
Die KI-Industrie redet gerne über Skalierung, weil Skalierung mächtig klingt.
Mehr GPUs. Mehr Parameter. Mehr Tokens, die pro Sekunde verarbeitet werden.
Aber je tiefer ich in Projekte wie OpenLedger eintauche, desto mehr denke ich, dass die nächste große KI-Wirtschaft nicht nur um Skalierung gebaut wird.
Es wird um Eigentum herum aufgebaut.
Nicht das Eigentum an Modellen.
Eigentum an der Datenwirtschaft unter den Modellen.
Und gerade jetzt ist diese Wirtschaft überraschend kaputt.
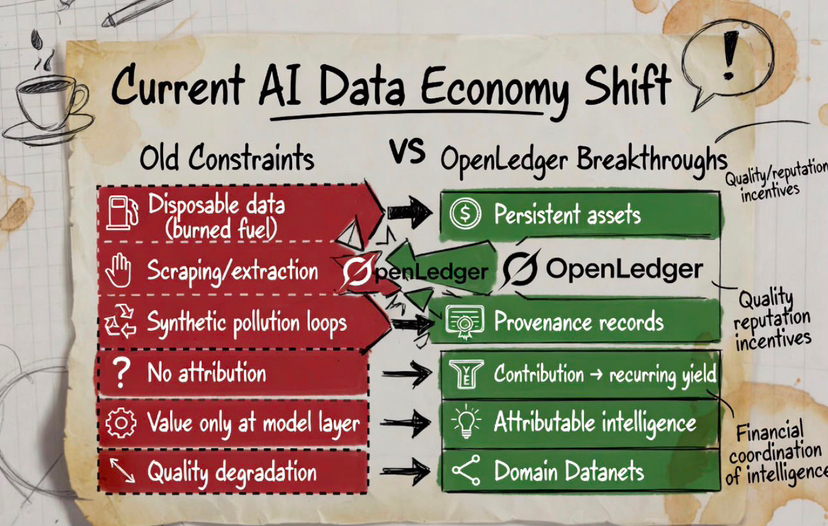
Die meisten Trainingsdatensätze in der KI funktionieren wie Einwegtreibstoff. Informationen werden hochgeladen, abgekratzt, etikettiert, während des Trainings konsumiert und dann wirtschaftlich für immer aufgegeben. Die Mitwirkenden verschwinden. Die Datensätze werden statische Archive. Die Modelle generieren Milliarden im Wert, während die Intelligenzschicht darunter finanziell tot wird.
Diese Struktur machte Sinn, als KI-Systeme primitiv waren.
Ich denke nicht, dass es langfristig funktioniert.
Besonders nicht, wenn KI tief in finanzielle Systeme, Unternehmensinfrastruktur, autonome Agenten und kommerzielle Automatisierung integriert wird.
Denn letztendlich beginnt der Markt, eine andere Frage zu stellen:
Warum akkumuliert der gesamte langfristige Wert nur auf der Modellebene, während die Trainingsebene wirtschaftlich getrennt bleibt?
Das ist genau das Problem, das OpenLedger versucht, neu zu gestalten.
Und ehrlich gesagt, ich denke, die meisten Leute betrachten das Projekt immer noch zu eng.
OpenLedger baut nicht einfach nur KI-Infrastruktur.
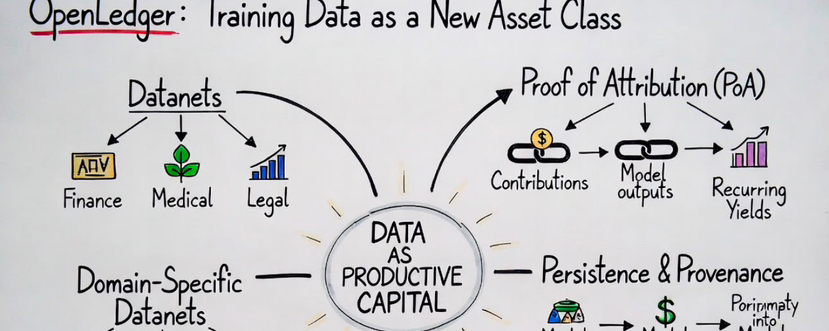
Es versucht, Trainingsdaten selbst in eine wirtschaftliche Vermögensklasse zu verwandeln.
Das ist eine viel größere Idee.
Der Unterschied ist wichtig, denn Vermögenswerte verhalten sich anders als Ressourcen.
Eine Ressource wird verbraucht.
Ein Vermögenswert bleibt über die Zeit wirtschaftlich produktiv.
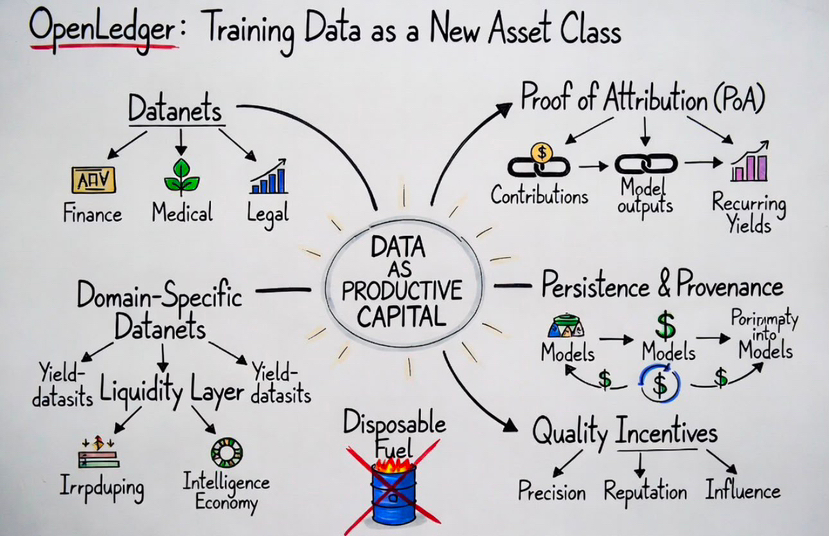
Im Moment verhält sich die meiste KI-Trainingsdaten wie Öl, das einmal verbrannt und vergessen wird. OpenLedger experimentiert mit einem System, in dem wertvolle Intelligenzbeiträge weiterhin an der nachgelagerten Wertschöpfung teilnehmen, lange nachdem das Training erfolgt ist.
Das verändert die Ökonomie der KI komplett.
Die DatenNetz-Architektur des Projekts ist der Punkt, an dem dies wichtig wird.
Anstatt Intelligenz in riesige anonyme Scraping-Systeme zu organisieren, strukturiert OpenLedger Daten in spezialisierten kollaborativen Netzwerken, die um spezifische Bereiche und Beitragsumgebungen herum aufgebaut sind. Finanzdatensätze. Medizinische Datensätze. Rechtliche Datensätze. Technische Datensätze.
Aber der wichtige Teil ist nicht nur Spezialisierung.
Es ist Persistenz.
Beiträge innerhalb dieser Systeme sind an Herkunftsaufzeichnungen, Mitwirkendenhistorie, Metadaten, Lizenzierungskontext, Zeitstempel, Attributionslogik und Einflussverfolgungssysteme gebunden, die darauf ausgelegt sind, wirtschaftliche Beziehungen nach den Trainingszyklen zu erhalten.
Dieser letzte Teil ist der Punkt, an dem das Projekt sich wirklich von den meisten KI-Narrativen in Krypto unterscheidet.
Denn OpenLedger fragt effektiv:
Was passiert, wenn Trainingsdaten aufhören, entsorgbar zu sein?
Diese Frage hat massive Implikationen.
Die aktuelle KI-Ökonomie behandelt Datensätze größtenteils wie Extraktionszonen. Daten gelangen in zentrale Systeme, der Wert verlässt irgendwo anders, und die Mitwirkenden hinter der Intelligenzschicht pflegen selten eine dauerhafte Verbindung zur nachgelagerten Monetarisierung.
OpenLedger versucht, Kontinuität zwischen Beitrag und zukünftiger Nützlichkeit zu schaffen.
Das schafft eine völlig andere Marktstruktur rund um die Intelligenz selbst.
Und ehrlich gesagt, ich denke, der Begriff 'KI-Liquiditätsschicht' macht viel mehr Sinn, wenn man das Projekt durch diese Linse betrachtet.
Zuerst dachte ich, es klingt wie Markenprache.
Jetzt denke ich, dass es tatsächlich den zentralen wirtschaftlichen Mechanismus beschreibt.
Liquidität bezieht sich traditionell auf Kapital, das effizient durch Systeme fließt, anstatt in isolierten Silos gefangen zu bleiben. OpenLedger wendet eine ähnliche Logik auf Intelligenzökonomien an.
Statt dass Informationen nach dem Hochladen wirtschaftlich eingefroren werden, ermöglichen Attributionssysteme den Einfluss, mit nachgelagerten Ausgaben verbunden zu bleiben und potenziell weiterhin wiederkehrende Wertbeziehungen zu erzeugen.
Das ist ein sehr radikaler Wandel, wie KI derzeit funktioniert.
Denn der heutige KI-Stack belohnt größtenteils die Konzentration von Eigentum.
OpenLedger experimentiert mit der Persistenz von Beiträgen.
Diese Unterscheidung ist sehr wichtig.
Besonders weil die breitere KI-Industrie leise auf eine Datenqualitätskrise zusteuert.
Das Internet wird mit synthetischen Informationen übersättigt. KI-generierte Ausgaben trainieren zunehmend neuere KI-Systeme und schaffen rekursive Schleifen, in denen die Signalqualität im Laufe der Zeit abnimmt. Unendliche Informationen sind nicht mehr der Engpass.
Zuverlässige Informationen sind.
Vertrauliche Informationen sind.
Hochsignal-Information ist.
Deshalb fühlt sich die Architektur von OpenLedger jetzt richtungsweisend wichtig an.
Das Projekt optimiert nicht für maximales Datenvolumen.
Es optimiert für zuschreibbare Intelligenzqualität.
Und sobald die Qualität der Intelligenz wirtschaftlich messbar wird, ändert sich das Verhalten der Mitwirkenden automatisch.
Jetzt interessieren sich die Mitwirkenden für:
* Präzision
* Nützlichkeit
* Ruf
* Einfluss
* nachgelagerte Nützlichkeit
Stattdessen:
* Spam-Uploads
* Volumenfarming
* Niedrigqualitatives Skalieren
Dieser Wandel mag subtil erscheinen, aber er verändert grundlegend, wie KI-Ökosysteme sich entwickeln.
Denn Anreize prägen Informationsumgebungen mehr als Technologie allein.
Und ehrlich gesagt, hier fühlt sich OpenLedger tiefer an als die meisten KI-Krypto-Projekte, die ich kürzlich recherchiert habe.
Viele KI-Narrative drehen sich heute um Geschwindigkeit, Automatisierung, Verbraucheragenten oder spekulative Hypezyklen. OpenLedger fühlt sich mehr darauf konzentriert an, wirtschaftliche Infrastruktur unter der Intelligenzschicht selbst aufzubauen.
Das schafft in der Regel ein stärkeres langfristiges Positionieren.
Besonders weil KI-Systeme letztendlich mit finanzieller Logik kollidieren.
Sobald Intelligenz beginnt, bedeutenden wirtschaftlichen Wert zu generieren, beginnen Märkte natürlich um Folgendes zu entstehen:
* Beitragsqualität
* Attribution
* Herkunft
* Ruf
* Lizenzierung
* Einflussgewichtung
Und sobald sich diese Märkte bilden, hört das Trainingsmaterial auf, sich wie kostenloses Rohmaterial zu verhalten.
Es beginnt sich wie produktives Kapital zu verhalten.
Das ist ein völlig anderes Rahmenwerk für die KI-Ökonomie.
Je mehr ich darüber nachdenke, desto mehr glaube ich, dass dies eine der wichtigsten strukturellen Veränderungen in der KI insgesamt werden könnte.
Denn die Internetökonomie hat historisch die Aufmerksamkeit extrem effizient monetarisiert, während sie es völlig versäumt hat, den Beitrag zur Intelligenz fair zu monetarisieren.
OpenLedger experimentiert mit einer Zukunft, in der die Intelligenz selbst finanziell koordiniert wird.
Das schafft etwas viel Interessanteres als einfache 'Datenmonetarisierung'.
Es schafft wiederkehrende Teilnahmeökonomien rund um maschinelle Intelligenz.
Und ehrlich gesagt, ich denke, das ist der Teil, den die meisten Leute noch nicht vollständig verarbeitet haben.
Wenn Attributionssysteme ausreichend ausgeklügelt werden, um den nachgelagerten Einfluss genau zu messen, hören wertvolle Datensätze auf, passive Archive zu sein.
Sie werden zu ertragsbringender Infrastruktur.
Das ist ein massiver konzeptioneller Wandel.
Ein Datensatz verhält sich nicht mehr wie Speicher.
Es verhält sich wie produktives digitales Kapital.
Das ändert die Psychologie der Mitwirkenden sofort, denn jetzt besteht das Ziel nicht mehr darin, Informationen einmal hochzuladen und für immer zu verschwinden.
Das Ziel wird, langfristige Informationsrelevanz in sich entwickelnden Intelligenzsystemen aufrechtzuerhalten.
Das schafft stärkere Anreize für qualitativ hochwertige Beiträge, sauberere Datensätze, spezialisierte Expertise und domänenspezifische Intelligenzumgebungen.
Und im Laufe der Zeit könnten diese Systeme potenziell wertvoller werden als allgemeine Scraping-Modelle insgesamt.
Besonders in Branchen, in denen Vertrauen wichtig ist.
Gesundheitsversorgung. Finanzen. Recht. Forschung. Unternehmens-KI.
Diese Sektoren können nicht unbegrenzt auf unverifizierbaren Intelligenzpipelines operieren.
Letztendlich wird Herkunft zur obligatorischen Infrastruktur.
Und in dem Moment, in dem die Herkunft wirtschaftlich wertvoll wird, werden Attributionssysteme auch zur Marktinfrastruktur.
Deshalb denke ich, dass die Positionierung von OpenLedger viel wichtiger ist, als die meisten Leute derzeit realisieren.
Das Projekt versucht nicht nur, dezentrale KI-Tools zu entwickeln.
Es versucht, eine Wirtschaft zu schaffen, in der Trainingsdaten selbst ein beständiger finanzieller Teilnehmer werden, anstatt ein entsorgbarer Input zu sein.
Das ist eine völlig andere Vision, wie KI-Systeme sich entwickeln.
Und ehrlich gesagt, wenn dieses Modell funktioniert, gehen die Implikationen weit über Krypto-Narrative hinaus.
Denn die nächste Phase der KI könnte nicht darüber gehen, wer die größten Modelle besitzt.
Es könnte darum gehen, wer die stärksten Ökonomien rund um die Intelligenz selbst aufbaut.
