
Ich glaube, die meisten Leute verstehen nicht, was die Cloud-Konfiguration tatsächlich in KI-Systemen verändert.
Ich habe eine Weile darüber nachgedacht, was Octoclaw Cloud Config in Systemen wie OpenLedger und ähnlichen dezentralen KI-Stacks bewirken soll. Auf den ersten Blick klingt es fast langweilig. Nur Infrastruktur einrichten, Bereitstellungskonfiguration, Skalierungsregeln, vielleicht etwas Automatisierung über Cloud-Ressourcen. Aber je mehr ich sehe, wie sich diese Systeme entwickeln, desto weniger langweilig fühlt es sich an.
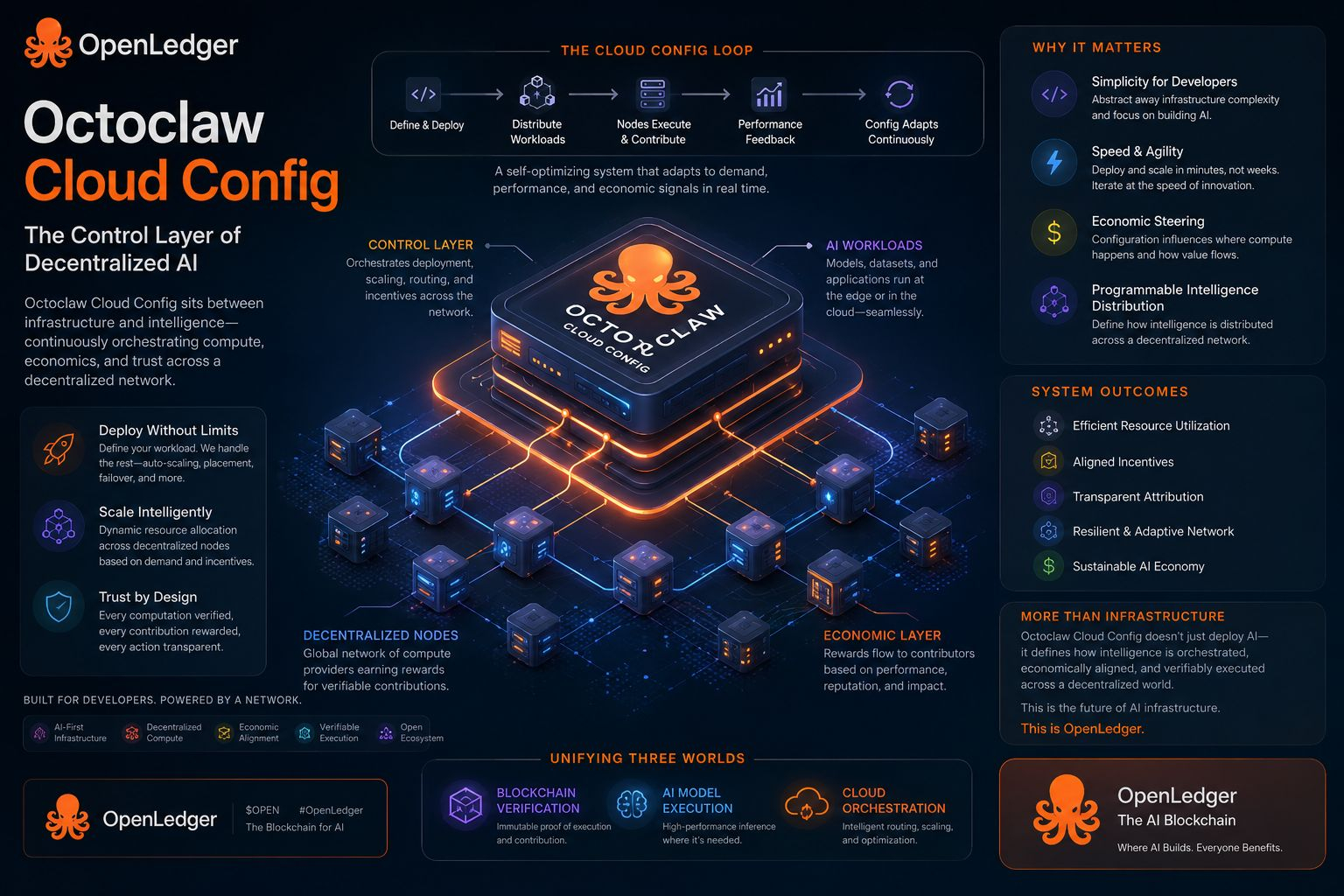
Es fühlt sich fast so an, als würde die Cloud-Konfiguration leise die echte Kontrollschicht der KI werden. Nicht die Modelle. Nicht einmal die Blockchain-Schicht... Die Art und Weise, wie alles zur Laufzeit zusammengefügt wird.
In Ökosystemen wie OpenLedger scheint Octoclaw Cloud Config in diesem mittleren Raum zu sitzen. Zwischen roher Recheninfrastruktur und den tatsächlichen KI-Arbeitslasten, die Entwickler interessieren. Auf dem Papier ist es einfach: definiere, wie KI-Knoten skalieren, wie Arbeitslasten bereitgestellt werden, wie Ressourcen über dezentrale Knoten verteilt werden. In der Praxis scheint es, als ob unter der Oberfläche etwas Fließenderes passiert.
Denn sobald du anfängst, verteilte KI-Systeme zu skalieren, bemerkst du, dass sich das System nicht wie eine statische Cloud-Umgebung verhält. Es verhält sich mehr wie ein lebendes Netzwerk mit sich ändernden Prioritäten. Cloud-Konfiguration wird weniger über das Setup und mehr über kontinuierliche Verhandlungen zwischen Nachfrage, Verfügbarkeit von Rechenleistung und wirtschaftlichen Anreizen.
Hier wird es interessant. Das Versprechen ist einfach. Entwickler können schneller skalieren, weil sie die Infrastruktur nicht mehr manuell verwalten. Das Bereitstellen von Servern, das Konfigurieren von Clustern, das Handhaben von Failover-Logik oder das Umgang mit Bereitstellungsfragmentierung über dezentrale Knoten – Octoclaw Cloud Config soll all das abstrahieren. Theoretisch reduziert es die Komplexität der Bereitstellung auf das, was Entwickler wollen.
Du beschreibst, was du willst. Das System findet heraus, wo und wie es läuft. Theorie und Realität stimmen hier nicht immer sauber überein. Denn in KI-Systemen ist es nicht nur eine technische Entscheidung, wo es läuft. Es ist eine wirtschaftliche und vertrauensbasierte. Knoten sind keine passive Infrastruktur. Sie sind Teilnehmer. Sie haben Anreize. Sie reagieren auf Arbeitslastmuster. Manchmal verhalten sie sich auf eine Weise, die mehr die Belohnungsstrukturen als die Ingenieurlogik widerspiegelt.
Während die Cloud-Konfiguration die Bereitstellung vereinfacht, führt sie auch eine versteckte Verhaltensschicht ein, die Entwickler nicht immer antizipieren. Das hatte ich anfangs nicht erwartet. Ein Vorteil, der oft hervorgehoben wird, ist die Geschwindigkeit. Entwickler können schneller skalieren, schneller iterieren und Modelle bereitstellen, ohne auf traditionelle DevOps-Zyklen warten zu müssen. Das stimmt. Es gibt jedoch einen anderen Blickwinkel, der weniger diskutiert wird: Konsistenz wird schwieriger zu garantieren, wenn das System selbst dezentralisiert ist.
Doch paradoxerweise ist dies auch der Punkt, an dem die Stärke von Systemen wie Octoclaw Cloud Config zum Vorschein kommt. Aufgrund der zwingenden starren Infrastruktur passt es sich an. Zumindest versucht es das. Was ich interessant finde, ist die Feedback-Schleife, die sich zu bilden beginnt. Entwickler stellen Modelle bereit, die Cloud-Konfiguration verteilt Arbeitslasten, Knoten reagieren basierend auf Anreizen, die Leistung verschiebt sich dynamisch und die Konfiguration passt sich erneut an.
Es ist keine einmalige Bereitstellung mehr. Es wird zu einem Anpassungsloop. Als ob die Infrastruktur lernt, wie sie sich unter Druck verhalten soll. Hier schleicht sich auch der Zweifel ein. Denn jedes System, das auf Feedback-Schleifen zwischen Teilnehmern beruht, erbt eine Art Unberechenbarkeit. Du kannst die Regeln entwerfen. Du kannst das emergente Verhalten nicht vollständig kontrollieren. In KI-Arbeitslasten, wo Latenz, Datenkonsistenz und Reproduzierbarkeit wichtig sind, wird diese Unberechenbarkeit zu einem echten Problem.
Deshalb frage ich mich immer wieder: Reduziert Octoclaw Cloud Config tatsächlich die Komplexität oder verteilt sie die Komplexität in eine Schicht, die wir noch nicht vollständig verstehen? Vielleicht beides. Dennoch gibt es etwas Mächtiges an der Richtung, in die dies geht. Wenn ich sehe, wie OpenLedger diese Ideen integriert, habe ich das Gefühl, dass sie versuchen, drei Dinge zu vereinen, die traditionell nicht gut zusammenpassen: Blockchain-Verifizierung, KI-Modellausführung und Cloud-Orchestrierung. Die meisten Systeme behandeln dies als Schichten. Hier scheinen sie mehr verwoben zu sein.
Vielleicht ist dieses Zusammenspiel der Punkt. Denn sobald die Cloud-Konfiguration auf einem Niveau programmierbar wird, bei dem du nicht mehr nur KI bereitstellst, definierst du, wie Intelligenz über ein Netzwerk verteilt wird. Das klingt abstrakt. In der Praxis bedeutet das, dass Entwickler eine Art Kontrolle gewinnen, die dem Besitz von Infrastruktur ähnelt, ohne tatsächlich Infrastruktur zu besitzen. Allein dieser Wandel könnte erklären, warum einige Leute den Verlauf mit etwas wie AWS für KI vergleichen, obwohl ich denke, dass dieser Vergleich etwas zu sauber ist.
AWS ist zentrale Klarheit. Das hier fühlt sich wie verteilte Verhandlung an. Es gibt auch einen Mechanismus, der nicht immer auf den ersten Blick offensichtlich ist: Attribution und Beitragsverfolgung. Wenn Arbeitslasten über Knoten verteilt sind und Belohnungen an den Beitrag gebunden sind, beginnt die Cloud-Konfiguration, nicht die Leistung, sondern den wirtschaftlichen Fluss zu beeinflussen. Wo die Berechnung stattfindet, beeinflusst, wer belohnt wird. Das wiederum beeinflusst, wo die Berechnung stattfinden möchte.
Diese Schleife ist leicht zu unterschätzen. Das bedeutet, dass die Cloud-Konfiguration keine technische Orchestrierung ist. Sie wird zu wirtschaftlicher Steuerung. Ich bin mir immer noch nicht ganz sicher, wie stabil dieses Modell langfristig ist. Es könnte einen hochgradig effizienten Markt für verteilte KI schaffen oder neue Formen von Ungleichgewicht einführen, bei denen bestimmte Knoten Arbeitslasten basierend auf subtilen Konfigurationsvorurteilen dominieren.
Beide Ergebnisse erscheinen plausibel. Eine Sache, die mir jedoch auffällt, ist, dass Entwickler dazu neigen, zu unterschätzen, wie schnell Abstraktionsebenen zu Kontrollebenen werden. Zuerst sieht Octoclaw Cloud Config wie ein Produktivitätstool aus. Später beginnt es, das Verhalten des Systems auf eine Weise zu gestalten, die schwerer nachzuvollziehen ist.
Dieser Wandel ist subtil. Vielleicht sogar unangenehm. Doch trotz all dieser Unsicherheiten kann ich den Reiz nicht ignorieren. Schnellere Bereitstellung, reduzierte Reibung, automatisches Skalieren über dezentrale Knoten. Das sind echte Verbesserungen. Selbst wenn das zugrunde liegende System komplexer im Verhalten wird, wird die Benutzererfahrung einfacher.
Dieser Kompromiss könnte das prägende Merkmal der dezentralen KI-Infrastruktur in der Zukunft sein. Daher komme ich immer wieder zu dieser Spannung: Einfachheit für den Entwickler, Komplexität im System. Ich denke nicht, dass dieser Widerspruch so schnell verschwinden wird.
Vielleicht geht es bei Octoclaw Cloud Config nicht wirklich darum, die Bereitstellung zu lösen. Vielleicht geht es darum, neu zu definieren, wo die Bereitstellung endet und das Systemverhalten beginnt. Es ist noch zu früh, um das zu sagen. Bisher interessant. Vielleicht liege ich falsch, wir werden sehen.