

„Das echte Problem in der AI-Branche ist nicht, dass die Modelle nicht stark genug sind, sondern wer ausgebeutet wird“
Qingfeng BNB:
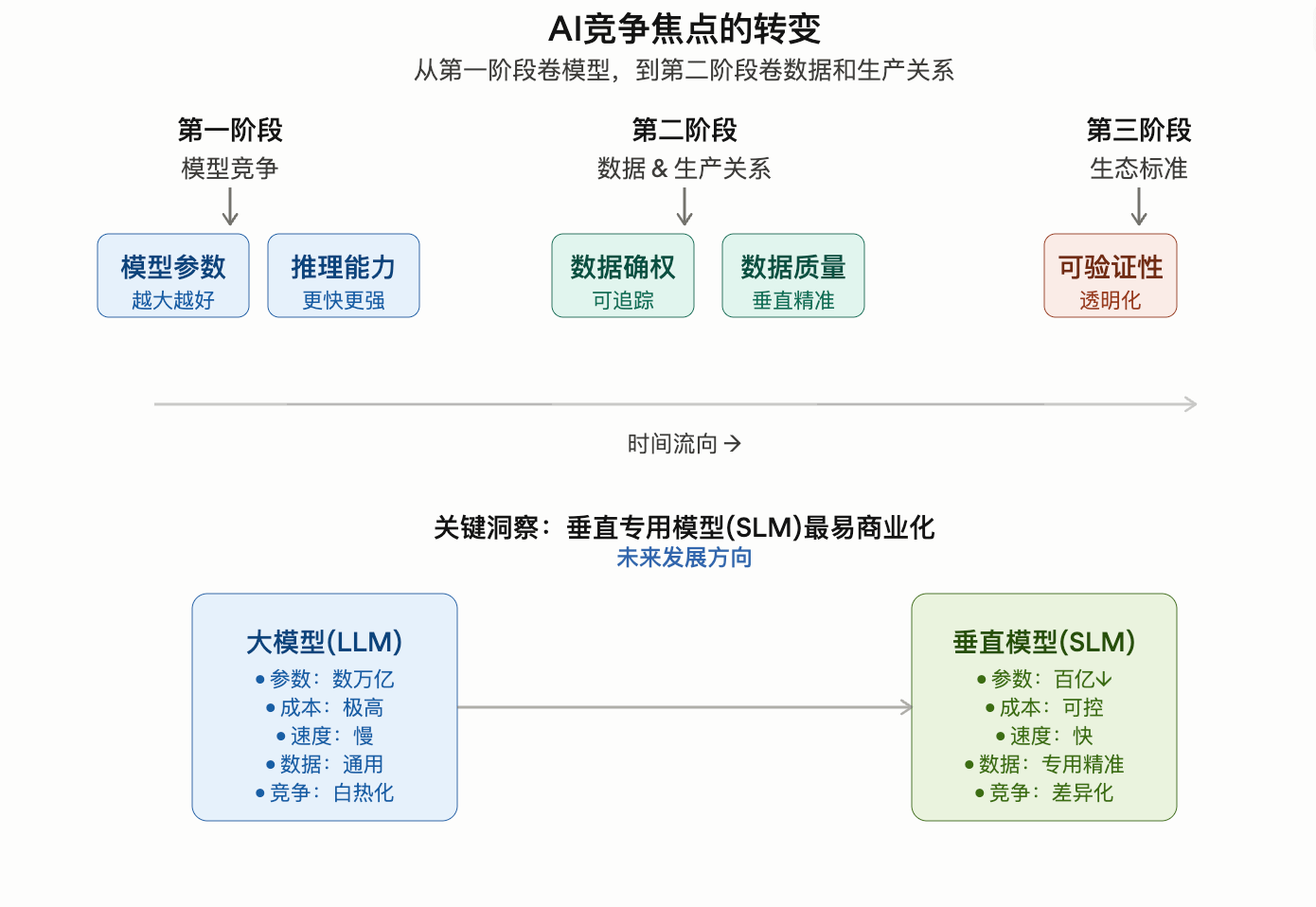
In den letzten Monaten hat die gesamte AI-Branche offensichtlich die zweite Phase erreicht.
In der ersten Phase haben alle gekämpft um:
Modellparameter
Inferenzfähigkeit
Programmierungsfähigkeit
Agenteneffizienz
Doch jetzt beginnen immer mehr Leute zu erkennen:
Das echte Problem in der AI-Branche könnte überhaupt nicht im Modell liegen.
Und bei:
Daten.
Besonders nach dem anhaltenden Durchbruch von Claude, Codex und Agent-Frameworks, beginnt der Markt ein immer schärfer werdendes Problem zu zeigen:
Diese Modelle, wer hat sie eigentlich gefüttert?
Mit dieser Frage habe ich neulich lange mit einem anonymen, erfahrenen Produktdesigner von OpenLedger gesprochen.
Ursprünglich dachte ich, dass OpenLedger nur ein weiterer ist:
„KI + Blockchain“
Projekte.
Aber je mehr wir redeten, desto mehr stellte sich heraus, dass sie tatsächlich eines der grundlegendsten und sensibelsten Probleme der gesamten KI-Branche lösen wollten:
Die Wertzuweisung in der KI-Welt.
„Die gesamte KI-Branche basiert derzeit auf einem sehr unfairen System.“
Zu Beginn des Interviews warf mein Gesprächspartner gleich einen sehr scharfen Satz in den Raum:
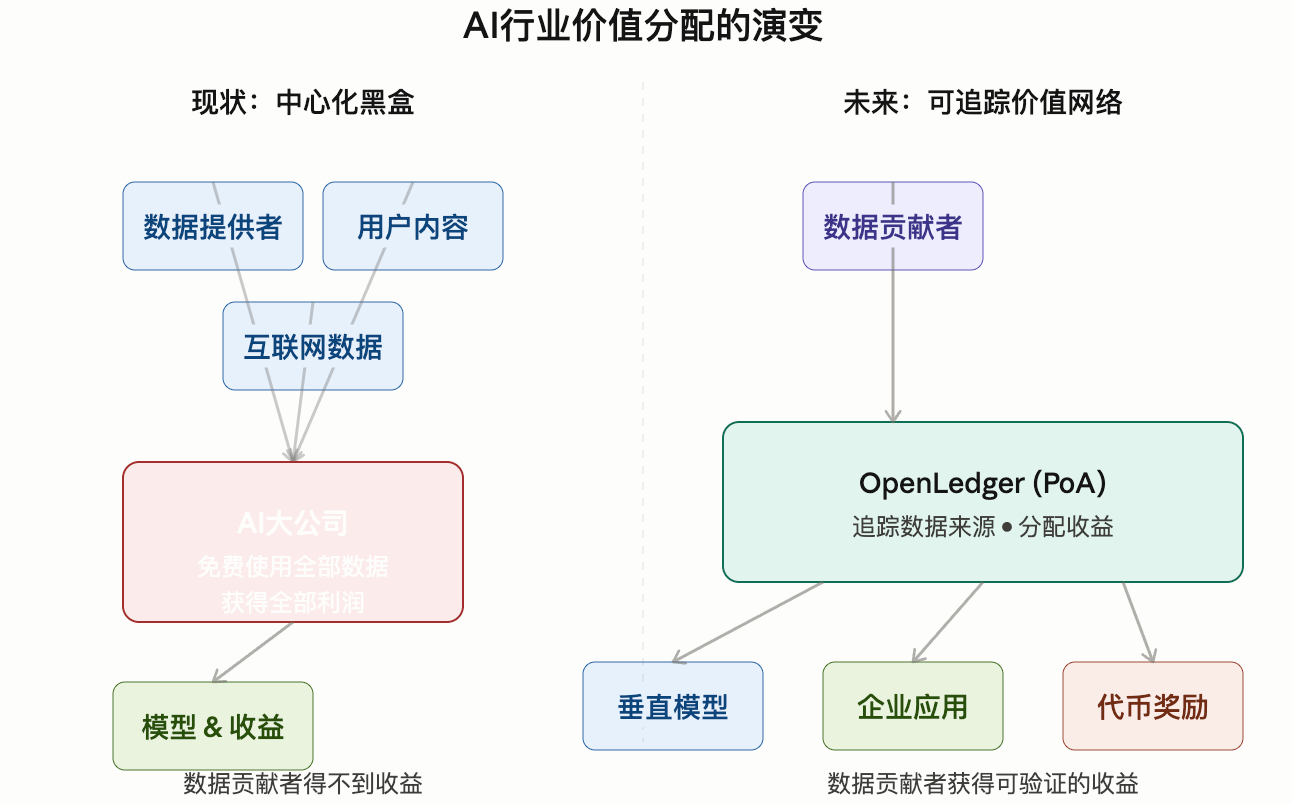
„Derzeit nutzen die meisten KI-Modelle im Grunde die ‚öffentlichen Datenressourcen‘ des Internets.“
Er sagte, dass viele KI-Unternehmen derzeit eine Sache stillschweigend annehmen:
Internetdaten können unbegrenzt kostenlos genutzt werden.
Inklusive:
Benutzerthemen
Bild
Video
Kommentar
Code
Browsing-Verhalten
Soziale Inhalte
Diese Dinge werden täglich von KI-Modellen kontinuierlich verschlungen.
Aber das Problem ist:
Die tatsächlichen Datenanbieter haben jedoch kaum Gewinne.
„KI-Unternehmen werden immer profitabler, aber die Personen, die Daten bereitstellen, sehen immer mehr wie kostenlose Arbeiter aus.“
Als er das sagte, war ich tatsächlich ziemlich schockiert.
Denn die meisten Menschen, die über KI diskutieren, konzentrieren sich nur auf:
Wie stark ist das Modell?
Wird KI die Menschheit ersetzen?
Wird der Agent explodieren?
Aber nur wenige Menschen diskutieren:
Wert des Datenhintergrunds der KI, wem gehört er eigentlich.
Und das ist genau der Kernfokus von OpenLedger.
Der Wettbewerb in der KI hat sich von einem Modellkrieg zu einem Datenkrieg entwickelt. Der Grund, warum vertikale spezialisierte Modelle (SLM) leichter zu kommerzialisieren sind als große Modelle (LLM) - sie benötigen hochwertige, nachverfolgbare Daten, und das ist genau das, was OpenLedger lösen möchte.
Warum betont OpenLedger immer wieder „Payable AI“?
Viele Menschen, die OpenLedger zum ersten Mal sehen, empfinden diesen Begriff als etwas abstrakt:
Payable AI.
Aber während des Interviews gab mir mein Gesprächspartner eine sehr einfache Erklärung:
„Früher hat KI nur Daten konsumiert, aber in Zukunft sollte KI für Daten bezahlen.“
Das ist eigentlich die gesamte Kernlogik von OpenLedger. (openledger.xyz)
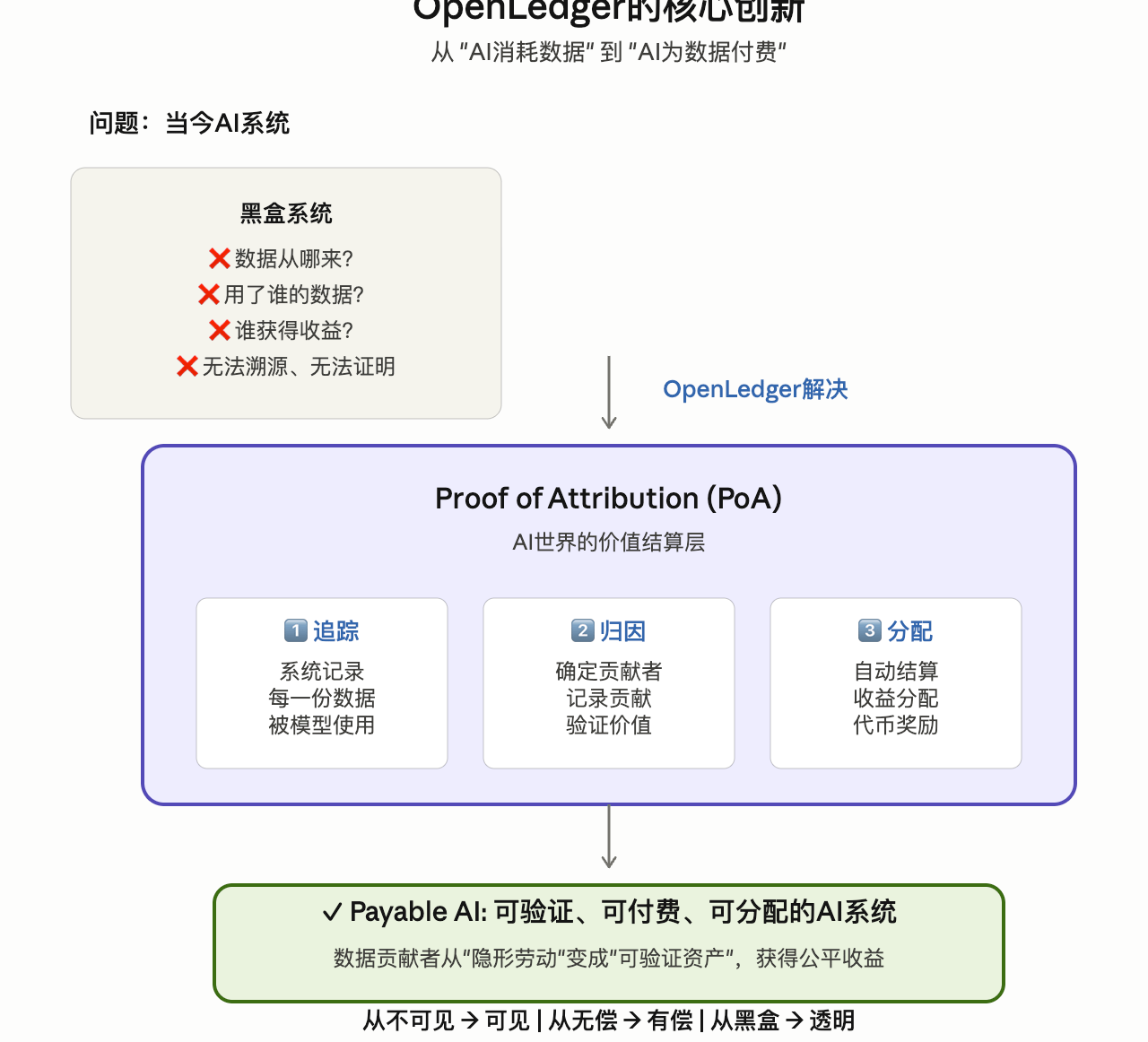
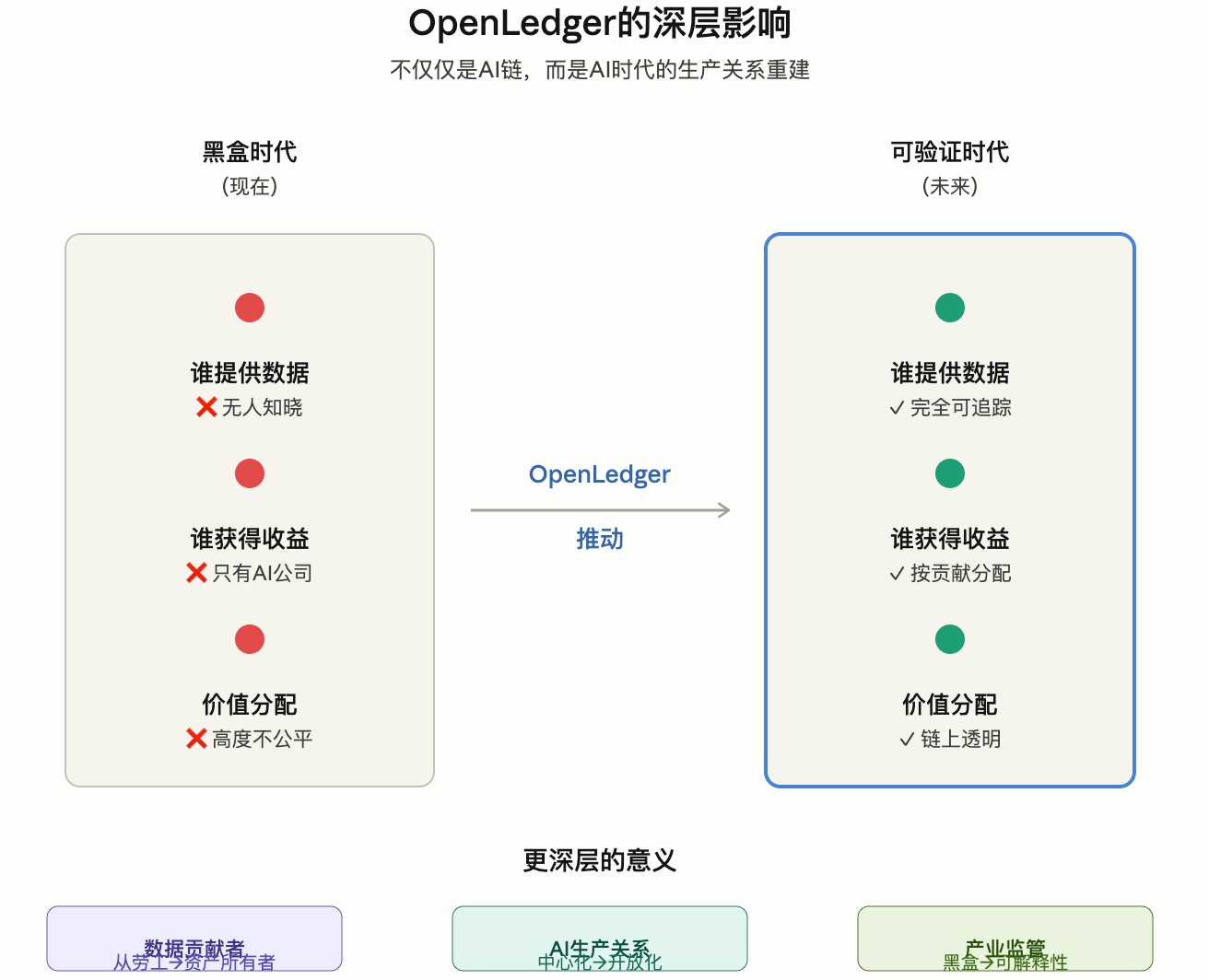
Derzeit sind die meisten KI-Systeme im Grunde genommen wie eine Blackbox.
Du weißt nicht:
Woher kommen die Daten?
Welche Daten hat das Modell konkret verwendet?
Wer hat den Wert beigetragen?
Wo fließt der Gewinn letztendlich hin?
Was OpenLedger tut, ist den gesamten KI-Trainingsprozess:
Zum ersten Mal die „Zuschreibungsfähigkeit“ erhalten.
Intern nennen sie diesen Mechanismus:
Proof of Attribution (PoA).
Einfach gesagt:
Wenn KI deine Daten verwendet, kann das System nachverfolgen. (openledgerfoundation.com)
Dann: automatisch Beiträge aufzeichnen, automatisch Gewinne verteilen.
„Das ist keine einfache Plattform zum Hochladen von Daten.“
Er sagte.
„Was wir wirklich wollen, ist die Wertabrechnungsebene in der KI-Welt.“
„Der größte Krieg in der Zukunft der KI könnte nicht der Krieg der Modelle sein“
Während des Interviews hatte ich einen Punkt, der mir besonders im Gedächtnis geblieben ist.
Er sagte:
„Viele Menschen denken, dass der Wettbewerb in der Zukunft zwischen großen Modellen stattfindet, aber wir glauben, dass der Wettbewerb um Datenrechte wichtiger ist.“
Er sagte, dass es ein Missverständnis auf dem Markt gibt:
Alle sind verrückt danach, LLMs zu nutzen.
Aber das, was tatsächlich am einfachsten zu kommerzialisieren ist, könnte tatsächlich sein:
SLM.
Das bedeutet:
Vertikale spezialisierte Modelle.
Zum Beispiel:
Medizinische KI
Rechts-KI
Finanz-KI
Spiel-KI
Unternehmens-KI
Diese Modelle benötigen möglicherweise nicht Billionen von Parametern.
Aber sie brauchen:
Hochwertige, vertrauenswürdige und nachverfolgbare Daten.
Und das ist genau das, was der aktuelle KI-Sektor am meisten vermisst.
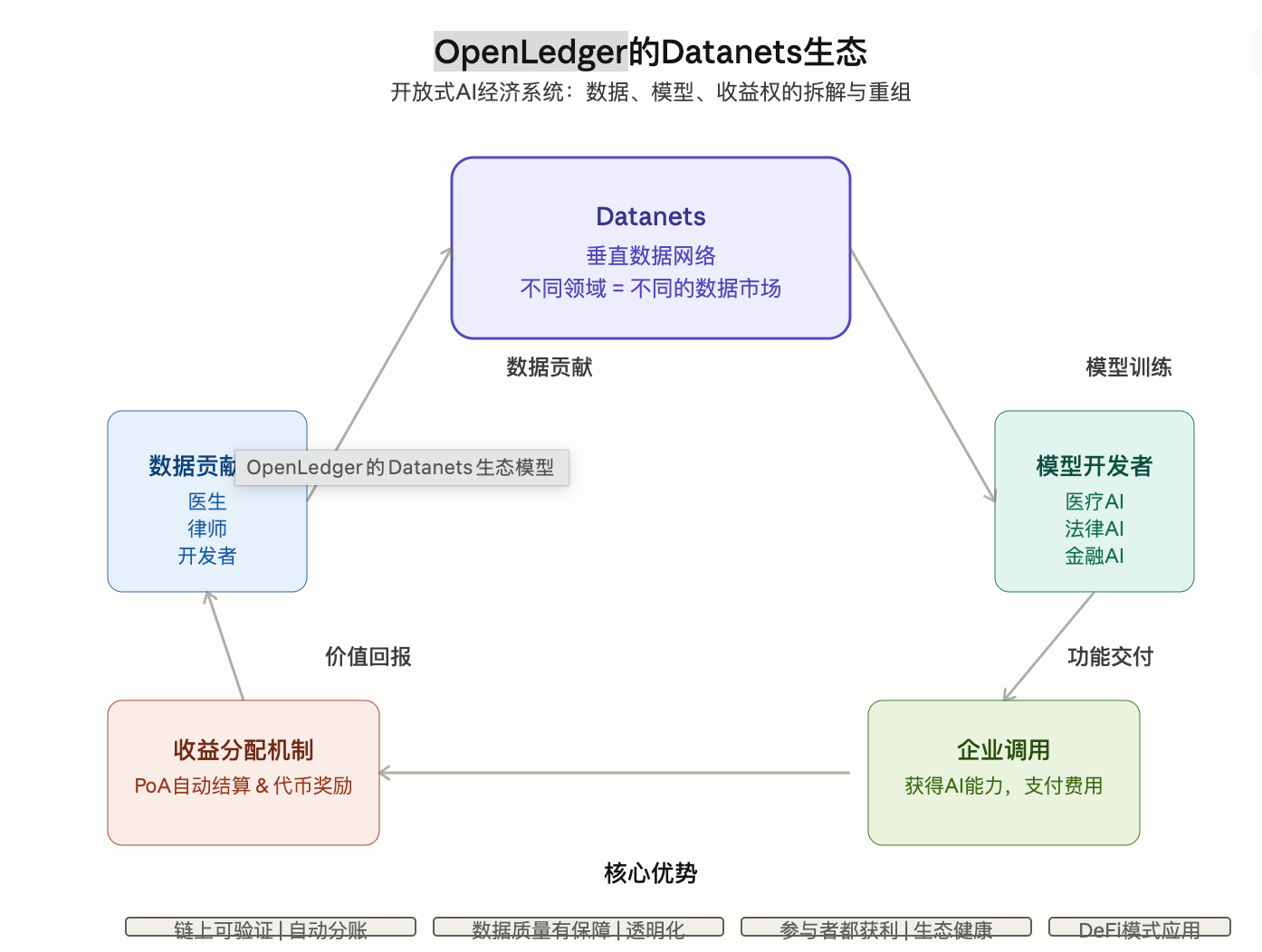
Die von OpenLedger vorgeschlagenen Datanets sind im Grunde genommen:
Vertikale Datennetzwerke. (CoinMarketCap)
Daten aus verschiedenen Bereichen bilden unterschiedliche Datenmärkte.
Modellentwickler kommen hierher, um Modelle zu trainieren.
Unternehmen nutzen KI-Fähigkeiten.
Datenbeitragszahler erhalten Gewinne.
Der gesamte Prozess ist auf der Chain verifizierbar.
„Frühere Datenbeiträge waren eine Form von unsichtbarer Arbeit.“
Er sagte.
„Und zukünftige Datenbeiträge sollten zu einem Vermögenswert werden.“
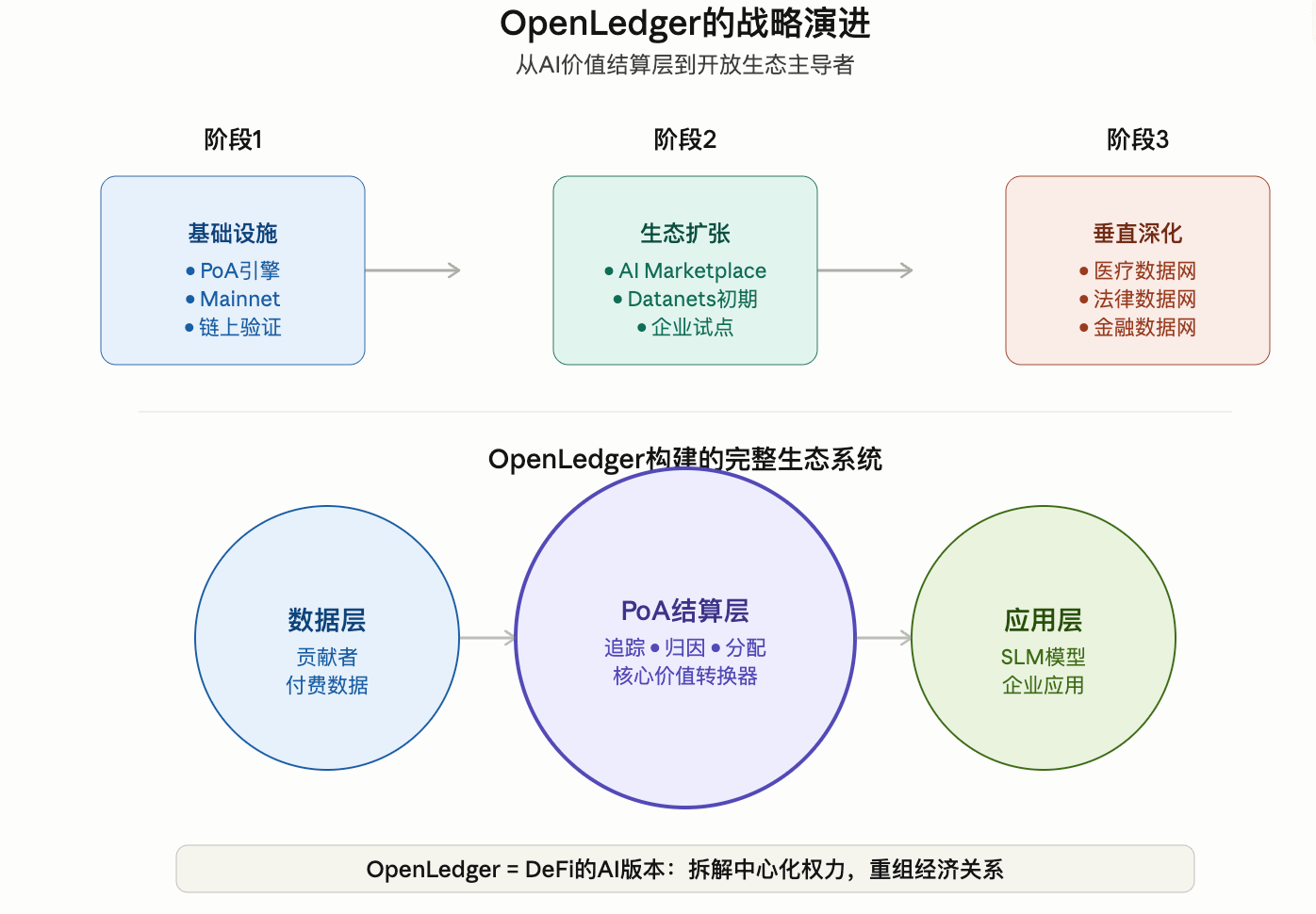
Warum hat OpenLedger kürzlich begonnen, den AI Marketplace zu beschleunigen?
Die letzten Aktionen von OpenLedger waren tatsächlich sehr intensiv.
Inklusive:
Mainnet-Vorstoß
Attribution Engine-Upgrade
AI Marketplace-Planung
Datanets-Expansion
Pilotprojekte für Unternehmens-KI
LayerZero-Cross-Chain-Integration (CoinMarketCap)
Insbesondere der AI Marketplace ist tatsächlich der entscheidende Teil ihrer gesamten Geschäftslogik.
Denn das Problem der KI-Branche in der Vergangenheit war:
Daten, Modelle, Gewinne,
Alles liegt in den Händen zentralisierter Plattformen.
Was OpenLedger anstrebt, ist:
Um:
Daten
Modelle
Agent
Gewinnrecht
Alles aufschlüsseln.
Neu kombiniert zu:
Offenes KI-Wirtschaftssystem.
Das ist tatsächlich sehr ähnlich zu dem, was DeFi für die traditionelle Finanzwelt getan hat.
Es ist nur so:
Das, was hier umstrukturiert wird, wird zur KI-Industrie.
„Was OpenLedger wirklich will, ist eigentlich keine KI-Chain“
Am Ende des Interviews stellte ich meinem Gesprächspartner eine Frage:
„Was denkst du, ist das größte Missverständnis, das die Außenwelt jetzt über OpenLedger hat?“
Er schwieg ein paar Sekunden, dann sagte er:
„Viele Menschen denken, wir arbeiten an einer KI-Chain, aber tatsächlich schaffen wir die Produktionsverhältnisse der KI-Ära.“
Um ehrlich zu sein, habe ich lange über diesen Satz nachgedacht.
Denn die meisten KI-Projekte befinden sich immer noch in der Phase:
Agent
Meme
Shell-Anwendungen
Traffic-Narrative
Aber OpenLedger hat bereits begonnen, darüber zu diskutieren:
In der KI-Welt:
Datenrechte
Wertzuweisung
Gewinnverteilung
Erklärbarkeit
Wirtschaftsstruktur
Diese Dinge sind tatsächlich die wirklich langfristigen Probleme.
Insbesondere seit die globale KI-Regulierung strenger geworden ist, beginnen immer mehr Unternehmen, sich darauf zu konzentrieren:
Sind die Datenquellen der KI legal? Ist der Trainingsprozess transparent? Sind die Modellergebnisse nachverfolgbar? (The Block)
Und OpenLedger setzt genau darauf.
In Zukunft wird KI sicherlich aus der „Blackbox-Ära“ in die „verifizierbare Ära“ eintreten.
Natürlich ist dieser Weg nicht einfach.
Denn es stellt tatsächlich die derzeit im KI-Sektor akzeptierte Interessenstruktur in Frage.
Aber zumindest hat es mir zum ersten Mal ernsthaft bewusst gemacht:
In der zukünftigen KI-Welt könnte das, was wirklich wertvoll ist, möglicherweise nicht nur das Modell selbst sein.
Sondern:
Wer hat das Recht und die Fähigkeit zur Verteilung des Datenwerts?
Und OpenLedger versucht, einer der ersten Regelmacher in diesem System zu werden.
@OpenLedger #OpenLedger $OPEN $BTC

