
I keep thinking mining was never really about coins.
It looked like it at first. Machines doing repetitive work, electricity turning into blocks, systems rewarding whoever could stay online longer than everyone else. Very physical, almost dull in a way that made it easy to ignore what it was actually building underneath.
AI shifted that feeling without announcing it.
Not through some sudden breakthrough, more like a slow accumulation of invisible participation. People correcting outputs without labeling it work. Feeding small datasets into systems that will never acknowledge the source. Training models indirectly just by interacting with them long enough.
At some point it stops looking like usage and starts looking like production.
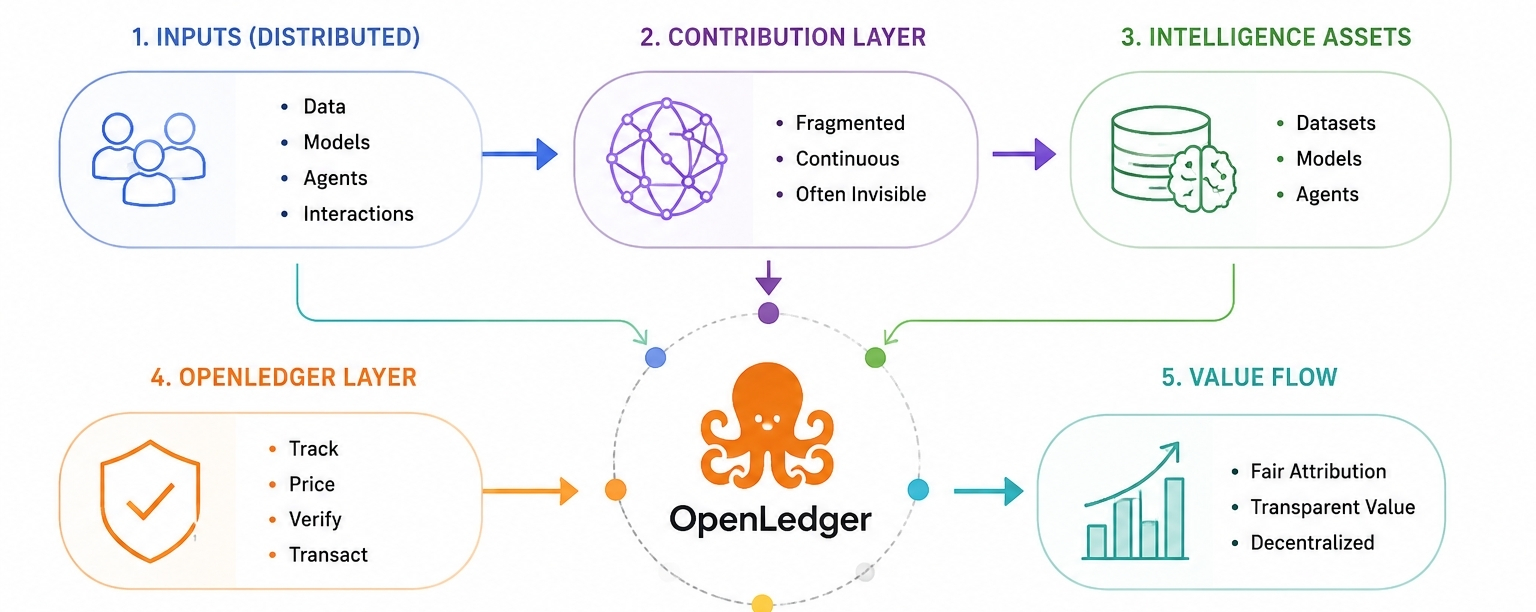
That’s where OpenLedger enters the frame for me, although even saying it like that feels too clean. As if it sits neatly inside a category. It doesn’t.
What it seems to touch is uncomfortable in a quieter way: intelligence isn’t just something you run anymore, it’s something being produced continuously across fragmented contributors, and almost none of that production has a clear ownership line.
Most systems today absorb that output and centralize the value later. That pattern is already familiar. Search did it. Social platforms did it. AI systems just tighten the loop and reduce the delay between input and extraction.
OpenLedger is trying to expose that layer instead of hiding it.
Datasets, models, agents not as abstract infrastructure but as units of contribution that can be tracked or priced or moved. On paper, that sounds like clarity. In practice, it opens a different set of problems that don’t stay theoretical for long.
Once intelligence becomes something with economic weight, behavior changes quickly.
People start optimizing data instead of generating it. Synthetic material begins to fill gaps because it is cheaper and faster. Feedback loops appear where models reinforce their own outputs. What looks like growth can quietly become noise accumulation if verification doesn’t keep pace.
And verification is never simple here. It scales badly. It costs real compute. It introduces bottlenecks that start to look like new centers of control even in systems that claim to avoid them.
I don’t think this contradiction goes away.
Decentralized intelligence sounds like it removes power from the center, but coordination usually rebuilds structure somewhere else, even if it’s harder to see at first. Sometimes especially then.
There is also a more practical tension sitting underneath all of it. Compute is still expensive. Storage is still unevenly distributed. Latency matters more than ideology when systems move from experiments to real usage. These constraints don’t disappear because a system is designed to be open.
So the idea keeps sitting in an unresolved space.
OpenLedger or anything similar, might not be solving intelligence ownership as much as revealing how unclear it already was. Who owns the improvement in a model? Who owns the behavior shaped by millions of tiny interactions? It was never clean, just unspoken.
Maybe that is the point that stays after everything else falls away: intelligence was always a supply chain, just not one we were forced to look at directly until now.
