OpenLedger starts with a simple discomfort that the AI industry rarely says out loud.
A lot of artificial intelligence was built on other people’s work.
Not just books, code, or public websites. Also the small, useful things people leave behind every day: answers in forums, research notes, trading ideas, legal examples, medical explanations, developer comments, tutorials, product reviews, bug reports, datasets, labels, edits, corrections. Tiny pieces of human judgment, scattered everywhere.
Then one day, those pieces show up inside an AI product.
The person who created the knowledge usually gets nothing. No credit. No payment. Often, not even a clear answer on whether their work was used.
That is the crack OpenLedger is trying to enter.
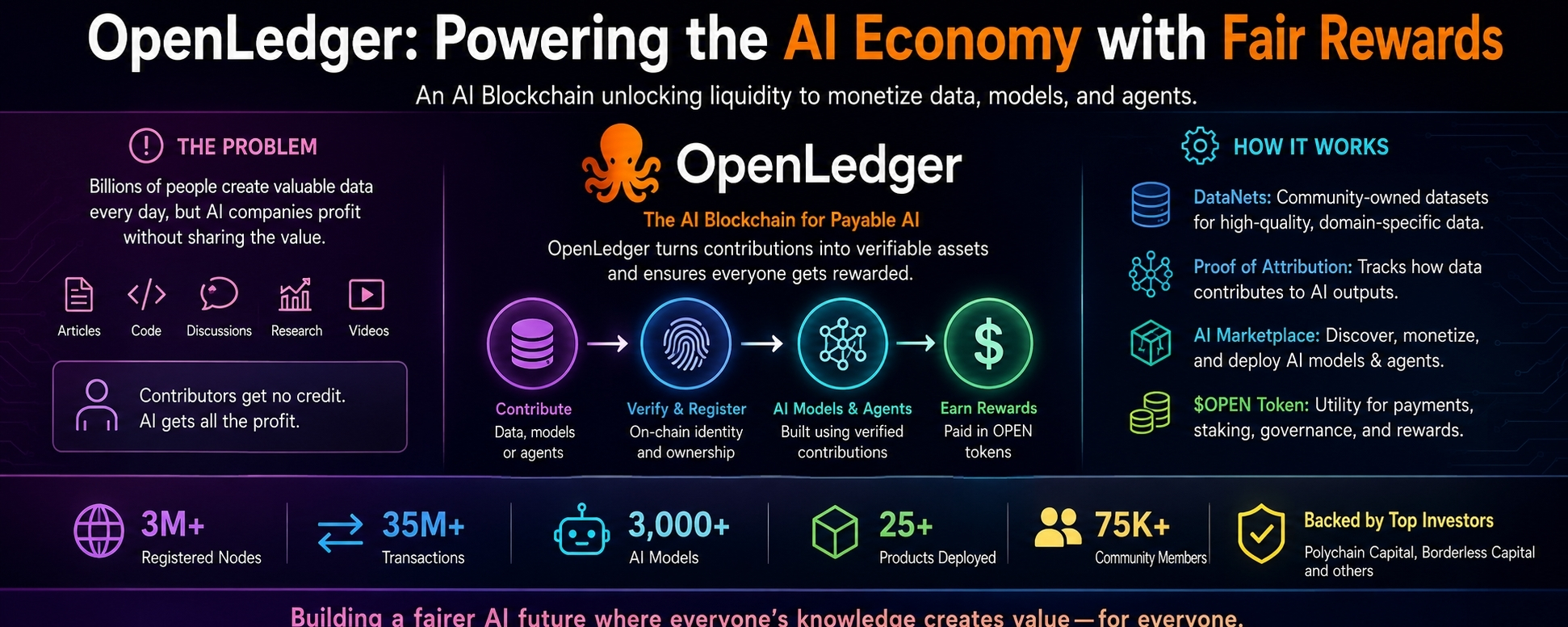
OpenLedger, with its token OPEN, presents itself as an AI blockchain built to help data, models, and agents earn money. The project’s favorite phrase is “Payable AI.” It sounds like startup language, but the idea behind it is easy to understand: if someone’s data helps an AI model become useful, that person should have a way to get paid.
This is not a small ambition. It touches one of the most uncomfortable questions in modern AI. Who owns the knowledge that machines learn from? And if that knowledge produces value, who deserves the return?
For years, the answer was mostly silence.
AI companies collected huge amounts of information from the internet. Some of it was freely available. Some of it was copyrighted. Some of it came from people who never imagined their words, images, code, or examples would help train commercial systems. The industry moved fast because the raw material was already there. The internet became a giant training ground.
Now the mood is changing.
Writers are suing. Publishers are asking questions. Regulators are demanding more transparency. Enterprises are becoming careful about what kind of AI they use, especially when the answers matter. A company using AI for law, healthcare, finance, cybersecurity, or software cannot always accept a black box that says, “Trust me.”
OpenLedger is trying to build for that moment.
Its basic promise is this: create a network where useful data can be contributed, tracked, used to train specialized AI models, and rewarded when those models are used. Instead of data disappearing into a closed system, OpenLedger wants to attach a record to it. Instead of contributors being invisible, it wants them to become part of the payment flow.
That is the attractive version.
The harder version is that OpenLedger has to prove this can actually work.
The project first gained attention because serious crypto investors backed it. Polychain Capital and Borderless Capital led an $8 million seed round in 2024. Later reports said OpenLedger had raised around $15 million in total. That gave the project credibility before most people had seen whether the product could attract real demand.
Like many crypto networks, OpenLedger also reported big testnet numbers: millions of registered nodes, millions of transactions, thousands of AI models, and multiple products. These numbers sound impressive. They also need caution.
Testnets often attract people who are not only testing the product. Some are hunting for airdrops. Some are running multiple wallets. Some are experimenting for a few minutes and leaving. Some are real builders. Some are only there because rewards may come later.
So the question is not, “Did people show up?”
The question is, “Will they stay when the rewards become harder to earn?”
OpenLedger’s system has a few important parts.
The first is the blockchain itself, where OPEN works as the native asset. It is used for network fees, rewards, governance, and payments inside the ecosystem.
The second is something OpenLedger calls DataNets. Think of these as focused pools of data for specific fields. A DataNet could be built around legal knowledge, healthcare, finance, cybersecurity, trading, software development, or another expert area. The point is not to collect random internet scraps. The point is to gather useful, structured information that can help train better AI models.
The third part is the model layer. OpenLedger is not trying to beat the largest AI labs at building giant general-purpose models. Its more realistic path is through smaller, specialized models. These models do not need to know everything. They need to be good at one thing.
That matters.
A smaller model trained on strong legal data may be more useful for contract analysis than a general chatbot giving vague answers. A cybersecurity model trained on real exploit reports may be better for a security team than a generic assistant. A crypto research model built from verified market data may be more valuable than one trained on noisy social posts.
This is where OpenLedger’s idea becomes more believable. Specialized models are easier to judge. Their data sources are easier to inspect. Their value is easier to measure.
The fourth part is the most important: attribution.
OpenLedger wants to know which data helped produce value. If a model gives a useful answer, the network should be able to identify the data that influenced it and reward the people behind that data. This is what the project calls Proof of Attribution.
On paper, it is elegant.
A contributor uploads useful data. A model uses that data. A user pays to use the model. The contributor receives OPEN.
But AI does not always behave in such a clean way.
A model does not usually point to one exact piece of data and say, “This answer came from here.” It learns patterns. It blends examples. It compresses information. A single output may be influenced by thousands or millions of data points, plus the base model, the prompt, the fine-tuning method, and the user’s context.
So OpenLedger’s biggest challenge is not only building a blockchain. The harder challenge is building trust around attribution.
People need to believe the reward system is fair. Developers need to believe the data is high quality. Users need to believe the models are useful. Validators need to stop spam, copied data, and low-effort submissions. If any part breaks, the whole system becomes weaker.
This is especially important because money changes behavior.
If people are rewarded for uploading data, some will upload excellent material. Others will upload junk. Some will copy from elsewhere. Some will try to game the system. Some will submit slightly changed versions of the same thing again and again. This happens in every incentive network.
OpenLedger will need strong filters. It will need real validation. It will need clear rules about licensing, ownership, and quality. Otherwise, the network could become crowded with data that looks valuable only because rewards exist.
That is the danger with many crypto-AI projects. They can create activity without creating usefulness.
OPEN’s tokenomics show how central incentives are to the project. The total supply is 1 billion tokens. A large share is set aside for community rewards and ecosystem growth. Investors and the team receive their own allocations, with vesting schedules designed to prevent everything from entering the market at once.
This setup gives OpenLedger room to reward contributors, developers, validators, and early users. It also creates pressure. Tokens used for incentives eventually enter the market. If real demand does not grow, rewards can turn into sell pressure.
That is why OPEN cannot be judged only by its supply chart.
The important questions are more practical.
Are people paying to use models on OpenLedger?
Are developers building products that users return to?
Are DataNets collecting information that cannot easily be found elsewhere?
Are contributors earning because their data is useful, or only because the system is distributing tokens?
Are enterprises using the network beyond pilot programs?
These questions matter more than slogans.
There is one detail in OpenLedger’s story that deserves attention. The foundation announced a buyback after explaining that part of the original liquidity allocation had been used to reward enterprise data contributors. It described this as an oversight and said it would buy back tokens to restore liquidity.
This can be read two ways.
The positive reading is that OpenLedger had real enterprise-related contributor activity and chose to reward it. That would support the idea that useful data is already moving through the system.
The cautious reading is that treasury planning needed correction. For a project built around transparent value flows, that kind of mistake is not fatal, but it is worth watching.
OpenLedger is operating in a crowded field. It is not the only project trying to connect AI and crypto. Some focus on decentralized computing. Some focus on data ownership. Some focus on model marketplaces. Some focus on agents. Some focus on scraping public web data. Others try to reward users for contributing personal or community-owned information.
OpenLedger’s angle is more specific. It wants to become the accounting layer for AI contribution.
That gives it a clearer identity than many projects in the category. But it also gives it a harder job.
It must prove that attribution can be more than a nice idea. It must prove that contributors can be paid in a way that feels fair. It must prove that developers want to build on top of the system. It must prove that users care about provenance enough to pay for it.
And it has to do all this while competing against centralized AI companies that already have customers, distribution, cloud partnerships, and legal teams.
Large AI platforms could build their own attribution and licensing systems. Media companies could make direct deals with AI labs. Enterprises could choose private data contracts instead of open token networks. If that happens, OpenLedger’s open approach would need to offer something clearly better: wider access, better incentives, transparent records, or a stronger developer ecosystem.
The best case for OpenLedger is not that every AI model will run through it. That is unlikely.
The stronger case is that some areas of AI need exactly what it is trying to build.
A medical model needs trusted data. A legal model needs traceable sources. A financial model needs timely and credible inputs. A cybersecurity model needs examples from people who understand real attacks. In these fields, random scraped data is not enough. Expertise matters. Provenance matters. Payment may matter too, because experts will not keep giving away valuable knowledge for free forever.
If OpenLedger can build strong DataNets in even a few serious areas, it may create a real business around specialized AI. Contributors would not be donating information into a void. Developers would not be starting from zero. Users would not be buying mysterious outputs from unknown sources.
That is the attractive picture.
The weaker picture is also possible.
The network could become another incentive machine. People upload data because tokens are available. Developers launch models because grants exist. Usage appears active while rewards are flowing. Then, when incentives slow down, the activity fades. The token remains, but the economy behind it becomes thin.
This is the line OpenLedger has to avoid.
The project is interesting because it is aiming at a real wound in the AI economy. But being early to a real problem does not guarantee success. Many companies understand the problem. Few build the system that people actually use.
For now, OpenLedger sits somewhere between promise and proof.
It has funding. It has a mainnet. It has a token. It has a narrative that fits the current anxiety around AI data. It has a clear problem to solve. Those are meaningful advantages.
But the final test will be boring, not dramatic.
Do useful models get built?
Do contributors earn repeatedly?
Do users pay without being bribed by incentives?
Do enterprises trust the system?
Does OPEN become necessary inside the network, or merely tradable outside it?
That is where the story will be decided.
OpenLedger is not just trying to put AI on a blockchain. It is trying to answer a question the AI industry can no longer ignore: when machines profit from human knowledge, should the humans remain invisible?
The answer may shape more than one token.
It may shape the next fight over who gets paid in the age of artificial intelligence.