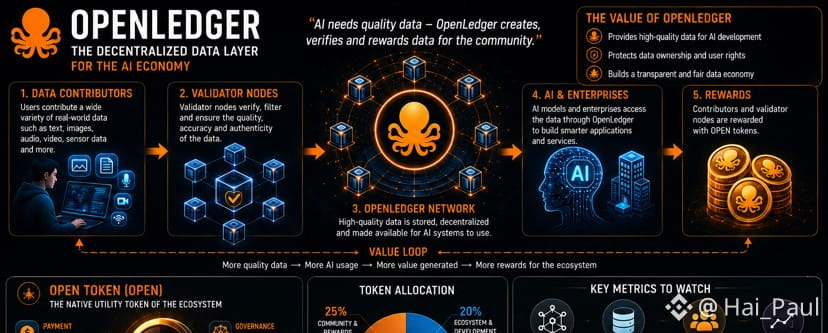
Nếu nhìn sâu hơn vào OpenLedger (OPEN), tôi cho rằng dự án này đang đi vào một “khoảng trống” khá thú vị trong hệ sinh thái AI + Web3, đó là lớp hạ tầng dữ liệu.
Hiện tại, phần lớn các narrative AI trong crypto tập trung vào hai hướng chính : xây dựng mô hình (model) hoặc tối ưu hóa tính toán (compute). Nhưng thực tế, một trong những bottleneck lớn nhất của AI lại nằm ở data, cụ thể là data chất lượng cao, có thể xác minh và được cập nhật liên tục.
OpenLedger tiếp cận bài toán này bằng cách xây dựng một mạng lưới phi tập trung, nơi người dùng có thể đóng góp dữ liệu, các node đảm nhiệm vai trò xác thực, và cuối cùng dữ liệu được cung cấp cho các hệ thống AI. Nếu mô hình này hoạt động hiệu quả, nó sẽ tạo ra một “data supply chain” hoàn chỉnh từ nguồn cung đến tiêu thụ.
So với Ocean Protocol, OpenLedger không chỉ dừng lại ở việc giao dịch dữ liệu, mà còn đi sâu vào quá trình tạo và kiểm định data. So với Fetch.ai, dự án này không tập trung vào agent, mà tập trung vào “nguyên liệu đầu vào” cho AI.

Điều này tạo ra một giả thuyết đầu tư khá rõ :
Nếu AI tiếp tục phát triển → nhu cầu data tăng → các nền tảng cung cấp data có thể hưởng lợi.
Tuy nhiên, rủi ro cũng rất rõ ràng. Toàn bộ mô hình này phụ thuộc vào adoption thực tế. Nếu không có đủ người dùng đóng góp data, hoặc không có đủ bên mua sử dụng data, thì hệ sinh thái sẽ không thể tự vận hành.
Vì vậy, khi theo dõi OpenLedger, tôi không quá quan tâm đến giá trong ngắn hạn. Thay vào đó, tôi sẽ theo dõi :
Số lượng node tham gia mạng lưới
Khối lượng dữ liệu được xử lý
Các đối tác AI thực sự sử dụng hệ thống
Đây là dạng dự án mà giá trị không đến từ “câu chuyện”, mà đến từ việc họ có thể xây dựng được một nền kinh tế dữ liệu thực sự hay không.
Bạn có thấy vậy không ?
