase wird ein Preisfutterstandard im Hochgeschwindigkeitsumfeld von DeFi aufgebaut, wobei Qualität und Geschwindigkeit im Mittelpunkt stehen;
In der zweiten Phase erfolgt die Produktentwicklung für "institutionelle Datenabonnements", einschließlich: Service-Level-Agreements (SLA) für verzögerte Stufen, prüfbare Protokolle, ein Label-System für Risikokontrolle, modulare Abrechnung und Abgleichschnittstellen usw.
Dieser Schritt erweitert die Ingenieursfähigkeiten zu einem Dienstleistungsangebot: Er verbindet Preissignale mit regulatorischen, Compliance- und Risikokontrollfähigkeiten; er verbindet auch "nachhaltige Einnahmen" wirklich mit der Netzwerkgovernance. Ich bin besonders daran interessiert, ob wiederholbare Dienstleistungsmodelle funktionieren können, zum Beispiel:
(1) Bereitstellung von Abonnements mit mehreren Verzögerungen und Aktualisierungsfrequenzen;
(2) Die Quelle, die Signatur, der Zeitstempel und die Liste der beteiligten Aggregatoren jeder Preisaktualisierung können exportiert und nachvollzogen werden;
(3) Auf Risikokontrolle ausgerichtete Anomalielabels, die zurückgespielt, überprüft und mit Risikoevents verknüpft werden können.
Diese Details entscheiden, ob Institutionen bereit sind zu migrieren und wie viel sie bereit sind zu zahlen.
Fünf, Token-Nutzen und wirtschaftlicher Kreislauf.
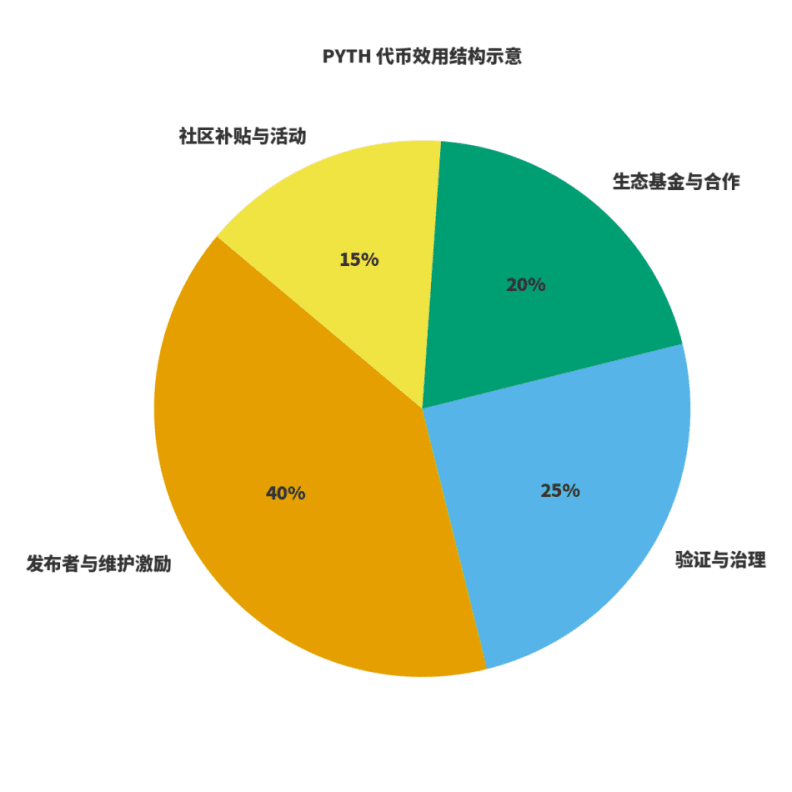
Um zu beurteilen, ob ein Netzwerk gesund ist, muss man zwei Dinge betrachten: Erstens, ob die Einnahmen an die Wertschöpfung gebunden sind; zweitens, ob die Anreize an langfristige Qualität gebunden sind. Für $PYTH verstehe ich es als dreifache Rolle: Brennstoff für die Datenproduktion und -pflege; Gewichtung für Governance und Verifizierung; Hebel für die ökologische Erweiterung. Herausgeber und Pfleger nehmen über vorhersehbare Tokenanreize teil; die Netzwerk Einnahmen stammen aus Datenabonnements und -nutzung, wobei die Governance die Einnahmen zwischen Pflege, Anreizen und ökologischer Erweiterung verteilt. Basierend darauf habe ich eine schematische Darstellung der "Nutzungsverteilung" erstellt, die spezifischen Verhältnisse werden sich mit der Weiterentwicklung der Governance leicht anpassen, aber das Prinzip bleibt gleich: Veröffentlichung und Pflege haben ein hohes Gewicht; Governance und Verifizierung garantieren Stabilität; Ökologie und Gemeinschaft sind verantwortlich für Extern und Kreislauf.
Sechs, eine Umsetzungscheckliste für Institutionen.
Auf Basis früherer Integrations-Erfahrungen habe ich eine Liste erstellt, die direkt verwendet werden kann:
Erstens, die Daten- und Dienstgrenzen klar definieren: Welche gehören zur Basispreisfütterung, welche zur Wertschöpfungsebene;
Zweitens, die Service-Level-Agreements abstimmen: einschließlich Aktualisierungsverzögerung, Stabilität, Anomaliebehandlung, Alarmstrategien und Notfallplänen;
Drittens, eine prüfbare Protokollpipeline bereitstellen: jede Preisaktualisierung, Vertrauensintervalländerungen und Anomalielabels dokumentieren;
Viertens, interne Risikokontroll- und Backtesting-Rahmen integrieren: um den Preisfluss in das Rückspiel-System einzubinden und die Stabilität von Strategien unter verschiedenen Schwellenwerten und Zeitfenstern zu testen;
Fünftens, standardisierte Abrechnung und Abgleich: Institutionen sind mehr an vorhersehbaren Rechnungsfristen und klaren Abrechnungsdetails interessiert.
In dieser Liste ist Pyths offensichtlicher Vorteil die "verifizierbare" Quelle-zu-Aggregation, die die Bewertungszyklen für Compliance und Risikokontrolle erheblich verkürzen kann.
Sieben, Risikokarten und antizykliche Designs.
Ich teile Risiken in drei Kategorien: Anomalien in der Quelle, Anomalien bei der cross-chain-Synchronisation, und Verzögerungsverstärkungen unter extremen Marktbedingungen. Entsprechende Milderungsmaßnahmen müssen im Ingenieurwesen "institutionalisiert" werden. Zu den Methoden, die ich häufig verwende, gehören: Mehrkanal-Abonnements mit Schwellenwertprüfungen; automatisches Herunterfahren von Hebelwirkungen in Verbindung mit Vertrauensintervallen; zeitgewichtete und Slippage-Schutz auf der Handelsvertragsseite; sowie vierteljährliche extreme Marktübungen mit einem einheitlichen Rückspiel-Skript und Überprüfungsvorlagen. Diese disziplinierte Ingenieurpraxis, kombiniert mit Pyths verifizierbarem Protokoll, kann die Druckfestigkeit des Systems erheblich erhöhen.
Acht, narrative Empfehlungen für Inhaltsersteller und Entwickler.
Ich betone immer: Der Wert des Schöpfers besteht darin, den komplexen Ingenieurwert in eine Sprache zu übersetzen, die Leser und Benutzer "verstehen und nutzen können". Wenn es darum geht, Pyth zu erklären, empfehle ich, mit "Paradigmenwechseln" zu beginnen, anstatt in der "Orakel-Debatte" zu verweilen. Erkläre, wie es Angebots- und Nachfrageseiten on-chain auf auditierbare Weise in Einklang bringt; erkläre, wie es durch Vertrauensintervalle und visuelle Aggregationsprozesse das Tail-Risiko senkt; erkläre, wie es durch "institutionelle Abonnements" die Dienstleistungsfähigkeiten und den geschäftlichen Kreislauf verbindet. Das ist überzeugender als einfach nur Indikatoren aufzulisten.
Neun, die Kennzahlen, die ich im kommenden Jahr verfolgen werde.
Erstens, die Breite und Tiefe des Zugangs zur Ökologie: Abdeckung der führenden Projekte in vier großen Kategorien: Kreditvergabe, synthetische Vermögenswerte, Optionen, Indizes;
Zweitens, der Fortschritt der Produktentwicklung für institutionelle Abonnements: ob die verzögerten Stufen, Service-Level-Agreements und prüfbaren Protokolle planmäßig iteriert werden;
Drittens, die Transparenz der Protokolleinnahmen und -verteilung: ob ein öffentlich verifiziertes Datenformat gebildet wurde;
Viertens, die Fortschritte in der Compliance in verschiedenen Jurisdiktionen: einschließlich der Compliance für Datenausgänge und Finanzdienstleistungen.
Diese Kennzahlen werden meine Themenwahl und den Rhythmus auf der Inhaltsebene direkt beeinflussen und auch meine langfristige Bewertung von PYTH beeinflussen.
Zehn, Entwicklerhandbuch: Von Null auf Eins.
Um Partner, die neu im Thema sind, schneller voranzubringen, gebe ich eine umsetzbare "Drei-Schritte-Methode" an.
Erster Schritt, eine Preisabonnement-Abfrage in der Testumgebung durchführen; verstehen der Preisstruktur, Zeitgenauigkeit und Vertrauensintervallfelder;
Zweiter Schritt, das "Abonnement- und Anfrageverfahren" in Verträge oder Handelsbots einbetten und die Gewinnunterschiede zwischen verschiedenen Schwellenwerten und Zeitfenstern durch Backtesting-Systeme vergleichen;
Dritter Schritt, die Alarmüberwachung einrichten; Alarmgrenzen basierend auf Risikokontrollindikatoren festlegen und Anomalielabels in die Rückspiel- und Überprüfungsprozesse einbeziehen.
Wenn du die drei Schritte abgeschlossen hast, hast du nicht nur Pyth verwendet, sondern auch das "verifizierbare Datenkonzept" in den Code umgesetzt.
Elf, Branchenvergleich und Kooperationsspielräume.
Ich befürworte kein Nullsummen-Denken, bei dem eine Seite an Bedeutung verliert, wenn die andere gewinnt. In Szenarien mit breiterer Abdeckung, aber weniger strengen zeitlichen Anforderungen haben traditionelle Datenanbieter immer noch Vorteile; während in Szenarien, die sehr empfindlich auf Verzögerung und Verifizierbarkeit reagieren, das First-Party-Paradigma von Pyth höhere Gewinnchancen hat. In Zukunft erwarte ich, dass Entwickler modulare Ansätze verwenden, um Datenströme aus verschiedenen Quellen zu kombinieren und dynamische Abwägungen zwischen Kosten und Leistung gemäß dem Ziel zu treffen.
@Pyth Network #PythRoadmap $PYTH