

Die meisten AI x Krypto-Projekte fühlen sich gerade so an, als wären sie in einem Discord-Call zusammengeschustert worden, nachdem jemand "dezentrale AI" in ChatGPT eingegeben hat und beschlossen hat, dass das als Roadmap reicht.
Immer das gleiche recycled Pitch: einen Token launchen, "AI-Infrastruktur" auf die Homepage klatschen, vielleicht einen GPU-Marktplatz hinzufügen, den niemand verlangt hat, und hoffen, dass der Retail in die Story einsteigt, bevor die Leute merken, dass es kein echtes Produkt darunter gibt. Vieles davon ist Vaporware, eingepackt in gutes Branding.
Als ich also begann, OpenLedger zu durchforsten, erwartete ich mehr vom Gleichen. Eine weitere Chain, die sich in den AI-Zyklus drängen will, weil dort die Liquidität ist.
Aber ihr Ansatz zielt tatsächlich auf ein reales Problem.
Die unangenehme Realität hinter moderner KI ist, dass die gesamte Branche von unsichtbarer Arbeit abhängt. Modelle werden auf Ozeanen von öffentlichen Daten, Nutzerverhalten, Feedbackschleifen, Forenbeiträgen, Annotationen, Korrekturen – im Grunde Millionen von Menschen, die ohne Zuordnung oder Entschädigung Wert schaffen – trainiert. Große Labore absorbieren all das in geschlossene Systeme, dann tut jeder so, als wäre das Modell durch Magie entstanden.
Dieses Ungleichgewicht wird schlimmer, je wertvoller KI kommerziell wird.
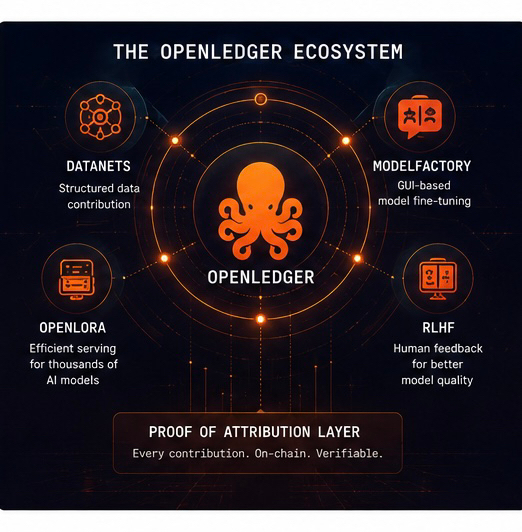
Die These von OpenLedger lautet im Grunde: Wenn Daten der Treibstoff sind, sollten die Beitragsleistenden wahrscheinlich einen Teil des Motors besitzen. Das klingt offensichtlich, wenn man es laut ausspricht, aber fast niemand in der Krypto-Szene baut ernsthaft auf dieser Idee auf. Die meisten Projekte konzentrieren sich immer noch auf Inferenzmärkte oder Spekulationen im Rechenbereich, anstatt Anreiz-Alignments zu schaffen.
Was OpenLedger zu bauen versucht, ist weniger "KI auf der Blockchain" und mehr eine Buchhaltungsschicht für den KI-Beitrag selbst. Der wichtige Unterschied ist, dass sie die Chain von Tag eins um KI-Workflows herum entwerfen, anstatt später generische Infrastruktur nachzurüsten.
Das verändert die Architektur ziemlich.
Sie reden ständig über "Proof of Attribution", was auf den ersten Blick ehrlich gesagt wie ein weiteres Modewort klingt. Krypto hat uns alle gelehrt, Allergien gegen solche Terminologien zu entwickeln. Aber unter dem Branding ist der Mechanismus ziemlich interessant: Beiträge zu Datensätzen, Modellentwicklungen, Feedbackqualität und Inferenzimpact sollen on-chain nachverfolgbar bleiben.
Das bedeutet, wenn jemand Daten beiträgt, die die Leistung eines Modells erheblich verbessern, sollte es eine tatsächliche Aufzeichnung dieses Beitrags und letztendlich wirtschaftliche Vorteile daran geben.

Das ist wichtiger, als die Leute denken.
Denn KI driftet jetzt in Richtung Spezialisierung. Die Ära eines riesigen, allwissenden Modells, das das Internet verschlingt, stößt auf wirtschaftliche und praktische Grenzen. Was Unternehmen tatsächlich wollen, sind kleinere, domänenspezifische Systeme, die für bestimmte Workflows trainiert sind – Finanzen, rechtliche Analysen, medizinische Werkzeuge, Automatisierung, Handelssysteme, Kundenoperationen, was auch immer.
Spezialisierte Modelle sind wahrscheinlich dort, wo der echte Schutzwall entsteht.
Und hier beginnt OpenLedger, kohärenter auszusehen als die durchschnittliche KI-Token-Erzählung, die durch CT schwebt. Sie bieten nicht nur "dezentralisierte Intelligenz" in abstrakten Begriffen an; sie versuchen, eine Infrastruktur zu schaffen, in der Gemeinschaften gemeinsam diese Nischenmodelle entwickeln und verfeinern können, während sie nachverfolgen, wer was beigetragen hat.
Wenn sie es richtig umsetzen, ist das ein bedeutendes primitives Element.
Sie werfen auch mit Werkzeugen wie OpenLoRA, Datanets, ModelFactory, RLHF-Integrationen um sich – all die übliche Buchstabensuppe, die Krypto-Gründer klüger klingen lässt, als sie sind. Aber unter der Terminologie gibt es tatsächlich eine praktische Richtung.
ModelFactory konzentriert sich zum Beispiel auf GUI-basiertes Feintuning, anstatt alles durch reine Engineering-Workflows zu zwingen. Das ist wichtig, denn einer der größten Engpässe bei der Einführung von KI ist immer noch die Benutzerfreundlichkeit. Die meisten Menschen, die in der Lage sind, domänenspezifische Modelle zu verbessern, sind keine ML-Ingenieure. Diese Hürde zu senken, ist entscheidend.
OpenLoRA ist ein weiteres interessantes Teil, wenn es wie beworben funktioniert. Eine große Anzahl spezialisierter Modelle effizient zu bedienen, ohne absurde Infrastrukturkosten, ist ein echtes Problem. Dasselbe gilt für die Koordination strukturierter Daten durch Datanets. Das sind keine imaginären Probleme, die für ein Whitepaper erfunden wurden; es sind legitime Skalierungsprobleme in KI-Systemen.
Das allein bringt OpenLedger bereits weiter als die Hälfte des Sektors, denn sie scheinen zumindest zu verstehen, wo tatsächlich Reibung besteht.

Dann gibt es den Token.
Normalerweise ist dies der Punkt, an dem ansonsten anständige Projekte auseinanderfallen. Man erhält zwanzig Seiten solider Infrastrukturüberlegungen und dann existiert plötzlich der Token für "Ökosystem-Alignment" oder eine andere Phrase, die die Leute verwenden, wenn sie die Nachfrage-Mechaniken nicht erklären können.
OPEN ist enger mit der Netzwerkaktivität verbunden, als ich erwartet habe. Governance, Staking, Inferenzzahlungen, Anreize für Beitragsleistende, Modellteilnahme – das ist alles mit der Nutzung verdrahtet, anstatt mit reiner Spekulation. Ob sich das in nachhaltige Tokenomics übersetzt, ist ein ganz anderes Gespräch, aber mindestens gibt es einen Versuch, wirtschaftliche Aktivität mit tatsächlichem Netzwerkverhalten zu verbinden.
Was seltener ist, als es sein sollte.
Die breitere Wette, die OpenLedger eingeht, ist wahrscheinlich der wichtigste Teil des Ganzen: KI wird eine Wirtschaft, bevor sie ein öffentliches Gut wird.
Und wenn KI wirklich ihre eigene wirtschaftliche Schicht wird, wird die Zuordnung plötzlich zu kritischer Infrastruktur. Jemand muss den Beitrag, das Eigentum, die Herkunft, den Ruf und die Einnahmenverteilung verfolgen – all die chaotischen Koordinationsprobleme, die zentralisierte KI-Unternehmen lieber ignorieren.
Denn die Leute werden nicht ewig wertvolle Trainingsdaten und menschliches Feedback spenden, während Unternehmen all den Gewinn einstreichen.
Dieses Modell bricht irgendwann.
OpenLedger scheint das früher zu verstehen als die meisten Projekte in dieser Kategorie. Ob sie umsetzen können, ist noch eine offene Frage – die Umsetzung ist der Punkt, an dem Krypto-Erzählungen normalerweise sterben, aber zumindest ist das Problem, das sie angehen, real.
Das trennt sie bereits von dem endlosen Haufen von KI-Betrügereien, die derzeit auf dem Markt zirkulieren.
\u003ct-79/\u003e\u003cc-80/\u003e\u003cm-81/\u003e