I used to think the biggest AI debate was about model size and speed. My view has changed as AI has moved deeper into real work. The question I keep coming back to is simpler and difficult. Who gets credit when intelligence is built from thousands of invisible contributions.
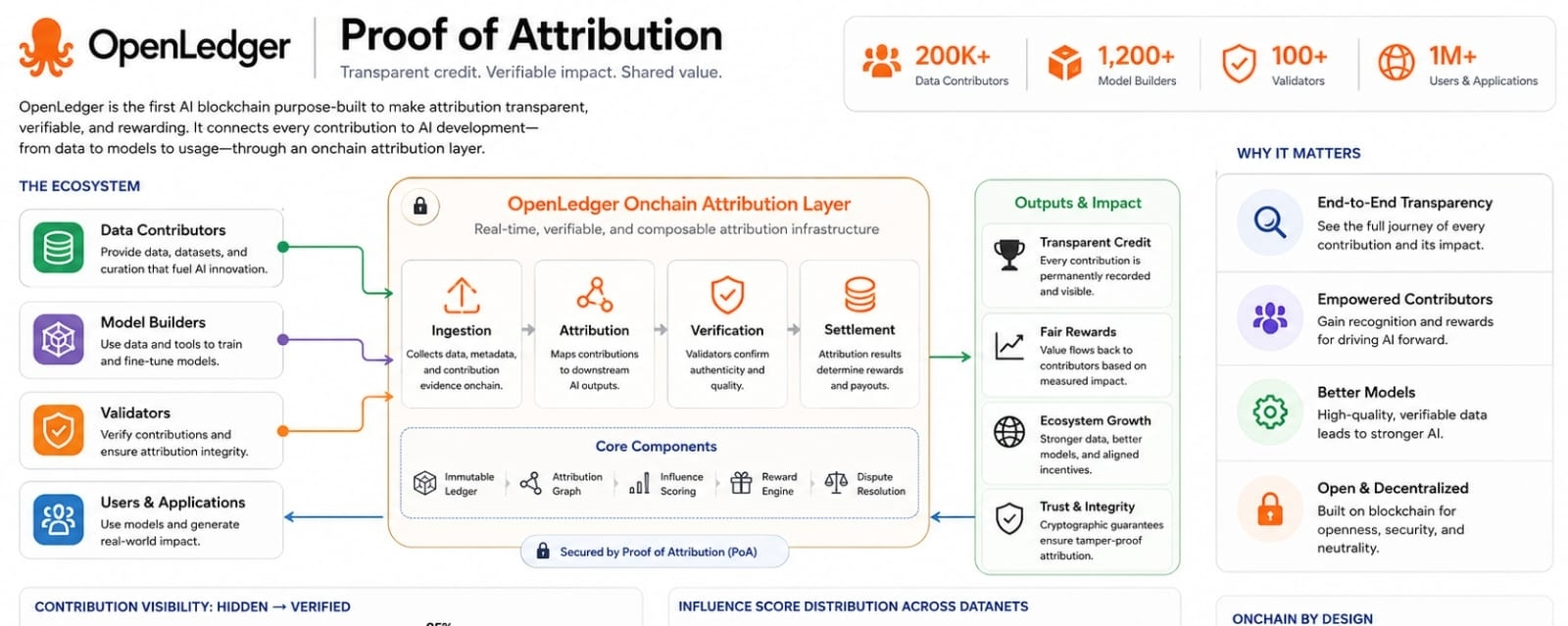
OpenLedger enters that question with a specific claim. If data models and agents create value then the path of that value should be visible. Not just visible as a dashboard after the fact but visible inside the system that records what happened. This is why Proof of Attribution matters. It is the idea that data influence can be traced and connected to rewards through an onchain record. I find it useful to look at OpenLedger less as another chain and more as an attempt to build accounting rails for AI work.

That accounting problem is becoming harder to ignore. Most people understand that AI models depend on data. Fewer people can see how one dataset or one model update changes a real output. That gap creates a strange economy. The output can be valuable while the people who shaped it remain hidden. OpenLedger tries to narrow that gap by treating contribution as something that can be registered measured and rewarded. DataNets are central here because they turn datasets into community built assets with provenance. In plain terms they create a place where specialized data can be gathered and connected to later model behavior.
The strong part of the thesis is its focus on specialization. I do not think every useful AI system needs to be a giant general model. Many real use cases need narrower models that understand a domain well. A legal assistant needs clean legal context. A medical support tool needs careful medical references. A security model needs examples that are current and specific. If specialized models become more important then specialized datasets become more valuable. If those datasets become more valuable then attribution becomes more than a fairness issue. It becomes part of the economic design.
What I like about the idea is that it does not depend only on people trusting a platform to be generous. The design tries to connect model usage with records of training provenance and inference level influence. That is a meaningful shift. It says that credit should not be based only on reputation or social visibility. It should come from evidence of influence. For builders this could make data sourcing cleaner. For contributors it could make participation feel less extractive. For users it could make outputs easier to audit.
Still I do not think the hard part is the slogan. The hard part is measurement. AI attribution is technically messy. A model does not always reuse data in a clean visible way. It blends patterns. It generalizes. Sometimes it memorizes. Sometimes a data point influences behavior indirectly. OpenLedger addresses this with attribution methods that try to estimate or trace influence. That is promising but it also creates a burden. The system has to be accurate enough to be trusted. It has to be efficient enough to run at scale. It has to resist low quality submissions and gaming.
That is where the short term and long term picture look different to me. In the short term the market may care about adoption signals. Are developers building models. Are contributors adding useful data. Are DataNets forming around real domains rather than loose content pools. Are inferences happening in a way that creates visible reward flows. These are practical signs. They matter more than polished language because they show whether the system is becoming useful.
Over the longer term the bigger question is whether OpenLedger can become trusted infrastructure. That means contributors need confidence that the attribution record is fair. Developers need tools that do not slow them down. Validators need clear ways to protect quality. Builders need a reason to choose this stack over a simpler centralized service. If those pieces line up then OpenLedger could support a new kind of AI market where datasets and model improvements behave like productive assets. If they do not line up then the project could remain interesting but limited.
From an investment or trading perspective I would not look at OpenLedger only through price action. Price can move before fundamentals are clear. That is normal in crypto and it can mislead people quickly. I would watch usage based evidence. More active DataNets would matter. Repeat model deployment would matter. Transparent reward distribution would matter. Stronger developer tooling would matter. On the other side weak data quality low model demand unclear attribution results or reward systems that feel hard to verify would weaken the case.
The practical use case is simple to understand. Imagine a specialist contributes high quality data to a focused DataNet. A developer trains or fine tunes a model with that data. Later a user asks the model a question and the answer is partly shaped by that contribution. OpenLedger wants the system to recognize that chain. It wants the contributor to be more than a forgotten input. That is both the human side and the commercial side.
My personal thesis is that OpenLedger is most interesting if AI keeps moving toward smaller specialized systems that need trustworthy data supply. In that world attribution is not decoration. It is infrastructure. The risk is that attribution becomes too complex or too expensive or too easy to dispute. The opportunity is that a working attribution layer could make data contribution feel rational for experts communities and builders.
I do not see OpenLedger as a finished answer. I see it as a serious attempt to solve a real coordination problem in AI. The vision is strong because it connects fairness with utility. The uncertainty is real because the system must prove its measurements can hold under pressure. OpenLedger is not just asking whether AI can be open. It is asking whether the people and data behind AI can finally remain visible after the model starts producing value.
@OpenLedger #OpenLedger $OPEN $RONIN
