The AI market keeps pricing compute like it’s the source of intelligence itself.
It isn’t.
Compute scales the machine. Human contribution shapes the usefulness.
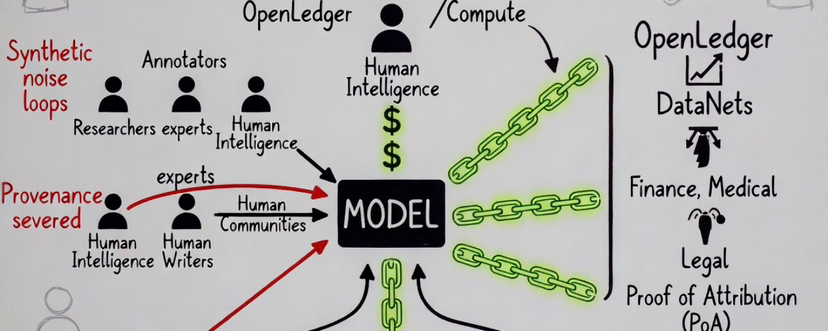
That layer stays mostly invisible because the current AI economy is designed to hide it. Models absorb intelligence from millions of contributors, compress it into weights, then erase the economic trail afterward.
Researchers refining niche datasets. Annotators fixing ugly edge cases manually. Developers writing open-source logic that later influences downstream model behavior. Entire online communities unknowingly feeding future AI systems just by existing on the internet long enough.
Then the model becomes valuable.
The contributors disappear.
That’s basically the architecture of modern AI right now.
And honestly, I think the imbalance gets worse from here, not better.
The internet is already flooding with synthetic content. AI-generated material training newer AI systems. Machine-generated noise feeding more machine-generated noise. Everyone talks about scaling models while trusted human intelligence quietly becomes the scarce resource underneath the entire system.
That changes the economics completely.
Infinite information matters less.
Trusted signal matters more.
Most AI systems are not built for that shift. They optimize for scale by severing provenance after training finishes. Once the model absorbs the intelligence, the contribution layer becomes economically anonymous.
Efficient for scaling.
Terrible for coordination.
@OpenLedger is building around the opposite assumption:
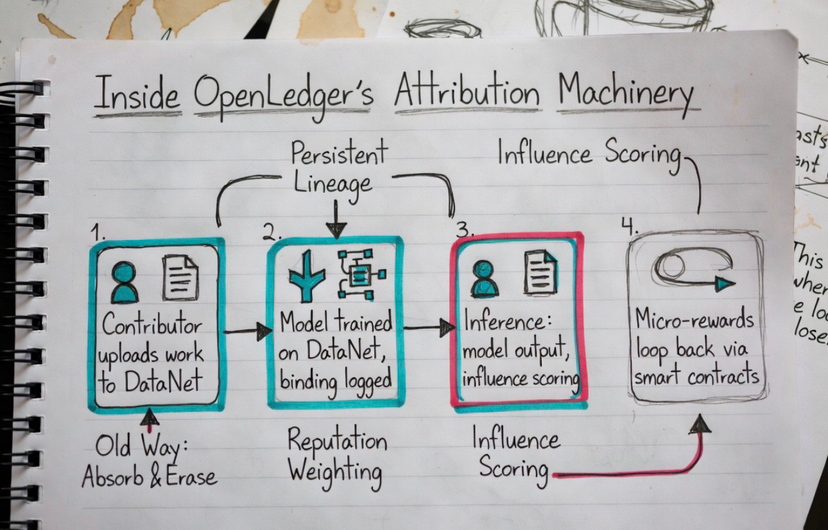
the intelligence trail should survive after training instead of dying inside the model.
That’s the actual point of DataNets.
Not “decentralized storage.” Not another AI wrapper.
DataNets keep contributor lineage attached to the intelligence layer itself. Metadata, provenance records, timestamps, attribution continuity, licensing logic, downstream influence tracking. The architecture is trying to stop intelligence from becoming economically detached from the people who produced it.
That changes incentives immediately.
Right now most datasets behave like disposable fuel tanks. Feed information into the model, burn through it during training, extract the value, move on.
OpenLedger treats datasets more like living economic environments.
Very different thing.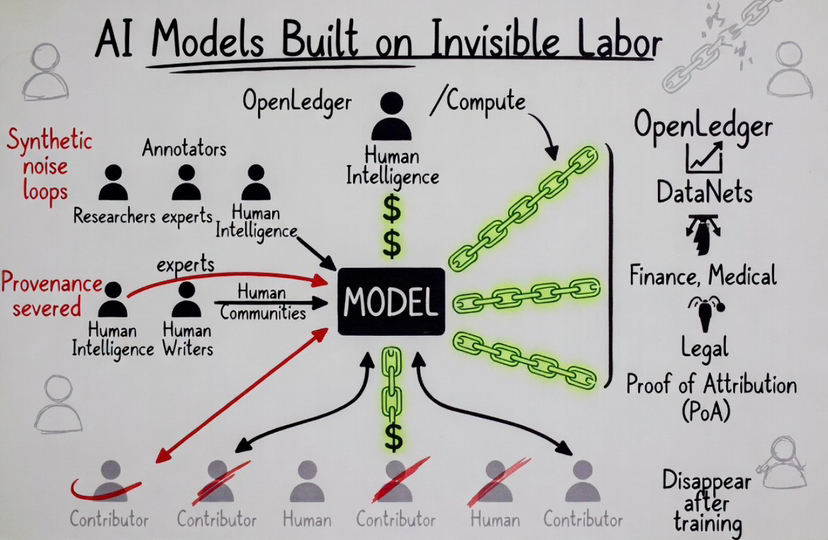
Once attribution continuity survives downstream, contribution quality starts compounding across the network itself. Trusted expertise becomes more valuable than raw information volume. Reputation persists longer. High-signal contributors stop behaving like temporary suppliers feeding black-box systems.
The system starts rewarding precision differently.
That’s important because the current AI economy mostly rewards extraction efficiency. The cleaner the model abstraction becomes, the less visible the intelligence suppliers become underneath it.
OpenLedger is attacking that break directly.
And honestly, this is why the project sits in a very different category from most AI narratives floating around crypto right now.
The market is crowded with:
compute plays
inference narratives
AI agents
automation tooling
consumer wrappers
OpenLedger is much lower in the stack.
It’s building around attribution persistence itself.
That sounds niche until you think about where AI systems are heading next.
AI agents are already moving into:
research generation
workflow automation
financial coordination
decision systems
market intelligence
All of that intelligence still originates somewhere.
That “somewhere” becomes economically important once machine systems start controlling larger amounts of value.
Current AI pipelines are not designed well for that future because invisible labor only scales cleanly while nobody asks where the intelligence came from.
That phase is ending.
 Copyright fights are increasing. Enterprises care more about provenance. Synthetic dataset contamination keeps getting worse. Black-box systems are becoming harder to defend in high-trust industries.
Copyright fights are increasing. Enterprises care more about provenance. Synthetic dataset contamination keeps getting worse. Black-box systems are becoming harder to defend in high-trust industries.
The pressure is already visible.
Most projects still treat attribution like optional metadata sitting outside the model economy.
OpenLedger treats attribution continuity like infrastructure.
Big difference.
The architecture is not trying to maximize information volume endlessly. It’s trying to preserve trusted intelligence lineage across evolving AI systems without letting the contributor layer vanish completely after training cycles finish.
That changes the structure of the network itself.
Now:
trusted datasets strengthen over time
contributor reputation compounds
provenance becomes economically valuable
high-signal environments outperform noisy scale systems
The coordination layer improves because the intelligence trail survives.
And honestly, I think this becomes one of the defining infrastructure shifts in AI over the next few years.
The internet became extremely efficient at monetizing attention while contributors stayed mostly replaceable underneath the system. AI inherited the same structure, except now machine intelligence scales globally and the value concentration becomes exponentially larger.
That’s why invisible labor matters here.
The current AI economy depends heavily on intelligence suppliers remaining disconnected from downstream value creation after training happens.
OpenLedger is building around a future where that disconnect no longer holds.
Not louder AI narratives.
Not speculative automation hype.
A system where intelligence contributors stop disappearing from the value chain the moment the models become profitable.
