
Vor ein paar Jahren, als die Leute über Infrastruktur sprachen, meinten sie normalerweise Straßen, Häfen, vielleicht Cloud-Server, wenn das Gespräch technisch genug war. Infrastruktur war die langweilige Schicht. Notwendig, teuer, unsichtbar, wenn sie richtig funktioniert.
KI hat diese Sprache ein wenig verändert. Plötzlich wurde Infrastruktur spannend. GPUs wurden zum Schlagzeilenmaterial. Rechencluster wurden zu Markt-Narrativen. Jeder begann zu reden, als ob die eigentliche Knappheit in der KI einfach Pferdestärke war.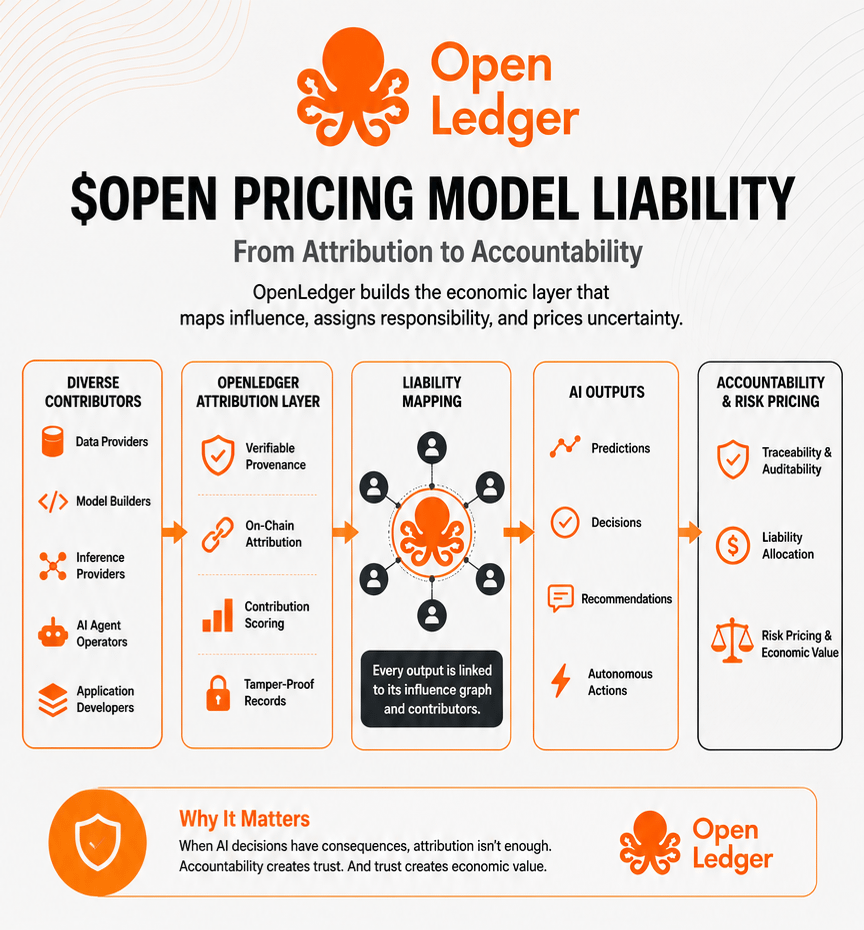
Das habe ich eine Zeit lang auch geglaubt.
Dann bemerkte ich immer wieder etwas Unangenehmes. Je mehr KI-Systeme kommerziell nutzbar wurden, desto weniger schien die Intelligenz selbst das eigentliche Problem zu sein.
Ein Modell, das ein Gedicht schlecht wiedergibt, ist eine Sache. Ein Modell, das eine Kreditentscheidung beeinflusst, einen Compliance-Verstoß aufdeckt, einem Agenten bei Kapitaltransfers hilft, Identitäten überprüft oder juristische Entwürfe erstellt … das ist eine ganz andere Kategorie. Dann fragt niemand mehr ernsthaft, wie schnell die Token verarbeitet wurden. Die Frage ist viel heikler.
Wer trägt die Verantwortung, falls etwas schiefgeht?
Diese Frage scheint in vielen Diskussionen über Krypto-KI seltsamerweise zu fehlen.
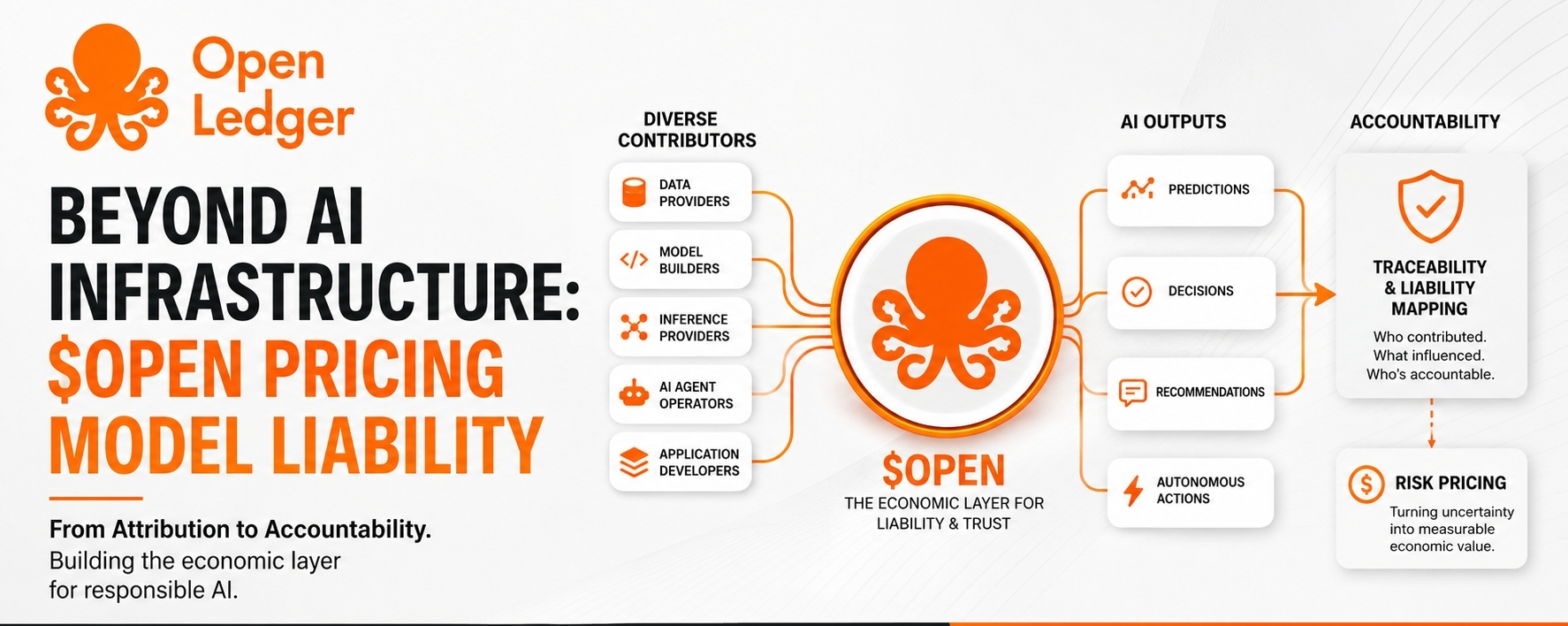
OpenLedger wird als KI-Infrastruktur beschrieben, und diese Beschreibung ist technisch korrekt, aber ich denke, sie verdeckt den interessanteren Aspekt. Der Markt behandelt die Zuordnung von Beiträgen weiterhin wie ein Belohnungssystem. Irgendetwas mit fairer Bezahlung der Mitwirkenden. Eine schöne Geschichte. Leicht zu vermarkten.
Doch in Systemen, die tatsächlich von Bedeutung sind, ähnelt die Zuordnung immer weniger einem Belohnungsmechanismus und immer mehr einer Haftungskarte.
Diese Unterscheidung verändert alles.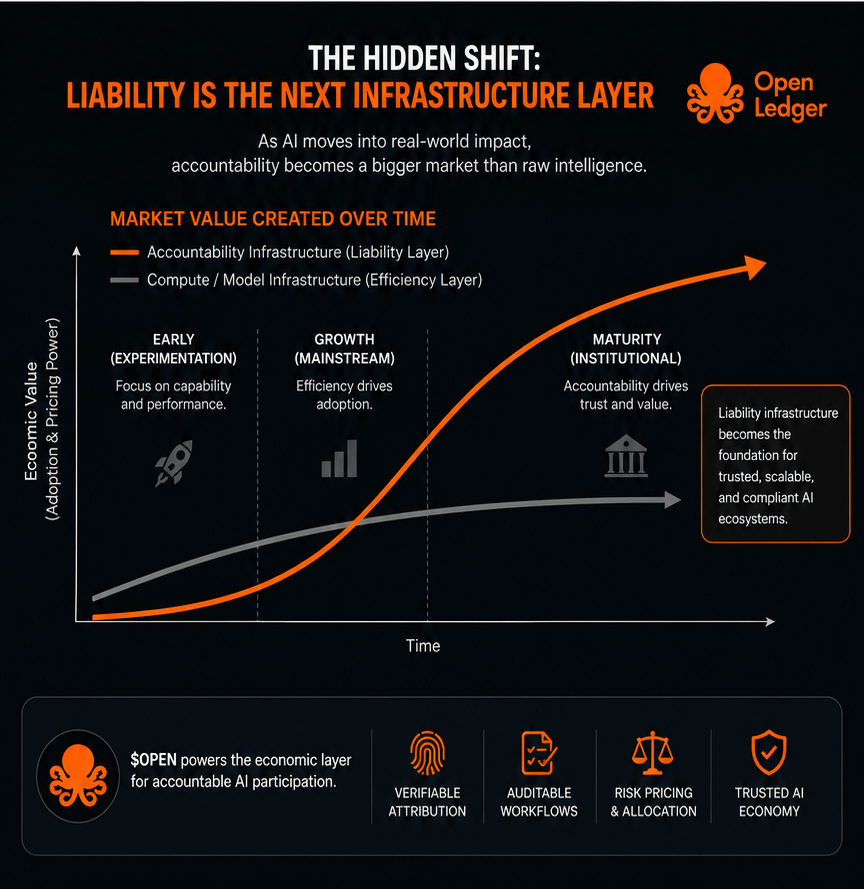
Ich erinnere mich an den anfänglichen Hype um autonome Agenten und dachte damals, die Leute würden ihrer Zeit weit voraus sein. Nicht etwa, weil die Technologie unrealistisch wäre, sondern weil das Koordinationsrisiko ignoriert wurde. Man sprach davon, dass Agenten Zahlungen tätigen, Dienstleistungen aushandeln, Rechenleistung erwerben und Arbeitsabläufe verwalten. Gut und schön. Aber wenn ein Agent mit fehlerhaften Trainingsdaten, manipulierten Datensätzen oder fragwürdiger Quelllogik arbeitet, wer trägt dann die Verantwortung?
Diese Antwort wird schnell unklar.
Traditionelle Software war auf seltsame Weise einfacher. Ein Unternehmen lieferte Code aus. Wenn etwas gravierend schiefging, war die Verantwortlichkeit klar ersichtlich. Unübersichtlich, ja, aber sichtbar.
KI-Systeme wirken fragmentierter.
Eine Partei liefert Daten. Eine andere optimiert das Modell. Eine weitere führt Inferenzprozesse durch. Eine weitere entwickelt Orchestrierungsschichten. Möglicherweise fügen Abrufsysteme mittendrin externen Kontext hinzu. Möglicherweise ändert die Agentenlogik das Entscheidungsverhalten erneut. Bis ein Ergebnis den Nutzer erreicht, scheint die Verantwortung auf ein halbes Dutzend Akteure verteilt zu sein.
Und sobald die Verantwortlichkeiten unklar werden, lässt sich das Risiko nur schwer einschätzen.
Die Märkte hassen das.
Institutionen hassen es noch mehr.
Privatkunden können ein gewisses Maß an Geheimnis tolerieren, wenn das Produkt etwas Magisches an sich hat. Unternehmen verhalten sich nicht so. Banken schon gar nicht. Und regulierte Branchen ganz bestimmt nicht.
Niemand in Compliance-Meetings sagt: „Das Modell wirkte vertrauenswürdig.“
Was sie fordern, ist noch unschöner. Prüfprotokolle. Quellcode-Herkunft. Eskalationswege. Dokumentation. Nachvollziehbarkeit von Entscheidungen, selbst wenn diese Nachvollziehbarkeit nur ein unvollkommenes Schauspiel ist.
Genau hier wird OpenLedger für mich interessanter als es die übliche KI-Token-Darstellung vermuten lässt.
Wenn OpenLedger tatsächlich eine Infrastruktur rund um verifizierbare Zuordnung aufbaut, dann ist die relevantere Frage vielleicht nicht, ob es zur Skalierung von KI beiträgt.
Vielleicht hilft es dabei, KI steuerbarer zu machen.
Das klingt weniger spannend, ich weiß.
Regierbarkeit lässt sich nicht so einfach simulieren wie Narrative.
Doch langweilige Infrastruktur hat tendenziell eine längere Bedeutung.
Betrachten wir die Finanzmärkte. Zuerst war Geschwindigkeit entscheidend. Dann Nachvollziehbarkeit. Dann Compliance-Architektur. Schließlich wurden die unsichtbaren Kontrollebenen genauso wertvoll wie die aufsehenerregenden Ausführungsebenen.
KI folgt vermutlich einem ähnlichen Prinzip.
Nicht ganz. Technologie wiederholt sich nie sauber. Aber Reime vielleicht.
Es gibt aber auch eine praktische Realität, die oft unterschätzt wird: Institutionen sind nicht allergisch gegen Innovationen. Sie sind allergisch gegen Unsicherheit, die sie nicht in die Praxis umsetzen können.
Das ist etwas anderes.
Einem Beschaffungsteam, das die Integration von KI erwägt, ist die Erstellung von Storytelling-Dokumentationen im Kryptobereich nicht wirklich wichtig. Vielmehr geht es darum, ob jemand erklären kann, wie Entscheidungen zustande kamen, wenn die Rechtsabteilung später Fragen dazu stellt.
Und die Rechtsabteilung stellt immer später Fragen.
Nehmen wir ein einfaches Beispiel. Stellen Sie sich einen KI-Workflow zur Unterstützung der Risikobewertung im Versicherungswesen vor. Keine vollständige Automatisierung, sondern lediglich Entscheidungshilfe.
Das Modell liefert verzerrte Ergebnisse, da ein Teil der zugrundeliegenden Datenpipeline fehlerhaft oder manipuliert war. Ein Kunde beanstandet das Ergebnis. Aufsichtsbehörden schalten sich ein. Interne Governance-Teams beginnen, Abhängigkeiten aufzudecken.
Und nun?
Wenn niemand die Beitragswege sinnvoll abbilden kann, wird Governance zum Ratespiel. Ratespiele in regulierten Umgebungen sind teuer.
An diesem Punkt hört die Zuschreibungstheorie auf, philosophisch zu sein.
Es wird betriebsbereit.
Deshalb denke ich, dass der Ausdruck „Haftung für Preismodelle“ nicht so dramatisch ist, wie er klingt.
Nicht unbedingt eine Haftung im rechtlichen Sinne. Zumindest noch nicht.
Wirtschaftliche Haftung an erster Stelle.
Kontrahentenvertrauen. Risikoabschläge. Integrationsbereitschaft. Vertrauensprämien.
Diese Dinge werden lange vor der Schaffung formaler Rahmenbedingungen durch die Gerichte bewertet.
Wenn zwei KI-Ökosysteme ähnliche funktionale Ergebnisse liefern, eines davon aber eine stärkere Nachvollziehbarkeit der Entstehung dieser Ergebnisse bietet, können Institutionen rationalerweise dieses Umfeld bevorzugen, selbst wenn die Leistung etwas schlechter ist.
Das passiert in anderen Branchen ständig.
Vertrauenswürdige Lieferketten sind unsicheren überlegen.
Prüfbare Finanzinfrastruktur ist intransparenten Alternativen überlegen.
Langweilige Vertrauenssysteme sichern sich still und leise Budgets.
Dennoch gibt es Gründe, skeptisch zu bleiben.
Die Zuordnung von Informationen in KI-Systemen ist schwierig. Sehr schwierig.
Man spricht beiläufig über die Nachverfolgung von Vorbildern, als ob Vorbilder akribisch sortierte Zutatenlisten führen würden. Das tun sie nicht.
Trainingseffekte sind diffus. Die Signalüberlagerung ist unübersichtlich. Die Gewichtung von Beiträgen kann bei fehlerhafter Implementierung zu einer reinen Wahrscheinlichkeitsrechnung werden.
Das ist wichtig, denn vorgetäuschte Verantwortlichkeit kann schlimmer sein als offensichtliche Intransparenz.
Dann kommen noch die üblichen Komplikationen durch Kryptowährungen hinzu.
Sobald wirtschaftliche Anreize mit der Zuordnung verknüpft sind, tritt Optimierungsverhalten auf.
Spam-Datensätze. Gefälschte Beitragsansprüche. Sybil-Reputationsspiele. Künstliches Vertrauenswachstum.
Wer sich auch nur zehn Minuten lang mit Anreizsystemen im Kryptobereich beschäftigt hat, versteht das instinktiv.
Das System muss feindlichem Verhalten standhalten, nicht kooperativen Demos.
Und da ist noch eine andere Frage, zu der ich immer wieder zurückkehre.
Wollen Unternehmen tatsächlich eine dezentrale Verantwortlichkeit?
Das klingt konzeptionell elegant.
In der Praxis bevorzugen manche Institutionen zentralisierte Anbieter gerade deshalb, weil die Verantwortlichkeit dort einfacher erscheint. Ein Anbieter. Ein Vertrag. Ein Eskalationsweg.
Schlecht konzipierte, verteilte Verantwortung kann zu bürokratischem Chaos führen.
Die Herausforderung für OpenLedger geht also über die technische Implementierung hinaus.
Es muss dafür sorgen, dass sich die verteilte Zuordnung operativ nützlich anfühlt, nicht nur theoretisch clever.
Das ist ein komplexeres Produktproblem, als viele Token-Märkte annehmen.
Dennoch werde ich das Gefühl nicht los, dass die Diskussionen über die KI-Infrastruktur seltsamerweise in Phase eins feststecken.
Alle reden immer noch davon, wie man Intelligenz schneller aufbauen kann.
Vielleicht liegt der nächste Engpass nicht im Bereich der Intelligenz.
Vielleicht geht es um Konsequenzmanagement.
Denn Intelligenz ohne nachvollziehbare Herkunft funktioniert bestens zur Unterhaltung.
Weniger, wenn es ums Geld geht.
Weitaus weniger gilt dies für regulierte Systeme.
Und wenn diese Verschiebung Realität wird, dann konkurriert $OPEN möglicherweise nicht mehr in der Kategorie, in der die meisten Menschen es vermuten.
Nicht berechnen.
Kein Modellzugriff.
Etwas Ruhigeres.
Der Markt für die Reduzierung von Unsicherheiten bei Maschinenentscheidungen.
Das ist eine weniger glamouröse These.
Genau deshalb könnte es von Bedeutung sein.