
When I first looked at @OpenLedger , what struck me wasn’t that it was “another AI chain.” Crypto has no shortage of projects attaching AI to their pitch deck like a decorative sticker. What felt different here is quieter and more structural: OpenLedger starts from the assumption that AI itself is the workload, not just a narrative layer sitting on top of a generic blockchain.
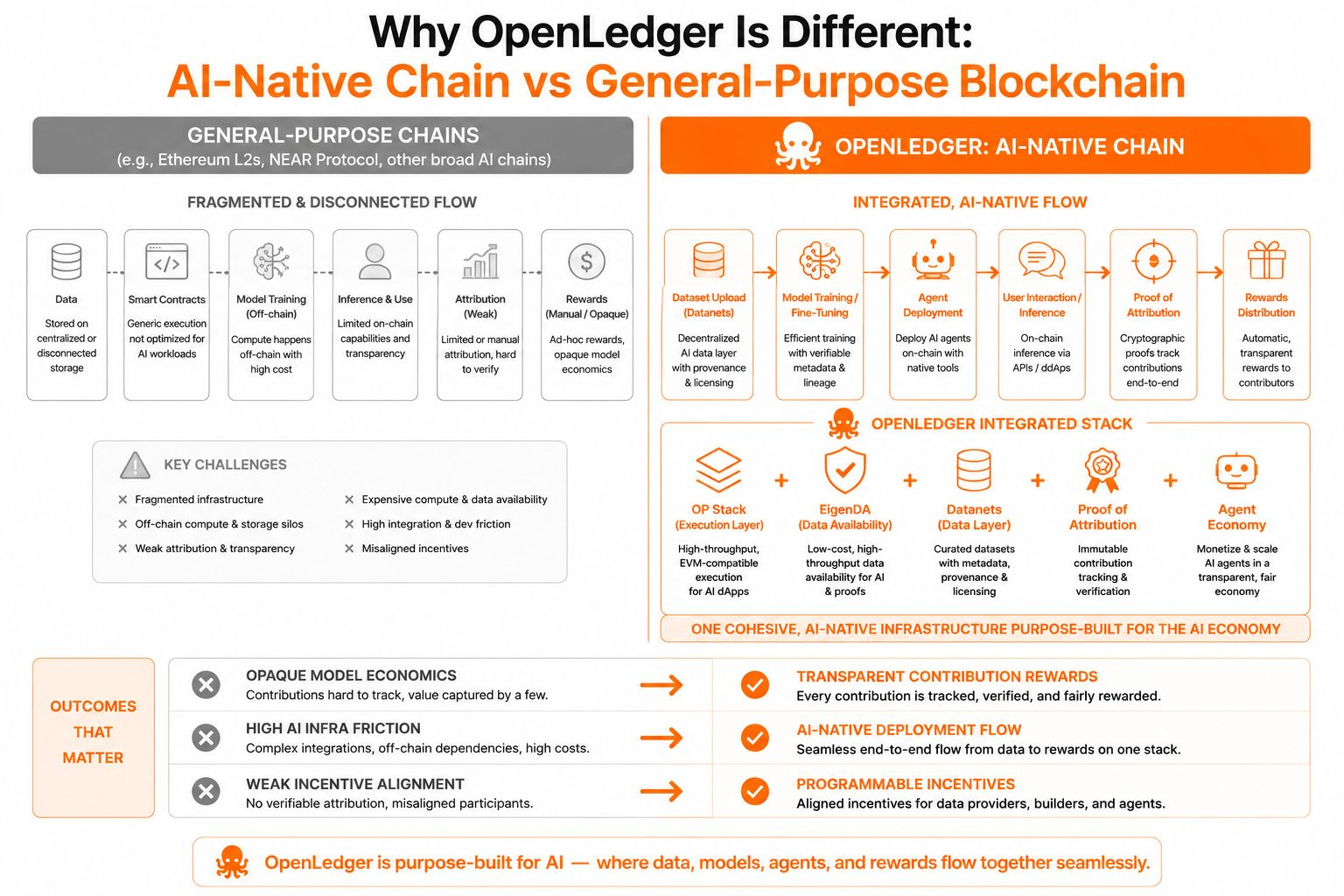
That sounds obvious until you realize most existing L1s and L2s were never designed for AI’s actual problems. Training data is messy, model ownership is blurry, inference is expensive, and the people creating value, whether through data, model tuning, or agent behavior, rarely get credited in a way machines can enforce. General-purpose chains can store transactions well, but AI doesn’t just need storage. It needs memory, attribution, and proof. So OpenLedger’s architecture feels less like adapting blockchain for AI and more like asking what a blockchain would look like if it were built after ChatGPT existed.
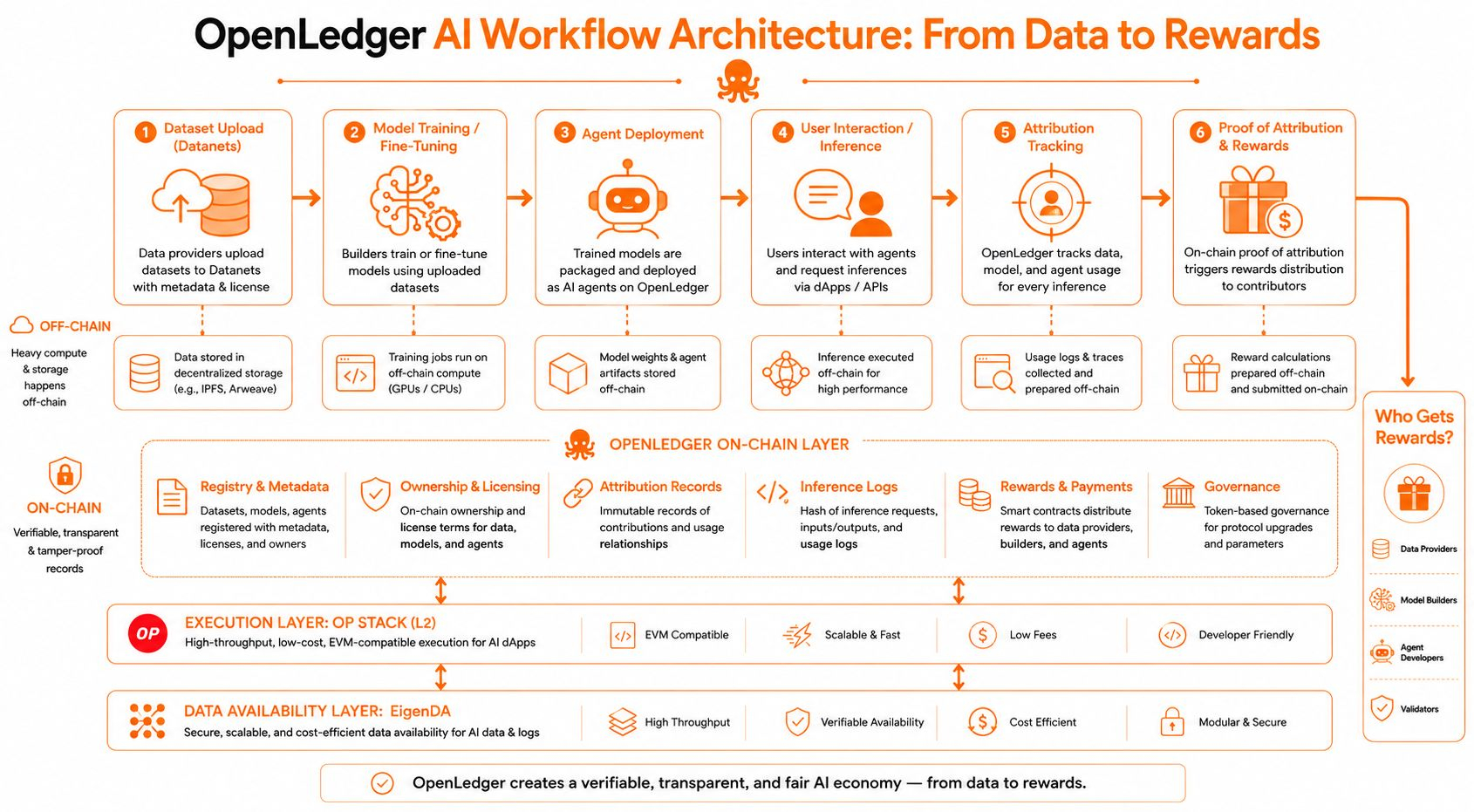
Underneath, the stack is fairly pragmatic. OpenLedger uses the OP Stack as its execution layer, which matters because it inherits Ethereum’s design logic while avoiding Ethereum’s costs. OP Stack gives modularity and EVM compatibility, which means developers can port contracts and tooling without relearning everything from scratch. That sounds boring, but boring is useful here. AI builders don’t need another ecosystem tax.
The more interesting layer is EigenDA. Data availability is an underrated constraint in AI systems because models are cheap compared to the amount of data flowing around them. A fine-tuned small language model might be a few gigabytes, but the training and inference logs, attribution histories, and agent interactions compound quickly. EigenDA is built to handle large blobs of off-chain data with on-chain verification, which lowers storage costs while keeping proofs anchored. In simple terms, OpenLedger doesn’t try to cram AI into the blockchain. It stores what needs trust on-chain and pushes the heavy lifting elsewhere.
That design choice reveals a trade-off. Purists may argue this reduces “full on-chain AI.” They’re right, technically. But full on-chain training is still economically absurd. GPU-heavy compute costs don’t magically disappear because you put them on a blockchain. OpenLedger seems to accept that reality early, which makes the system more usable even if it sacrifices ideological neatness.
The workflow itself is where the architecture starts to feel AI-native. Datasets are uploaded into what OpenLedger calls Datanets, essentially structured data layers that can be permissioned, attributed, and monetized. That matters because raw data is where most AI value originates, yet it’s historically invisible once absorbed into training pipelines.
From there, models can be trained or fine-tuned, then deployed as agents. On the surface, that looks like standard MLOps with crypto wrappers. Underneath, though, every interaction carries provenance. Which dataset influenced this model? Which contributor improved performance? Which agent generated revenue?
That’s where Proof of Attribution becomes the real centerpiece.
Most AI economics today are wildly misaligned. Foundation model providers capture outsized value while upstream contributors disappear. OpenLedger’s PoA mechanism tries to reverse that by assigning transparent credit across the stack. If a dataset improves a model that later powers an agent, the originating contributors can theoretically receive programmable rewards.
The key word is theoretically. Attribution in machine learning is hard. Influence is diffuse. A model’s output isn’t neatly traceable to one row in a dataset or one tuning adjustment. OpenLedger doesn’t fully “solve” attribution in the philosophical sense. What it does is create a measurable approximation with economic consequences. That alone is meaningful.
Understanding that helps explain why OpenLedger leans into small language models rather than pretending every workload should be a frontier-scale model. Specialized SLMs are becoming more attractive right now because the economics are cleaner. A domain-specific model with 7B parameters can outperform much larger systems on narrow tasks while running far cheaper. In a market where inference costs are under pressure and AI monetization is shifting toward agents, this is a rational bet.
Meanwhile, the product layer is already hinting at how the architecture gets used. ModelFactory lowers the barrier for spinning up domain-specific models, while OctoClaw pushes into autonomous agents. These aren’t just demos. They’re attempts to create a vertically integrated loop: data in, model refinement, agent deployment, reward attribution out.
Compared to alternatives like NEAR Protocol, which has broader AI ambitions but remains fundamentally a general-purpose chain, OpenLedger feels narrower by design. That narrowness could be its strength or its ceiling.
The market backdrop makes this timing interesting. AI-agent tokens have seen volatile cycles over the past year, while infrastructure narratives are rotating back toward projects with clearer monetization paths. Investors are becoming less patient with vague “AI x crypto” abstractions. They want systems where token economics map to actual computational demand.
That is the real test for OpenLedger. Not whether the architecture is clever, because it is, but whether attribution markets become real economic primitives rather than a technical curiosity.
If this holds, OpenLedger may end up representing a broader shift underneath both crypto and AI: infrastructure is becoming less about universal design and more about purpose-built systems tuned for one workload exceptionally well.
Sometimes the strongest architecture decision is simply refusing to pretend one chain should do everything.
