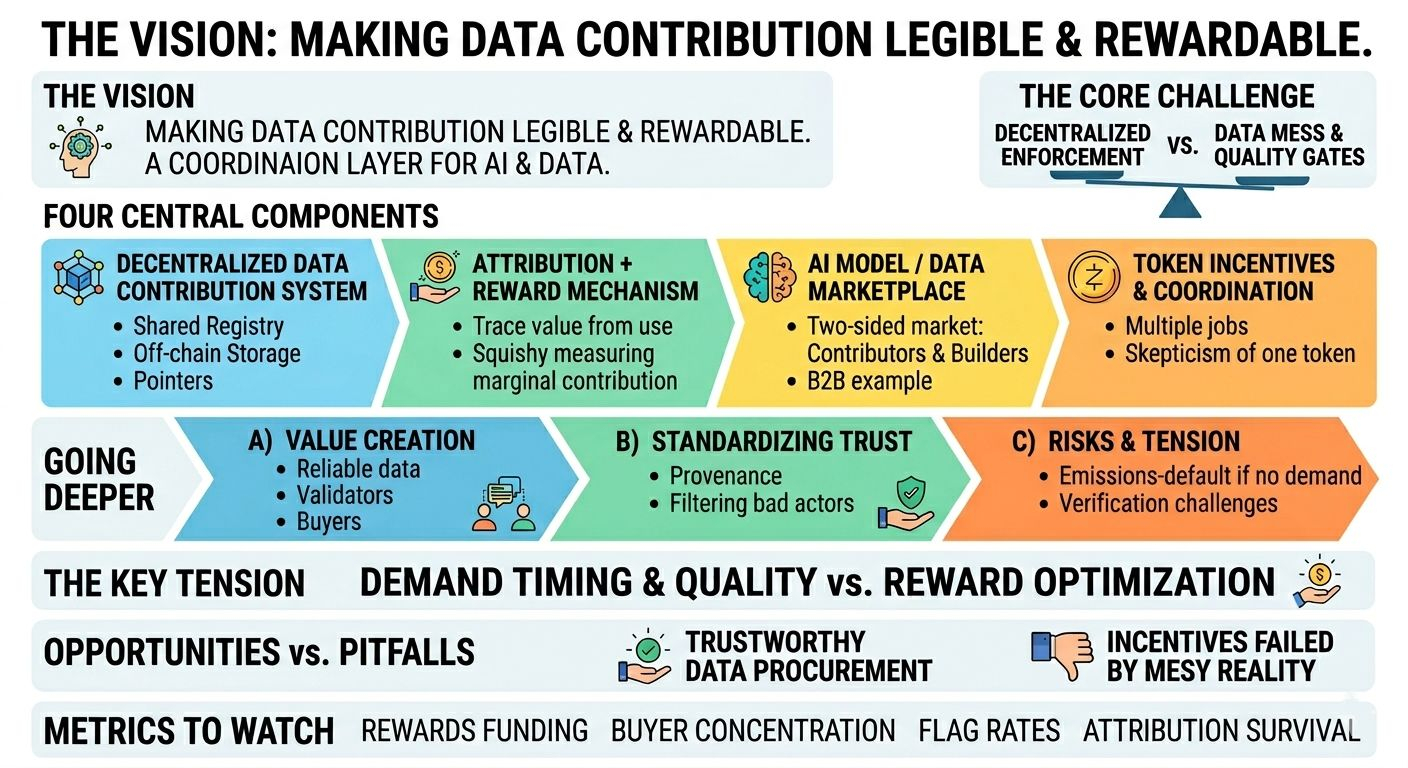
Been going through openledger (open) this week, mostly trying to map the “decentralized ai data infrastructure” story onto something that could actually hold up under real usage. what caught my attention is that the project isn’t only talking about hosting datasets or spinning up a marketplace—it’s trying to make “who contributed what” legible enough that money can flow back to contributors when models train or serve inferences. that’s a harder problem than people make it sound.
most people think openledger is just another ai + crypto token with a data marketplace attached. honestly, if you stop there, it’s easy to dismiss: “users upload data, token rewards happen, models get trained.” but the interesting part is the attempt to turn data contribution + attribution into an economic coordination layer that could sit underneath multiple model builders and apps, not just one centralized platform.
a few components seem central:
decentralized data contribution system
from what i can tell, openledger’s design leans on contributors pushing data (and maybe labels / annotations) into a shared registry, with the bulk storage off-chain and some on-chain representation (hashes, metadata, pointers, maybe licenses). the long-term design question is whether the protocol can enforce consistent schemas and quality gates without becoming de facto centralized via “approved curators.” data is messy; networks love clean abstractions.attribution + reward mechanism
this is the part i keep thinking about. attribution implies you can trace value from model usage back to training inputs (or at least to a dataset tranche). in practice, training runs are opaque, mixes are proprietary, and even when you know what went in, measuring marginal contribution is… squishy. maybe openledger uses dataset-level accounting (you used dataset x, therefore x gets paid) rather than true per-record contribution. that’s more realistic, but it shifts power toward whoever defines dataset boundaries and negotiates “what counts as used.”ai model / data marketplace dynamics
openledger seems to want a two-sided market: contributors supply data; model builders and app teams demand it (and possibly sell models through the same rails). a realistic example: imagine a small robotics team that needs warehouse pick-and-place videos plus bounding-box labels. they can’t easily buy that from the usual centralized sources, so they source it via openledger, train a model, then offer inference access with revenue sharing back to the dataset providers. that’s coherent—if the demand is there and if buyers trust the provenance.token incentives + network coordination / verification
the token side looks like it’s doing multiple jobs: paying contributors, coordinating validation, possibly staking/slashing to deter spam, and maybe acting as the unit for marketplace settlement. i’m a bit skeptical of “one token does everything,” but i get the motivation: you need a shared accounting system to make cross-party payments composable.
going deeper: who creates value here? not “the chain,” but (a) contributors who can reliably produce scarce data, (b) curators/validators who make that data usable, and (c) buyers who bring real cashflow by training models or running inference. the protocol’s bet is that the network can standardize trust: attribution stays trustworthy because data has provenance (timestamps, signatures, hashing), and because bad actors get filtered out via staking and reputation. still, trust at scale tends to drift toward a few entities running the best validation infrastructure.
the tension i keep coming back to is demand timing. if meaningful ai buyers don’t show up soon enough, incentives default to emissions. then you get the classic failure mode: contributors optimize for rewards, not usefulness—spam, duplicated data, synthetic junk, “label farms” pushing low-signal annotations. and even if demand shows up later, will the network be able to unwind early low-quality inventory without political fights?
also: attribution systems are easier to describe than to operationalize. buyers may not want to disclose training recipes; model builders might route around on-chain reporting; and the protocol may end up relying on “honest reporting + audits,” which is fine, but it’s not the same as hard verification.
no perfect conclusion yet. it might become a sustainable coordination layer, or it might be token incentives stapled onto an infrastructure story before the market is ready.
watching:
% of rewards funded by real buyer payments vs token emissions
buyer concentration (are there many small buyers or just a couple whales)
data rejection/flag rates and how often validators disagree
evidence that attribution survives adversarial behavior (not just demos)
if openledger succeeds, i think it’s because it makes trustworthy data procurement boring and cheap. if it fails, it’s probably because attribution + incentives don’t survive the messy reality of model training. the question i’m left with: can they keep the system open while still enforcing quality strongly enough that serious model teams actually rely on it?