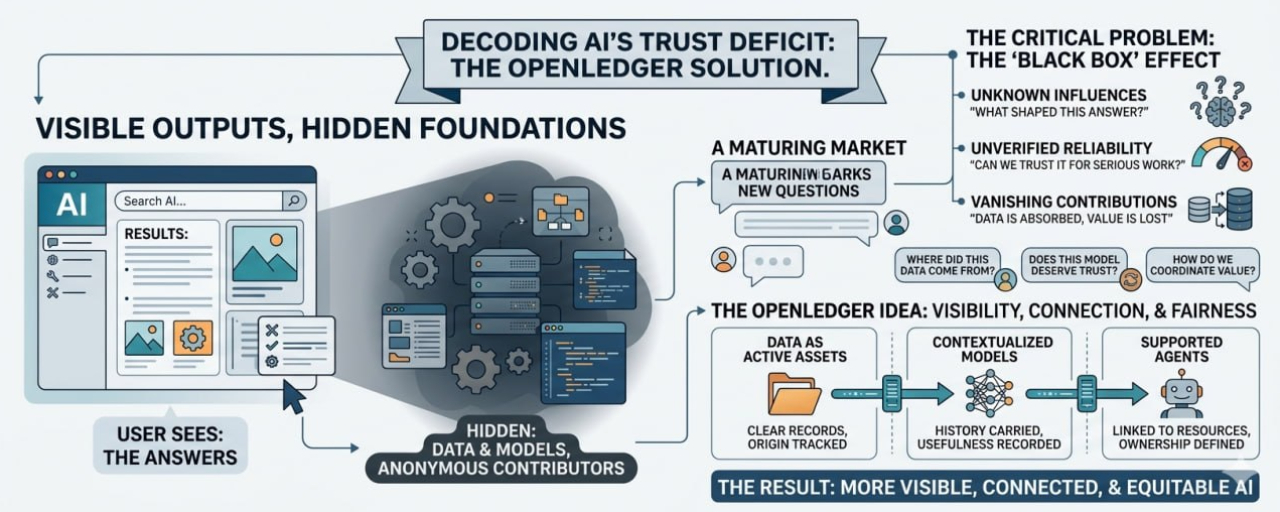
Jeder kann die Outputs sehen. Die Antworten, die Bilder, die Agenten, die Tools, die Aufgaben in wenigen Sekunden erledigen. Dieser Teil ist sichtbar. Es ist einfach zu reagieren. Einfach zu bewerten. Einfach zu teilen.
Aber die Teile darunter sind viel schwerer zu sehen.
Die Daten sind irgendwo im Hintergrund. Das Modell ist irgendwo hinter dem Bildschirm. Die Leute, die geholfen haben, zu erstellen, zu verbessern, zu strukturieren oder das Wissen bereitzustellen, sind normalerweise nicht mehr Teil der Geschichte. Sie sind da, auf eine Art, aber nicht wirklich sichtbar.
Das ist ein Grund, warum OpenLedger es wert ist, Beachtung zu finden.
Nicht, weil es einfach KI und Blockchain kombiniert. Dieser Satz allein sagt nicht mehr viel aus. Viele Projekte behaupten das. Einige von ihnen könnten nützliche Dinge bauen, einige vielleicht nicht. Die Worte selbst sind nicht genug.
Was interessanter ist, ist das Problem, um das sich OpenLedger zu drehen scheint.
KI braucht Vertrauen, aber Vertrauen ist schwierig, wenn alles verborgen ist.
Wenn ein KI-Modell eine Antwort gibt, wissen die meisten Nutzer nicht, was diese Antwort geformt hat. Sie wissen nicht, welche Daten beim Training geholfen haben. Sie wissen nicht, ob das Modell durch Experteninput, öffentliche Daten, private Datensätze oder eine Mischung aus allem verbessert wurde. Sie wissen auch nicht, wer Wert erhalten sollte, wenn dieses Modell nützlich wird.
Für die meisten Menschen mag das wie ein entferntes technisches Problem klingen. Aber es wird realer, wenn man darüber nachdenkt, wie KI in die alltägliche Arbeit einzieht.
Ein Unternehmen möchte möglicherweise KI nutzen, die auf branchenspezifischem Wissen trainiert wurde. Ein Ersteller möchte, dass seine Daten verwendet werden, aber nicht ohne Anerkennung verschwinden. Ein Entwickler könnte einen Agenten bauen, der auf verschiedenen Modellen und Datensätzen basiert. Ein Unternehmen möchte wissen, ob ein KI-System zuverlässig genug ist, um in ernsthaften Arbeitsabläufen verwendet zu werden.
An diesem Punkt ist die Frage nicht nur: 'Funktioniert die KI?'
Die Frage wird: 'Können wir verstehen, worauf es ankommt?'
Hier beginnt die Idee von OpenLedger praktischer zu wirken.
Es versucht, ein System zu schaffen, in dem Daten, Modelle und Agenten nicht als lose, unsichtbare Teile behandelt werden. Sie können verbunden werden. Sie können Aufzeichnungen haben. Sie können eine Geschichte darüber tragen, woher sie kommen und wie sie verwendet werden.
Das mag klein erscheinen, aber es ändert die Art und Weise, wie Wert fließen kann.
In der heutigen KI-Welt wird Daten oft in ein größeres System integriert, und sobald das passiert, wird es schwierig, die Quelle vom Endergebnis zu trennen. Ein nützlicher Datensatz kann helfen, ein Modell zu verbessern, aber die Person oder Gruppe hinter diesem Datensatz hat möglicherweise keinen klaren Weg, um von zukünftigen Nutzungen zu profitieren. Ein kleineres Modell kann einen wichtigen Zweck erfüllen, könnte aber unter einer größeren Anwendung begraben sein. Ein Agent kann eine Aufgabe gut ausführen, aber die Ressourcen dahinter könnten unsichtbar bleiben.
OpenLedger scheint zu fragen, ob diese Schichten klarer gemacht werden können.
Nicht perfekt klar. Das wäre zu einfach zu sagen und wahrscheinlich nicht realistisch. Aber klarer als jetzt.
Und vielleicht ist das genug, um zu beginnen.
Denn KI braucht nicht nur mehr Daten. Sie braucht bessere Gründe, damit die Leute gute Daten teilen. Sie braucht Systeme, in denen nützliche Beiträge nicht wie einmalige Eingaben behandelt werden, die in der Maschine von jemand anderem verschwinden. Sie braucht eine Möglichkeit, wie verschiedene Teile zusammenarbeiten können, ohne dass alles geschlossen, privat und schwer zu überprüfen wird.
Blockchain kann theoretisch bei einem Teil davon helfen. Es kann Aufzeichnungen bereitstellen, die geteilt, nachverfolgbar und schwerer heimlich zu ändern sind. Das löst nicht jedes KI-Problem. Es macht ein Modell nicht automatisch gut. Es schafft nicht magisch Nachfrage. Es beseitigt nicht die Notwendigkeit für starke Produkte.
Aber es kann bei der Koordination helfen.
Und Koordination zählt mehr, als die Leute manchmal denken.
KI ist nicht eine einzelne Sache. Es ist ein Stapel aus vielen Dingen. Daten, Berechnungen, Modelle, Bewertungen, Agenten, Schnittstellen, Nutzer, Feedback. Jede Schicht hängt von einer anderen Schicht ab. Wenn die Verbindungen zwischen ihnen unklar sind, wird der Wert chaotisch. Einige Mitwirkende werden belohnt. Andere werden vergessen. Einige Systeme gewinnen Vertrauen. Andere fühlen sich wie Black Boxes an.
OpenLedger ist interessant, weil es sich mit diesem chaotischen mittleren Bereich beschäftigt.
Der Platz zwischen Rohdaten und nützlicher KI.
Hier könnte viel zukünftiger Wert liegen.
Nicht nur im größten Modell. Nicht nur im auffälligsten Agenten. Sondern in den spezifischen Datensätzen, spezialisiertem Wissen, fein abgestimmten Modellen und kleinen Verbesserungen, die KI in realen Situationen nützlich machen. Die Art von Wert, die leicht übersehen werden kann, weil sie nicht immer laut ist.
Man kann das normalerweise nach einer Weile in der Technologie erkennen. Die erste Phase geht darum, leistungsstarke Werkzeuge zu bauen. Die nächste Phase dreht sich darum, diese Werkzeuge nutzbar, vertrauenswürdig und mit realen Anreizen verbunden zu machen.
KI scheint jetzt in diese zweite Phase einzutreten.
Die Leute beginnen, andere Fragen zu stellen. Woher stammt diese Information? Kann diesem Modell vertraut werden? Wer profitiert von meinem Beitrag? Kann Daten mehr werden als eine Datei, die im Speicher sitzt? Können Agenten Wert schaffen, während sie immer noch mit den Ressourcen verbunden sind, die sie nutzen?
OpenLedger sitzt inmitten dieser Fragen.
Es muss nicht als Revolution beschrieben werden, um interessant zu sein. Manchmal sind die ruhigeren Infrastrukturideen wichtiger, als sie auf den ersten Blick erscheinen. Sie machen nicht immer Lärm. Sie versuchen einfach, die Lücken zu schließen, die offensichtlich werden, wenn ein Markt zu reifen beginnt.
Und in der KI ist eine dieser Lücken das Eigentum.
Nicht Eigentum im einfachen Sinne, etwas zu halten. Mehr wie zu wissen, wie Wert geschaffen wird, wohin er reist und ob die Leute dahinter einen Platz im System haben, nachdem ihre Arbeit genutzt wurde.
Das ist ein härteres Problem, als es klingt.
Die Rolle von OpenLedger, zumindest aus dieser Perspektive, besteht darin, KI-Assets einen klareren Weg zu geben. Daten können mehr sein als ein versteckter Input. Modelle können mehr Kontext tragen. Agenten können mit den Systemen verbunden werden, die sie unterstützen. Wert kann mit ein bisschen mehr Gedächtnis fließen.
Vielleicht ist das der Teil, den man im Auge behalten sollte.
Nicht das Etikett 'KI-Blockchain', sondern der Versuch, die verborgenen Schichten der KI sichtbarer, verbundener und vielleicht ein bisschen fairer zu machen.
Es ist noch früh. Viel hängt von der Akzeptanz, realen Anwendungsfällen und davon ab, ob die Leute tatsächlich auf diese Art von System aufbauen wollen.
Aber das Bedürfnis dahinter fühlt sich echt genug an.
Während sich KI weiter verbreitet, könnte die stille Frage darunter nicht verschwinden.
Wer wird gesehen, wenn Intelligenz nützlich wird…
\u003cm-40/\u003e \u003ct-42/\u003e \u003cc-44/\u003e