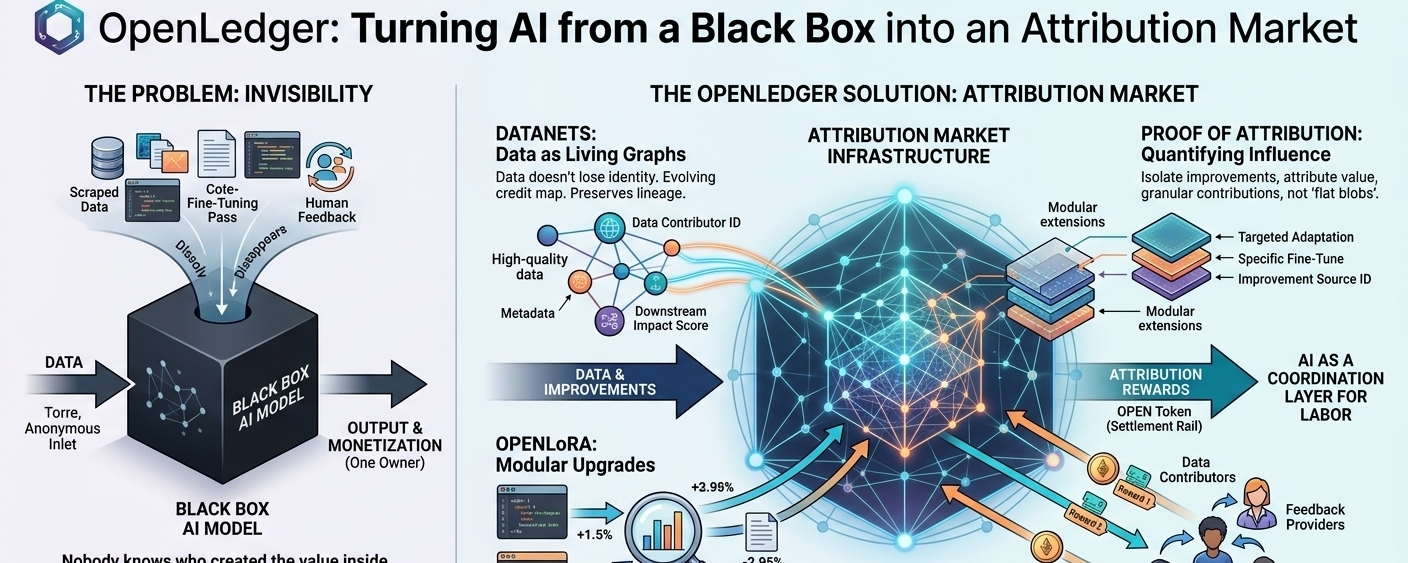
OpenLedger starts from an uncomfortable truth most AI stacks quietly ignore: nobody really knows who created the value inside a model. Data gets scraped, models get trained, and output gets monetized. The money flow is clean. The contribution graph isn’t.
That gap is where OpenLedger positions itself.
Not as “another AI chain,” but as infrastructure that tries to attach economic identity to every useful fragment of input inside an AI system.
The real problem isn’t AI quality. It’s invisibility.
AI already works. That’s not the issue. The issue is attribution.
Right now, if a dataset improves a model, or a fine-tune pass sharpens reasoning, or human feedback corrects drift—none of that is cleanly traceable in economic terms. Everything dissolves into the final model. One ownership layer captures the upside. Everyone else becomes background noise.
OpenLedger attacks that structure directly.
It treats AI systems like networks of influence rather than monolithic products. Every improvement has a source. Every output has a lineage. The goal is to stop pretending those things are unknowable.
Proof of Attribution changes what “training data” even means
The core mechanism behind this is Proof of Attribution.
It’s not just logging data usage. It’s trying to quantify influence—which inputs actually moved model behavior in a measurable way.
That distinction matters more than it sounds. Most systems assume contribution is uniform. OpenLedger rejects that entirely. Some data barely matters. Some data shifts everything. The system is built to separate the two and assign weight accordingly.
Once you can measure influence, you can pay for influence. That’s the pivot.
And that’s where the economics start to get interesting.
Datanets: data that doesn’t lose its identity
Traditional datasets are static. You dump them, train on them, forget them.
Datanets flip that model. They behave more like living graphs than files.
Data isn’t just stored—it’s continuously aggregated with metadata that preserves who contributed what and how it affected downstream performance.
So instead of a dataset being a dead object, it becomes a kind of evolving credit map. Contributions don’t disappear after ingestion. They persist through every training cycle that follows.
That alone changes incentive design. Suddenly, being early and being high-quality both matter.
OpenLoRA and why full retraining is dead weight
Full model retraining is expensive, slow, and increasingly unnecessary.
OpenLoRA leans into that reality. Instead of rebuilding models from scratch, it layers targeted adaptations on top of existing systems.
Think modular upgrades instead of monolithic rebuilds.
The deeper implication is economic: if you can isolate which fine-tune actually improved performance, you can attribute value to that specific change. That means contributions become granular again—data, tweaks, feedback loops—all independently rewarded instead of flattened into a single training blob.
Less waste. More traceable causality.
ModelFactory: lowering the barrier just enough to explode participation
ModelFactory is the entry layer.
It abstracts away most of the machine learning complexity. Not because the complexity isn’t real, but because OpenLedger benefits from widening the contributor base.
More builders. More datasets. More fine-tunes. More attribution edges to track.
This is where the system starts to resemble a production network rather than a research lab. The output isn’t just models—it’s continuous micro-contributions feeding a larger attribution economy.
The token layer is just the accounting system
OPEN and gOPEN aren’t positioned as narrative assets. They function more like settlement rails.
OPEN handles the operational flow: inference payments, model hosting, attribution rewards, and proposal fees. gOPEN sits closer to governance—who decides how attribution rules evolve, how rewards are tuned, and how the system expands.
The important part isn’t the token design itself. It’s what it enables: a closed loop where contribution → measurement → reward is enforced at protocol level rather than left to platform discretion.
The flywheel everyone is actually trying to build
Once you strip away the branding, the structure is pretty clear:
Data comes in through Datanets.
Models get adapted via OpenLoRA.
Influence gets measured through Proof of Attribution.
Rewards flow back in OPEN.
More contributors enter because the system finally pays attention to them.
Then it repeats.
If it works, OpenLedger stops being “a project” and starts behaving like a coordination layer for AI labor itself.
Not glamorous. Just structurally efficient.