
been trecking Open core protocol architecture for the past two weeks and honestly? the thing most people are discus1ng — token price, exchange listings, staking yields — isn't even the real story 😂
the real story is Proof of Attribution. and almost nobody is expl4ining what it actually does at the mechanic level.
the number that started this whole thread
AI is a 500 billion dollar industry built entirely on uncompensated data. every large language model trained by every major technology corporation used data harvested from creators, researchers, writers, and communities who received precisely zero in return. no payment. no credit. no audit trail. the data disappeared into a black box and came out as someone else's product worth billions.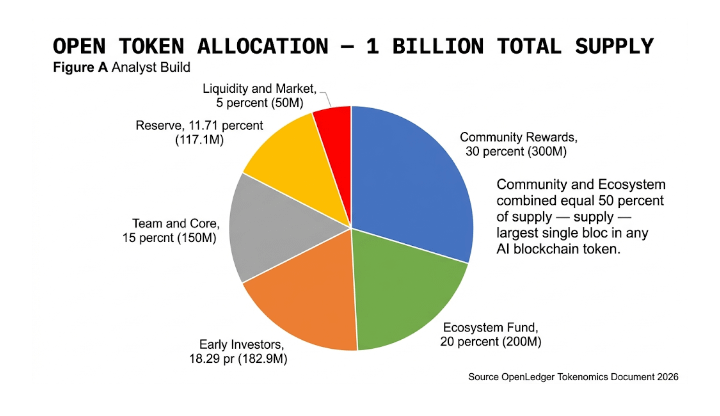
OpenLedger's Proof of Attribution is a consensus mechanism that cryptographically links every AI output back to its original training data on-chain. this is not a dashboard feature or an analytics tool bolted on top. it is built into the protocol layer itself meaning it cannot be removed, manipulated, or selectively applied. every model trained on OpenLedger carries an immutable on-chain record of which data contributed to which output. for the first time in AI history, attribution is not a promise. it is a mechan1c.
the architecture nobody is breaking down
OpenLedger operates as a native Layer 1 blockchain optimized specifically for AI workloads. three components make the full system work together. Datanets are collaborative on-chain data layers where communities build structured attributed datasets. when a developer uses that data to train a model, the Datanet contributors are automatically paid in $OPEN tokens through smart contract execution. no invoice. no platform approval. no delay. payment triggers on data access.
ModelFactory is the second layer. it is a no-code and low-code tool that lets anyone train Specialized Language Models and publish them directly on-chain. once live, that model becomes what OpenLedger calls a Payable AI Model — a smart contract that automatically distributes royalopen ties to the builder based on usage metrics, relevance, and performance every single time the model receives a query. a researcher in Lagos builds a domain-specific medical diagnosis model. every hospital system, developer, or application that queries that model sends automatic payment back to that researcher with zero intermediary taking a cut.
OpenLoRA is the third layer and the one that makes this economically viable at scale. by implementing Low Rank Adaption techniques at the protocol level, OpenLoRA reduces AI inference costs by up to 99% compared to traditional deployment approaches. that cost reduction is not a marketing claim. it is the structural reason why small developers, independent researchers, and emerging market builders can actually participate in the AI economy on OpenLedger when they would be completely priced out of building on centralized infrastructure.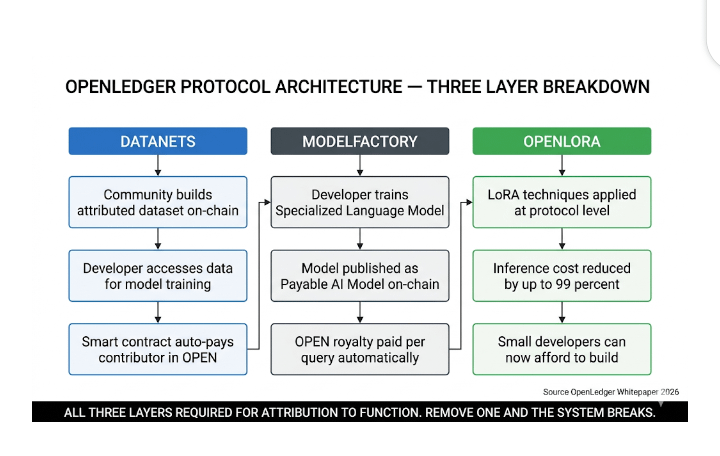
what the market hasn't pr1ced in yet
$OPEN launched at TGE in August 2025 with 215.5 million tokens liquid representing 21.55% of the 1 billion total supply. current circulating supply sits at approximately 290 million tokens. the community rewards allocation — the largest single category at 30% of total supply — is unlocking linearly over 48 months. this means 3.2 million OPEN tokens per month are flowing to actual data contributors and model builders who are using the network. not to speculators. not to insiders. to protocol participants doing real work.
the Ecosystem Fund at 20% of supply is funding OpenCircle — the incubation program that has already begun supporting early stage AI and blockchain projects with grants and infrastructure access. each new project that launches on OpenLedger through OpenCircle adds another application layer that requires for open as, governance, and model payments. this is compounding network demand that is not visible in the daily price chart but is building structurally with every new protocol that joins.
where the logic gets tested
here is the part i keep coming back to. OpenLedger is building infrastructure for a market that is simultaneously the largest technology opportunity in history and the most heavily contested. Google, Microsoft, Meta, and Amazon are not going to hand their AI infrastructure budgets to a decentralized Layer 1 without significant enterprise adoption first. the roadmap acknowledges this enterprise partnerships and regulatory compliance tooling are Phase 4 and Phase 5 priorities meaning they are planned but not yet delivered.
the on-chain governance activation is still listed as in progress in the Phase 4 roadmap. the Agent Economy launch — autonomous AI agents transacting on-chain — is marked as planned. these are not failed milestones. they are simply not yet real. and the thesis that OpenLedger becomes the foundational layer for the AI economy depends heavily on execution speed against well-funded centralized competitors who are not standing still.
what actually makes this different
99% inference cost reduction through OpenLoRA is not theoretical. it is demonst4ated at the protocol level meaning any developer can verify it by running inference comparison. the immutability of the on-chain attribution record means a data contributor's rights are not subject to any company's terms of service change, any platform policy update, or any corporate acquisition. the record is permanent. that is a property that no centralized AI platform can truthfully claim regardless of how many transparency reports they publish.
the immutability of the on-chain attribution record means a data contributor's rights are not subject to any company's terms of service change, any platform policy update, or any corporate acquisition. the record is permanent. that is a property that no centralized AI platform can truthfully claim regardless of how many transparency reports they publish.
honestly don't know if OpenLedger becomes the global standard for AI attribution or remains an important but niche infrastructure layer that the enterprise market takes another cycle to discover 🤔
what's your take — Proof of Attribution becomes the industry standard or does centralized AI move too fast for decentralized infrastructure to c4tch up??