
most people describe OpenLedger as “AI meets blockchain.” I’ve seen that phrase in about forty different articles now and it still tells me nothing.
here’s what actually got my attention.
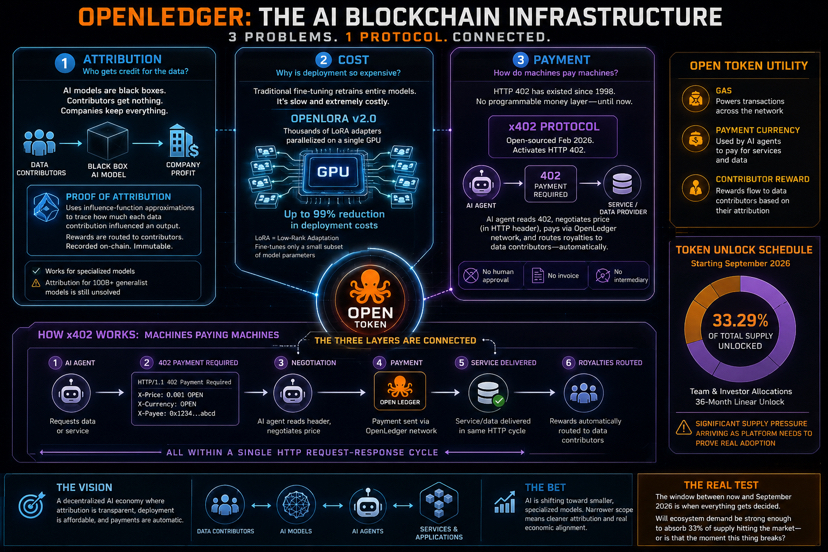
there are three problems in AI that everyone acknowledges and nobody has connected into a single protocol. OpenLedger is attempting to connect all three. whether that’s ambitious or overreaching is genuinely unclear to me — but the architecture is worth understanding before forming an opinion.
the first problem is attribution. when an AI model answers a question, there’s no way to trace which data made that answer possible. the model is a black box. the people who contributed the training data get nothing. the company that deployed the model keeps everything. this isn’t just philosophically unfair — it’s becoming a legal problem. the EU AI Act and a growing pile of lawsuits are forcing the question of data provenance into places that would rather not deal with it.
Proof of Attribution uses influence-function approximations to calculate mathematically how much each data contribution affected a specific output. every training step, every inference — the protocol traces which data was responsible and routes rewards accordingly. recorded on-chain. immutable.
the honest caveat: this works for specialized, domain-specific models. a medical LLM trained on 10,000 curated documents can be attributed. a generalist model trained on the entire internet cannot — attribution at 100B+ parameter scale is still an unsolved problem. the bet OpenLedger is making is that AI is shifting toward smaller LoRA-tuned specialized models anyway. narrower scope means cleaner attribution signal. that bet looks increasingly correct, but it’s still a bet.
the second problem is cost. OpenLoRA v2.0 runs thousands of fine-tuned LoRA adapters parallelized on a single GPU. LoRA — Low-Rank Adaptation — fine-tunes only a small subset of model parameters instead of retraining the whole thing. the claimed result is 99% reduction in deployment costs. I can’t independently verify that number, but the underlying technique is real and well-documented. if the economics genuinely work, the decision to build on OpenLedger becomes about trust rather than cost — which is a different and easier conversation.
the third problem is the one I keep thinking about. it’s called x402. the HTTP 402 status code has existed since 1998. it means “payment required.” it was never implemented because there was no programmable money layer underneath it. OpenLedger open-sourced x402 in February 2026 and finally activates it.
what that means practically: an AI model can read a 402 response, negotiate on price encoded in the HTTP header, pay for the content or service via the OpenLedger network, and route royalties back to data contributors — all inside a single HTTP request-response cycle. no human approval. no invoice. no intermediary.
machines paying machines for intelligence. attribution tracked at every step. OPEN token flowing through all three layers as gas, payment currency, and contributor reward simultaneously.
the architecture is coherent in a way I haven’t seen from other projects in this space. attribution makes contributions measurable. OpenLoRA makes deployment affordable. x402 makes payment automatic. each layer needs the others to work.
what I’m less certain about is execution. the unlock schedule starting September 2026 brings 33.29% of total supply — team and investor allocations — into the market on a 36-month linear schedule. that’s significant supply pressure arriving at roughly the same time the platform needs to prove real developer adoption. those two things happening simultaneously is the central risk.
the technical foundation is real. the window between now and September is when everything gets decided.
so here’s the question I’m actually sitting with: the September unlock is the real test. do you think ecosystem demand will be strong enough to absorb 33% of supply hitting the market — or is that the moment this thing breaks? genuinely curious what others are watching. 👇