
KI entwickelt sich so schnell, dass es manchmal so scheint, als würden alle nur über den oberflächlichen Trend sprechen. Neue Agenten, neue Modelle, schnellere Inferenz, größere Datensätze, mehr Automatisierung, mehr "KI-gesteuerte" Dinge. Aber je tiefer ich in diesen Sektor eintauche, desto mehr habe ich das Gefühl, dass der wahre Kampf nicht nur darum geht, wer die intelligenteste KI baut.
Der wahre Kampf dreht sich darum, wer den Wert besitzt, den KI schafft.
Deshalb hat OpenLedger meine Aufmerksamkeit erregt. Für mich ist $OPEN nicht nur ein weiterer KI-Token, der versucht, den aktuellen Markttrend zu reiten. OpenLedger versucht, ein viel größeres Problem innerhalb der KI-Wirtschaft zu lösen: Daten, Modelle, Agenten und menschliche Mitwirkende tragen alle zur Schaffung von Wert bei, aber meistens fließen die Belohnungen nur zu zentralisierten Plattformen.
OpenLedger verfolgt einen ganz anderen Ansatz. Ziel ist es, den Wert von KI nachvollziehbar, zuordenbar und belohnbar zu machen. Die Infrastruktur basiert auf Datanets, dem Nachweis der Urheberschaft und einer KI-nativen Blockchain. Hier können Mitwirkende Daten bereitstellen, Entwickler spezialisierte KI-Modelle starten und das Netzwerk nachverfolgen, welche Eingaben tatsächlich zu einem KI-Ergebnis beigetragen haben. Die Dokumentation von OpenLedger beschreibt Datanets als dezentrale Datennetzwerke, die domänenspezifische Datensätze für das KI-Training aggregieren, validieren und verteilen.
Warum sich OpenLedger anders anfühlt als der übliche KI-Hype
Viele Krypto-KI-Projekte sprechen von Dezentralisierung, doch viele wirken, als würden sie lediglich Token um einen bestehenden KI-Trend herum aufblähen. OpenLedger ist da interessanter, weil es nicht nur fragt: „Wie bringen wir KI auf die Blockchain?“, sondern etwas viel Wichtigeres:
Wie können wir die Eigentumsverhältnisse an KI sichtbar machen?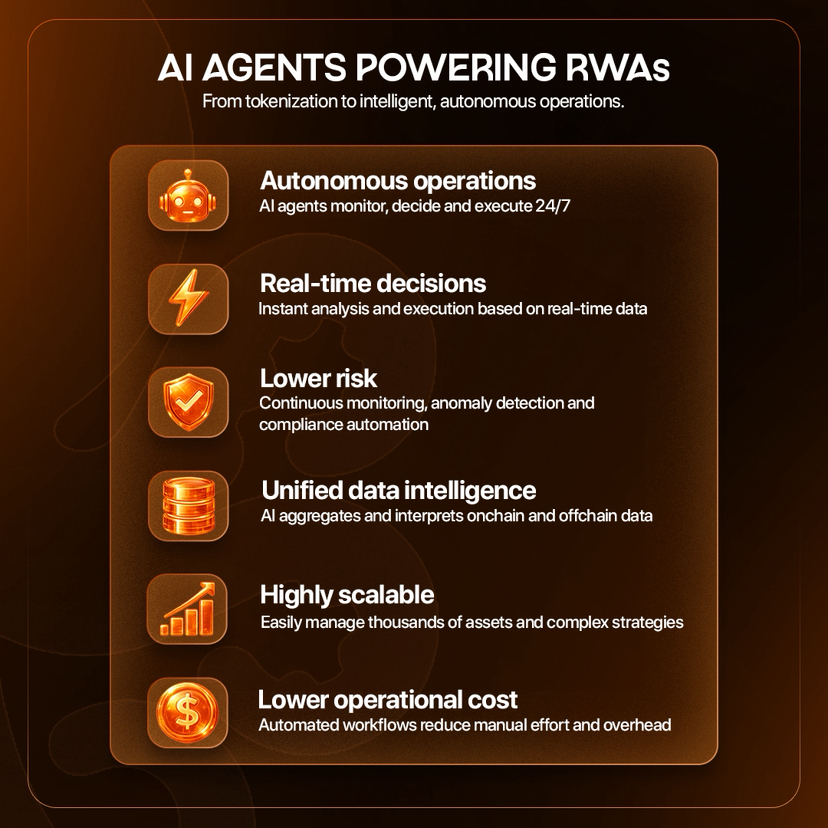
Aktuell werden KI-Modelle mit riesigen Datenmengen trainiert. Diese Daten stammen unter anderem von Entwicklern, Communitys, Nutzern, Forschern und aus öffentlichen Quellen. Sobald das Modell jedoch trainiert ist, verschwinden die Personen, die zur Entwicklung dieser Intelligenz beigetragen haben, in der Regel aus dem wirtschaftlichen Kreislauf.
OpenLedger versucht dies mit dem Nachweis der Datenzuordnung zu ändern. Dieser Nachweis verknüpft Datenbeiträge kryptografisch mit den Ergebnissen von KI-Modellen. Das ist wichtig, denn KI ohne Datenzuordnung wird zu einer Blackbox. Die Ergebnisse mögen zwar nützlich sein, aber niemand weiß genau, wer zu ihrem Wert beigetragen hat.
Und ehrlich gesagt glaube ich, dass hier der nächste große Kampf um die beste KI stattfinden wird. Nicht nur um die Geschwindigkeit. Nicht nur um die Modellgröße. Sondern um Herkunft, Rechte, Eigentum und Belohnungen.
Datanets verwandeln Daten in einen lebendigen wirtschaftlichen Vermögenswert
Das Datanets-Konzept ist für mich eine der größten Stärken von OpenLedger.
Normalerweise werden Daten wie Rohmaterial behandelt. Sie werden gesammelt, genutzt, zum Training verwendet und dann vergessen. OpenLedger verfolgt den Ansatz, Daten eher zu einem lebendigen Wirtschaftsgut zu machen. Über Datanets können Mitwirkende domänenspezifische Daten in das Netzwerk einbringen, die dann zum Trainieren spezialisierter KI-Modelle genutzt werden können.
Das ist wichtig, weil die Zukunft der KI nicht in einem einzigen, allumfassenden Modell liegen wird, das alle Fragen beantwortet. Ich denke, wir bewegen uns auf eine Welt spezialisierter KI-Modelle für Handel, Gesundheitswesen, Spiele, Rechtsanwendungen, risikogewichtete Konten (RWA), DeFi, Forschung, Kreativwirtschaft und Unternehmensprozesse zu.
Ein Modell zur RWA-Risikoanalyse benötigt andere Daten als ein Modell für Glücksspielagenten. Ein DeFi-Ausführungsmodell benötigt andere Signale als ein Modeempfehlungsmodell. Eine Volatilitätsprognose-Engine benötigt Echtzeit-Marktdaten, Liquiditätsverschiebungen, Finanzierungsbedingungen, Orderflow, makroökonomischen Druck und Risikosignale.
Deshalb sind die Datanets von OpenLedger so sinnvoll. Sie schaffen eine Struktur, in der Daten gesammelt, validiert, wiederverwendet und wirtschaftlich mit KI-Ergebnissen verknüpft werden können. Laut OpenLedgers Attributionsmodell können Mitwirkende zudem tokenbasierte Belohnungen erhalten, die auf dem Einfluss ihrer Daten auf die Modellergebnisse basieren.
Für mich ist dies eines der deutlichsten Beispiele dafür, wie KI und Blockchain tatsächlich sinnvoll miteinander verbunden werden können. Blockchain macht die KI nicht auf magische Weise intelligenter. Sie schafft vielmehr eine transparente ökonomische Ebene, die die Intelligenz umgibt.
Der Nachweis der Zuordnung ist die Kernidee hinter $OPEN.
Das eigentliche Herzstück von OpenLedger ist der Nachweis der Urheberschaft.
Vereinfacht ausgedrückt versucht der Nachweis der Zuordnung die Frage zu beantworten: Was hat tatsächlich zu diesem KI-Ergebnis beigetragen?
Das mag einfach klingen, ist aber ein sehr komplexes Problem. KI-Modelle funktionieren nicht wie herkömmliche Software, bei der jeder Output einem klar definierten Pfad folgt. Modelle lernen aus vielen Quellen, Gewichtungen ändern sich, Daten werden eingebettet, Agenten interagieren, und die Outputs werden von vielen verschiedenen Ebenen beeinflusst.
OpenLedger arbeitet an einem System, in dem diese Beiträge nachverfolgt und belohnt werden können. Die OpenLedger Foundation erklärt, dass der Nachweis der Zurechnung belohnt wird und dass die Attributions-Engine bei der Generierung von Ergebnissen durch ein Modell die Datenpunkte mit dem größten Einfluss ermittelt.
Hier wird $OPEN zu mehr als nur einem Börsenticker. Funktioniert das Netzwerk wie vorgesehen, ist $OPEN Teil des Belohnungs- und Nutzensystems für KI-Datenbeiträge, -Inferenz und -Attribution. Die Tokenomics-Dokumentation beschreibt $OPEN als den nativen Token der OpenLedger-KI-Blockchain und als Belohnungsmechanismus für Datenbeitragende durch den Nachweis der Zuordnung.
Das ist wichtig, weil viele KI-Token im Alltag wenig Nutzen bringen. Sie klingen zwar während eines Hype-Zyklus vielversprechend, aber der Token ist nicht immer in den eigentlichen Produktlebenszyklus eingebunden. Bei OpenLedger hingegen ist der Token direkt mit der Zuordnung von Beiträgen, Anreizen für Mitwirkende und der KI-Nutzung verknüpft.
Wo Volatilitätsprognose-Engines in dieses Bild passen
Hier wird die Idee von Volatilitätsprognose-Engines sehr interessant.
An den Märkten ist Volatilität nicht bloß Rauschen, sondern Information. Ein gutes Handelssystem sollte nicht nur fragen, ob der Kurs steigt oder fällt. Es sollte den aktuellen Marktzustand verstehen: ruhig, instabil, überkauft, risikofreudig, risikoscheu, komprimiert oder bereit für Expansion.
Volatilitätsprognose-Engines funktionieren wie Echtzeit-Marktzustandsklassifikatoren für Ausführungssysteme. Sie wandeln Unsicherheit selbst in eine messbare Eingangsgröße für risikobewusste Entscheidungen um. Anstatt sich nur auf statische historische Annahmen zu stützen, aktualisieren sie die Volatilitätserwartungen kontinuierlich auf Basis sich ändernder Marktbedingungen.
Dies knüpft sehr natürlich an OpenLedgers umfassendere KI-Infrastrukturidee an.
Stellen Sie sich spezialisierte KI-Modelle vor, die auf Marktverhalten, Liquiditätsveränderungen, Volatilitätsregime, Finanzierungsbewegungen, On-Chain-Transaktionen und Makrosignalen trainiert werden. Werden diese Modelle mithilfe von OpenLedger-ähnlichen Datennetzen erstellt, lassen sich die Daten hinter den Prognosen nachvollziehbar machen. Die Beitragenden, die wertvolle Marktdaten bereitgestellt haben, könnten mit den Ergebnissen dieser Modelle verknüpft werden.
Das verändert die gesamte Struktur.
Ein Volatilitätsmodell ist nicht länger nur ein geschlossener Algorithmus innerhalb eines privaten Handelssystems. Es kann Teil einer transparenten KI-Ökonomie werden, in der Datenqualität, Modellleistung und der Beitrag der Nutzer miteinander verknüpft sind. Für Händler, Protokolle und automatisierte Ausführungssysteme ist dies von Bedeutung, da Risikoentscheidungen intelligenter und nachvollziehbarer werden.
Genau diese Art von KI-Ebene braucht Krypto meiner Meinung nach. Nicht irgendwelche KI-Vermarktungsversuche, sondern eine praktische Infrastruktur, in der Modelle Risiken klassifizieren, Annahmen aktualisieren und die Ausführung in Echtzeit unterstützen können.
Warum KI-Agenten und RWAs die OpenLedger-These stärken
RWAs haben reale Vermögenswerte auf die Blockchain gebracht. Doch die Tokenisierung allein ist nicht das endgültige Ziel.
Die Speicherung von Vermögenswerten in der Blockchain ist nur der erste Schritt. Die größere Chance besteht darin, diese Vermögenswerte programmierbar, überwachbar und intelligent zu verwalten. Hier kommen KI-Agenten ins Spiel.
KI-Agenten können Anlagenzustände überwachen, Risiken verfolgen, Strategien aktualisieren, Anomalien erkennen, Compliance-Workflows verwalten und auf Basis von Echtzeitdaten Maßnahmen ausführen. Anstatt dass Menschen jede Variable manuell überwachen, können die Agenten kontinuierlich arbeiten.
Wenn also Leute sagen, dass es bei RWAs um Tokenisierung geht, dann ist das meiner Meinung nach nur die halbe Wahrheit.
Die Zukunft von RWAs geht über die Tokenisierung hinaus. Es geht um KI-gestützte Ausführung in großem Umfang.
Hier gewinnt die Architektur von OpenLedger noch mehr an Bedeutung. Wenn reale Vermögenswerte von KI-Agenten verwaltet werden sollen, benötigen diese Agenten vertrauenswürdige Daten. Sie benötigen verifizierte Eingaben. Sie benötigen eine Zuordnung der Datenquellen. Sie benötigen klare Aufzeichnungen darüber, welche Informationen eine Entscheidung beeinflusst haben.
Ein KI-System, das tokenisierte Vermögenswerte wie Treasury, Immobilien, Rechnungsbestände, Kreditprodukte oder Rohstoffpositionen verwaltet, kann nicht ewig mit unstrukturierten, intransparenten Daten arbeiten. Je höher die Summe, desto wichtiger wird die Herkunftsnachverfolgung.
Deshalb sehe ich einen starken Zusammenhang zwischen OpenLedger und der Zukunft von RWAs. OpenLedger ist zwar nicht direkt ein RWA-Projekt, aber seine KI-Attributionsschicht könnte die Art von Intelligenz unterstützen, die RWAs für eine sichere Skalierung benötigen.
Intent-basierte Architektur und DeFAI sind hier ebenfalls miteinander verbunden.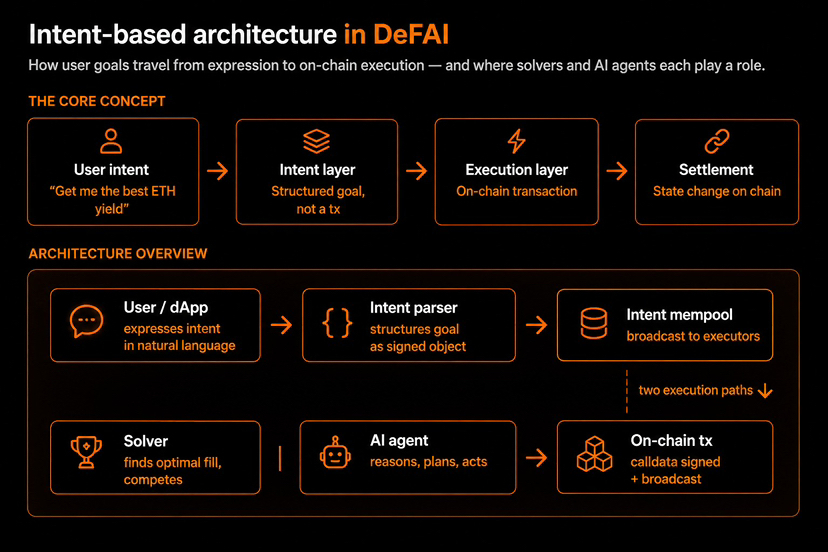
Ein weiterer Bereich, in dem die These von OpenLedger an Stärke gewinnt, ist DeFAI und die absichtsbasierte Architektur.
Die bisherige Krypto-Erfahrung war sehr umständlich. Nutzer mussten sich mit Bridges, Swaps, Liquiditätspools, Gasgebühren, Slippage, Genehmigungen, Staking, Renditerouten, Liquidationsrisiko und Transaktionseinstellungen auseinandersetzen. Das ist für normale Nutzer zu komplex.
Intentbasierte Systeme verändern die Nutzererfahrung. Anstatt der Blockchain jede kleine Aktion mitzuteilen, formuliert der Nutzer ein Ziel. Zum Beispiel: „Erziele die beste ETH-Rendite“ oder „Investiere mein Kapital in die sicherste Stablecoin-Strategie“. Anschließend übernehmen Solver oder KI-Agenten die Ausführung.
Hier zeigt die Architektur ihre Stärke: Die Benutzerabsicht gelangt in eine Absichtsschicht, wird strukturiert, an Solver oder KI-Agenten weitergeleitet, auf der Blockchain ausgeführt und schließlich als Zustandsänderung gespeichert.
Doch hier kommt der entscheidende Punkt: Wenn KI-Agenten Entscheidungen in DeFi- und RWA-Systemen treffen, gewinnt die Zuordnung der Daten noch mehr an Bedeutung. Wer hat die Daten bereitgestellt? Welches Modell hat die Empfehlung ausgesprochen? Welcher Agent hat die Transaktion ausgeführt? Welche Quelle hat die Strategie beeinflusst?
Ohne diese Transparenz kann DeFAI sehr schnell gefährlich werden. Automatisierung ohne Verantwortlichkeit ist kein wirklicher Fortschritt, sondern birgt lediglich ein höheres Risiko.
OpenLedgers Proof of Attribution passt perfekt in diese Zukunft, denn er bietet der KI-Ökonomie eine Möglichkeit, Beiträge zu erfassen und zu belohnen. In einer Welt, in der Agenten finanzielle Entscheidungen treffen, könnte diese Art von Infrastruktur unerlässlich werden.
Warum die Story Protocol-Verbindung wichtig ist
Ein weiterer aktueller Aspekt von OpenLedger, der meiner Meinung nach Beachtung verdient, ist die Arbeit mit dem Story Protocol.
Story Protocol und OpenLedger haben einen urheberrechtlich geschützten Standard für KI-Training vorgestellt, der die Verwendung geistigen Eigentums im KI-Training transparent macht und die automatische Vergütung von Urhebern unterstützt. Dies ist von Bedeutung, da KI-Daten gleichzeitig zu einem rechtlichen, ethischen und wirtschaftlichen Problem werden.
Urheber möchten wissen, ob ihre Arbeit genutzt wird. Entwickler wünschen sich sauberere Trainingsprozesse. Institutionen fordern mehr Transparenz. Regulierungsbehörden achten verstärkt darauf, wie KI-Modelle erstellt werden. Dies ist kein Nischenthema mehr.
Mit dem weiteren Wachstum von KI könnten rechtegeschützte Trainingsmethoden und transparente Urheberschaft deutlich an Bedeutung gewinnen. Das Engagement von OpenLedger in diesem Bereich trägt dazu bei, dass sich das Projekt besser auf die zukünftige Entwicklung der KI-Infrastruktur ausrichtet.
Für mich ist dies einer der Gründe, warum es sich lohnt, das Projekt jenseits des üblichen Hypes weiter zu beobachten. Es geht nicht nur um die Nachfrage nach KI, sondern auch um die damit verbundenen Eigentums- und Nutzungsrechte.
Das Risiko, das niemand ignorieren sollte
Die These von OpenLedger gefällt mir, aber ich glaube nicht, dass dies ein einfaches Problem ist.
Die Zuordnung von Daten im großen Maßstab ist extrem schwierig. KI-Modelle sind komplex. Der Einfluss von Daten ist nicht immer einfach zu messen. Beitragende könnten versuchen, Belohnungssysteme zu manipulieren. Minderwertige oder synthetische Daten können Störungen verursachen. Die Governance muss festlegen, wie Qualität beurteilt, wie Streitigkeiten beigelegt und wie sich das Netzwerk vor Manipulation schützt.
Dies ist besonders wichtig, wenn OpenLedger in Bereiche wie DeFAI, RWA-Automatisierung und Volatilitätsprognosen expandiert. Wenn KI lediglich Inhalte erstellt, können Fehler ärgerlich sein. Sobald KI jedoch Einfluss auf die Finanzabwicklung nimmt, werden Fehler kostspielig.
Deshalb hängt der langfristige Wert des Projekts nicht nur von der Aktivität, sondern auch davon ab, ob es Vertrauen aufbauen kann.
Ein Netzwerk, das beliebige Daten belohnt, genügt nicht. Es muss nützliche Daten belohnen. Ein Netzwerk, das KI-Agenten unterstützt, genügt nicht. Es muss verantwortungsbewusste Agenten unterstützen. Ein Netzwerk, das die Zuordnung von Daten erfasst, genügt nicht. Es muss die Zuverlässigkeit der Zuordnung auch unter Druck gewährleisten.
Dies ist die wahre Bewährungsprobe für OpenLedger.
Mein abschließender Blick auf OpenLedger und $OPEN
OpenLedger finde ich deshalb interessant, weil es sich an der Schnittstelle dreier großer Veränderungen befindet, die gerade stattfinden.
Erstens benötigt KI eine bessere Eigentümerstruktur und Zuordnung.
Zweitens bewegen sich DeFi und RWAs in Richtung Automatisierung.
Drittens benötigen die Agenten vertrauenswürdige Daten und transparente Ausführungsprotokolle.
OpenLedger versucht, die Infrastruktur für genau diese Zukunft aufzubauen.
Datennetze können spezialisierte Daten organisieren und monetarisieren. Der Nachweis der Zuordnung verknüpft Datenbeiträge mit KI-Ergebnissen und ermöglicht Belohnungen und Nutzen innerhalb des Ökosystems. Volatilitätsprognose-Engines zeigen, wie spezialisierte KI-Modelle risikobewusste Echtzeit-Ausführung unterstützen können. KI-Agenten demonstrieren, wie risikobewusste Vermögensverwaltungen (RWA) von einfacher Tokenisierung hin zu autonomen Finanzoperationen gelangen können.
Deshalb glaube ich, dass OpenLedger mehr ist als nur eine weitere KI-Erzählung.
Es geht nicht nur darum, KI auf der Blockchain zu entwickeln. Es geht darum, eine verantwortungsvollere KI-Wirtschaft aufzubauen, in der Daten, Modelle, Agenten, Entwickler und Mitwirkende alle Teil des Wertschöpfungsprozesses sein können.
Die Umsetzung wird natürlich entscheidend sein. Die Idee ist vielversprechend, aber letztendlich wird der Markt beurteilen, ob OpenLedger die Attribution skalieren, die Datenqualität aufrechterhalten, echte Entwickler gewinnen und eine nachhaltige Nachfrage nach $OPEN schaffen kann.
Aus narrativer und infrastruktureller Sicht arbeitet OpenLedger meiner Meinung nach an einer der wichtigsten fehlenden Ebenen der KI.
Denn die Zukunft der KI wird nicht nur in der Intelligenz liegen.
Es wird um Besitzverhältnisse gehen.
Es wird um die Zuordnung gehen.
Es wird um autonome Ausführung gehen.
Und es wird darum gehen, zu beweisen, woher der Wert tatsächlich kommt.
Deshalb behalte ich @OpenLedger im Auge.