I’m going to speak about this from a place that feels personal, not mechanical, because when we talk about artificial intelligence and blockchain together, we are not just discussing code and tokens, we are discussing power, ownership, fairness, and the future of digital work. OpenLedger (OPEN) positions itself as an AI-focused blockchain designed to unlock liquidity so data, models, and intelligent agents can be monetized transparently, and the more I study the idea, the more I realize that it is attempting to fix something that has been quietly broken for years. They’re building infrastructure for a world where data is not just consumed but credited, where models are not mysterious black boxes but traceable economic assets, and where participation in AI development can become financially meaningful instead of invisible.
To understand why this matters, we first have to understand the current imbalance. Artificial intelligence systems are trained on enormous volumes of data. That data comes from humans, from public information, from structured datasets, from creative work, from conversations, from code repositories, from research papers. Yet the people who indirectly fuel these systems rarely share in the economic rewards once those systems become profitable. If a model becomes extremely successful, the value usually flows to the company operating it. It becomes centralized value built on decentralized contributions. That contradiction is the core tension OpenLedger is trying to address.
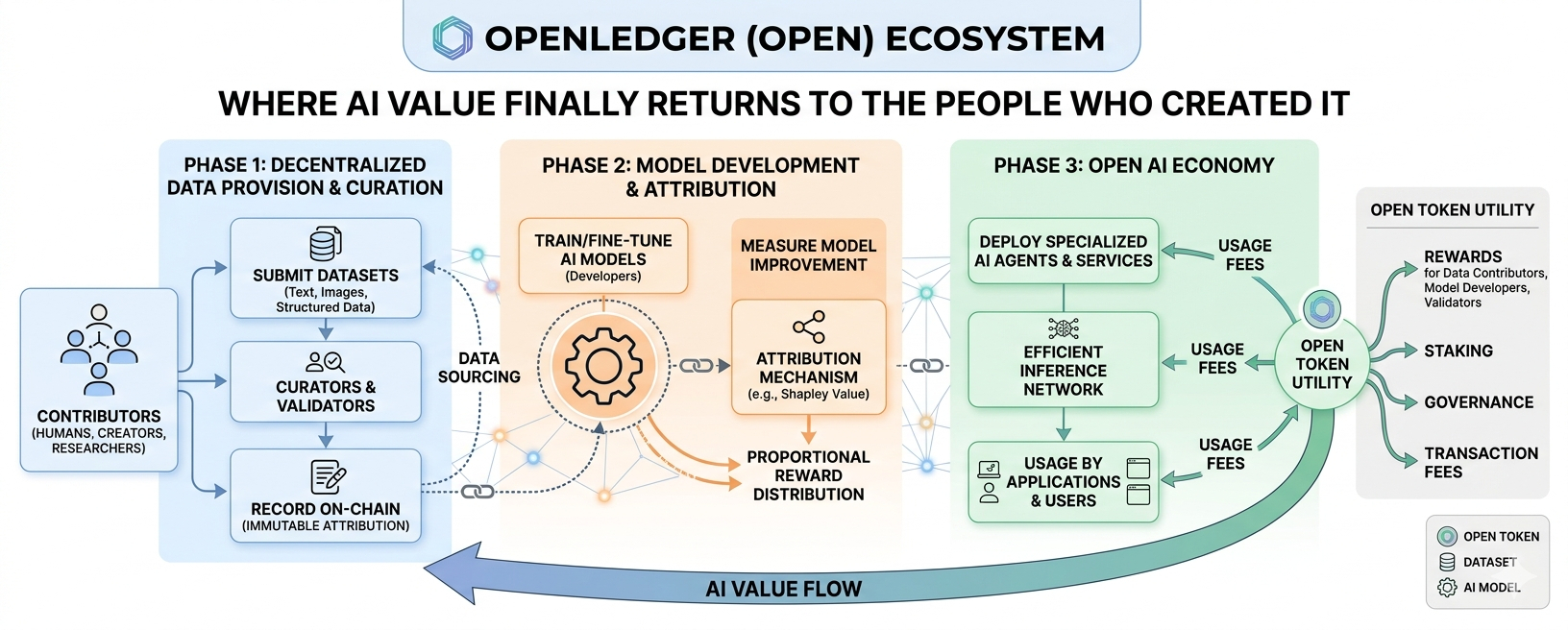
OpenLedger is built as a blockchain infrastructure specifically optimized for AI-related assets. Instead of focusing only on financial transactions like traditional decentralized finance networks, it focuses on turning AI components into on-chain economic objects. Data is not just data anymore. A trained model is not just software anymore. An AI agent is not just an application anymore. In this ecosystem, each of these elements can be recorded, attributed, and monetized in a structured and programmable way. That is a significant shift because it transforms intangible digital contributions into trackable economic units.
The system works in layered stages. First, there are decentralized data networks where contributors can submit datasets. These datasets can include text, structured information, labeled images, or domain-specific knowledge. Once submitted, contributions are recorded on-chain so they cannot be quietly replaced or erased. This matters because attribution is only meaningful if it is transparent and immutable. If your dataset helps train a valuable AI model, the system must be able to prove that your contribution existed and that it played a measurable role.
Next comes the model development stage. Developers can train or fine-tune AI models using datasets sourced from the network. What makes this different from traditional model training is that the process is connected to an attribution mechanism. The protocol attempts to measure how much each dataset improves model performance. This idea, often referred to as proof of attribution, is essential to the entire design. If the system can measure the impact of specific data inputs on model outputs, it can distribute rewards proportionally. If it becomes accurate and scalable, this could fundamentally change how AI value is distributed.
After models are trained, they can be deployed in a way that supports efficient inference. Instead of running heavy models inefficiently, the system aims to optimize deployment so multiple specialized models can operate effectively across shared infrastructure. This is important because cost efficiency determines accessibility. If only large corporations can afford to deploy models, decentralization fails in practice. But if deployment is optimized and accessible, smaller teams and independent builders can participate. We’re seeing a gradual shift in AI where specialized models outperform general ones in niche tasks, and OpenLedger’s structure seems aligned with that trend.
The OPEN token plays a central role in coordinating this ecosystem. It is used for transaction fees, staking, governance participation, and rewarding contributors. When someone uploads data, trains a model, validates network activity, or participates in maintaining the system, OPEN can function as compensation. This creates an incentive loop. Contributors are motivated to provide high-quality data because better data leads to better models, and better models generate more usage. Increased usage leads to more fees and reward distribution. If designed properly, this cycle can reinforce quality rather than noise.
Liquidity is one of the most interesting concepts in this system. When people say OpenLedger unlocks liquidity for data and models, they mean that previously static digital assets can become tradable or yield-generating. A dataset can contribute to multiple models. A model can power multiple agents. An agent can serve multiple users. Each interaction can generate economic value that flows back through the attribution chain. This is not simple to implement technically, but conceptually it is powerful. It means value is not captured at a single point but distributed across a network of contributors.
I think the emotional core of this idea is fairness. For years, digital participation has been extractive. Users create content. Platforms monetize attention. AI companies train on publicly available information. Most contributors never receive direct compensation. OpenLedger is proposing a different structure where transparency is embedded at the protocol level. Instead of trusting corporations to share profits voluntarily, the rules are encoded in smart contracts. Rewards flow automatically based on measurable impact. That automation reduces dependency on goodwill and replaces it with programmable fairness.
Of course, this vision faces real challenges. Measuring the exact contribution of a dataset to a model’s performance is not trivial. AI systems are complex and nonlinear. Small data variations can have unpredictable effects. There is also the question of quality control. If rewards are tied to contribution, people might try to game the system by uploading redundant or low-quality data. The network must incorporate validation mechanisms and economic disincentives for manipulation. Governance will play a role here, and token holders may influence how parameters evolve over time.
We’re seeing increasing discussion globally about data ownership, AI ethics, and decentralization. Governments are exploring regulation. Developers are exploring open-source alternatives. Users are becoming more aware of how their information is used. In that context, OpenLedger feels like part of a broader movement rather than an isolated experiment. It aligns with the idea that digital infrastructure should reflect human contribution rather than obscure it.
Another important aspect is interoperability. For any blockchain project to succeed, it must connect with broader ecosystems. Liquidity, exchange access, and integration matter. Availability on major platforms like Binance increases exposure and accessibility, which can help bring participants into the network. However, exchange listings alone do not create value. Sustainable value comes from real usage, real builders, and real contributors who believe the system benefits them.
From my own perspective, the most compelling part of OpenLedger is not the token price potential or speculative upside. It is the structural attempt to rebalance power in the AI economy. I’m not saying it will succeed easily. I’m not saying technical challenges will disappear. But the direction feels meaningful. If it becomes standard practice that datasets are traceable and rewarded, that model training is transparent, and that contributors share in downstream value, then AI development could feel less extractive and more collaborative.
They’re not just building another blockchain. They’re trying to build economic rails for the intelligence economy. If that vision matures, it could encourage a new generation of data contributors, researchers, and developers who know that their work will not vanish into a corporate black box. Instead, it will live on-chain, attributed, recognized, and rewarded.
When I think about the future of AI, I imagine two paths. One path concentrates power into fewer hands, where intelligence systems are controlled by centralized entities and economic value remains tightly held. The other path distributes ownership, transparency, and reward mechanisms across communities. OpenLedger clearly aligns with the second path. Whether it reaches full realization depends on adoption, execution, and resilience. But the ambition itself is significant.
At its heart, this is about restoring balance. Data has value because humans create it. Models have value because humans design and train them. Agents have value because humans deploy them to solve real problems. If blockchain technology can ensure that the people behind these layers are compensated fairly and transparently, then we are not just upgrading infrastructure. We are upgrading trust.
I believe the next phase of the digital economy will revolve around ownership clarity. People will ask deeper questions about where value flows and why. Systems that answer those questions transparently will earn loyalty. Systems that ignore them may struggle. OpenLedger stands at that crossroads, attempting to build a framework where intelligence is not only artificial but economically accountable.
In the end, what moves me most is the possibility that technology can evolve toward fairness rather than away from it. If contributors feel seen, if creators feel valued, if developers feel empowered, then the AI revolution will not feel like something happening to us but something we are building together. And if we are building it together, with transparency and shared reward, then the future of AI will not just be powerful. It will be human.
