Ich war sehr neugierig, als ich bemerkte, dass das Dashboard von @OpenLedger eine ganz andere Geschichte erzählt als das System, das wirklich speichert. Das Dashboard spricht über Durchsatz, Volumen, Anzahl der Inference, Anzahl der online Nodes. Diese runden Zahlen sind leicht vergleichbar und einfach zu teilen. Das System im Hintergrund bewahrt jedoch still jeden Schritt, der zu diesen Inference führt, selbst die Schritte, die niemand zurückblicken möchte.
Zwei parallele Geschichten. Keine Oberflächlichen Widersprüche. Aber sie unterscheiden sich an dem wichtigsten Punkt. Die eine Seite erinnert sich nur an das Ergebnis. Die andere erlaubt nicht, den Weg zu vergessen.
Als ich dies erkannte, musste ich das gesamte Design des Traces von OpenLedger mit anderen Augen betrachten.
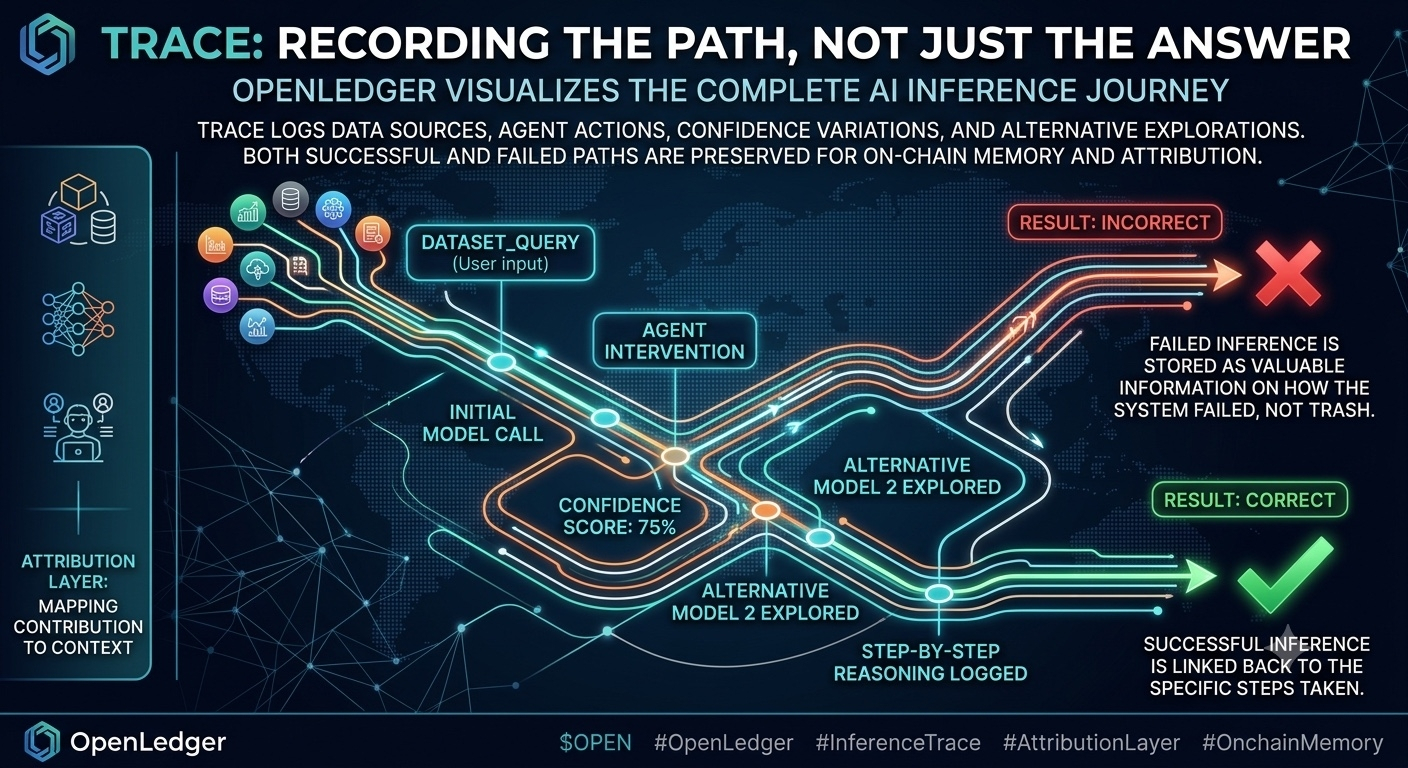
Trace hier ist nicht das Speichern von Antworten. Es sind nicht Input und Output, um Audits durchzuführen. Es ist die Kette von Schritten, die das System durchlaufen hat, um zu dieser Antwort zu gelangen. Welches Dataset wurde berührt. Welches Modell wurde aufgerufen. Welcher Agent hat interveniert. In welcher Reihenfolge. Wie sich das Vertrauen mit jedem Schritt verändert. Ein Weg, nicht ein Endpunkt.
Das klingt offensichtlich. Aber wenn der Trace nicht das Ziel aufzeichnet, sondern die Reise, wird die gesamte Wertermessung in diesem System umgekehrt.
Meine erste Reaktion war sehr instinktiv. Bei KI liegt der Wert im Output. Benutzer bezahlen nicht dafür, wie viele Richtungen das Modell ausprobiert hat. Sie bezahlen für die richtige Antwort. Investoren ebenso. Der Markt ebenso. Dashboards ebenso. Alles um sie herum belohnt das Ziel. Warum also ein System schaffen, das für die Reise bezahlt?
Diese Frage hat mich eine Weile beschäftigt, bis ich erkannte, dass OpenLedger kein Produkt für KI im gewohnten Sinne baut. Sie bauen ein Mechanismus, um zu erinnern, wie Wissen erzeugt wird. Und diese beiden Dinge sind nicht dasselbe.
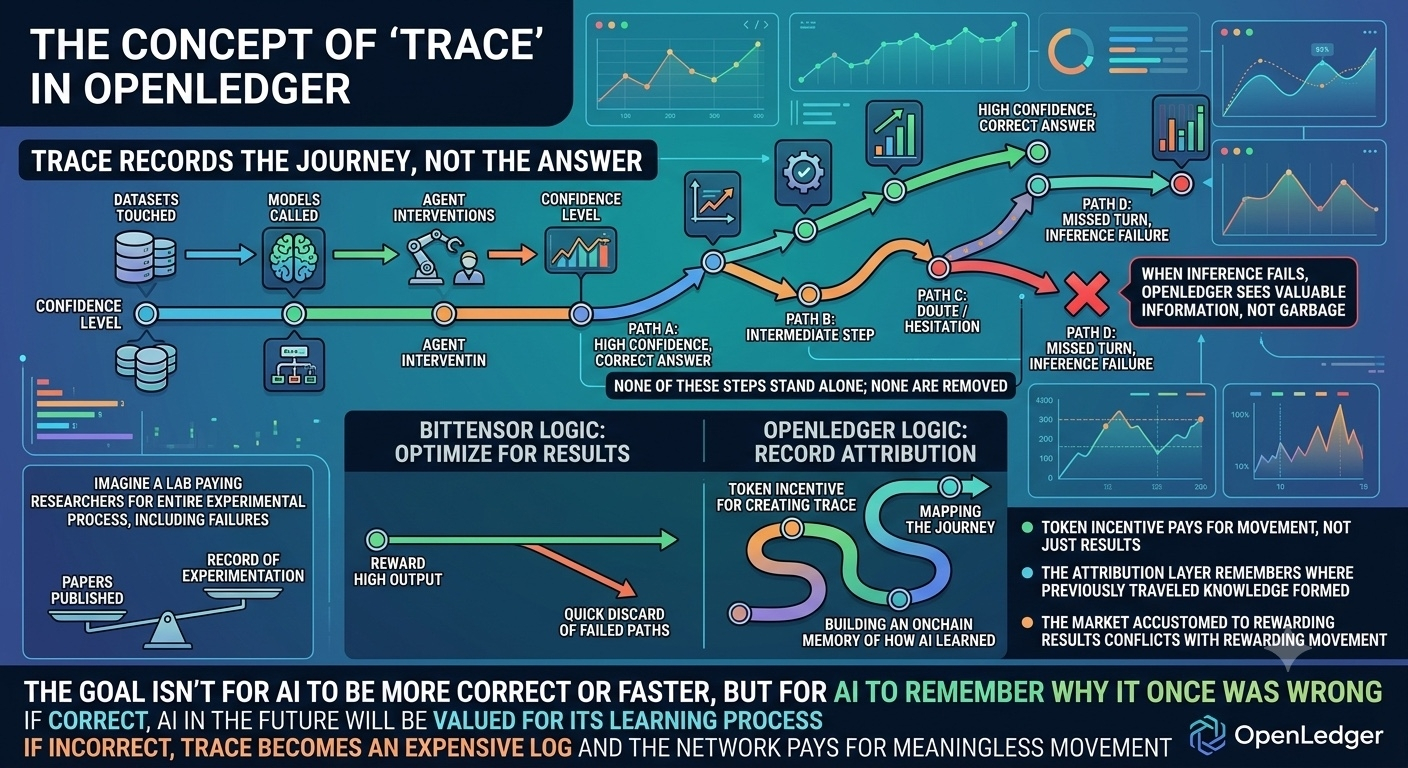
Im Design der Attribution Layer existiert Trace nicht zum Debuggen. Es existiert als wirtschaftliche Entität. Jeder Trace ist ein Weg durch das Graph, in dem kein Beitrag für sich allein steht. Eine Inferenz ist niemals das Ergebnis eines einzelnen Modells. Es ist eine Synthese aus Daten, Architektur, Parametern, Entscheidungen des Agents und auch stillschweigenden Annahmen. Wenn eine Inferenz fehlerhaft ist, betrachtet OpenLedger das nicht als Fehler, der eliminiert werden muss. Sie sehen es als Information darüber, wie das System falsch gedacht hat. Und diese Information wird unverändert gespeichert.
Das steht im völligen Widerspruch zur Intuition derjenigen, die an traditionellem ML gewöhnt sind. Dort wird ein Fehler abgewertet. Rauschen wird gefiltert. Die Geschichte wird auf einige Leistungskennzahlen komprimiert. Je schneller das System vergisst, desto "sauberer" wird es. OpenLedger wählt den entgegengesetzten Weg. Sie behalten die rohe Geschichte. Kein frühes Reinigen. Keine frühen Urteile.
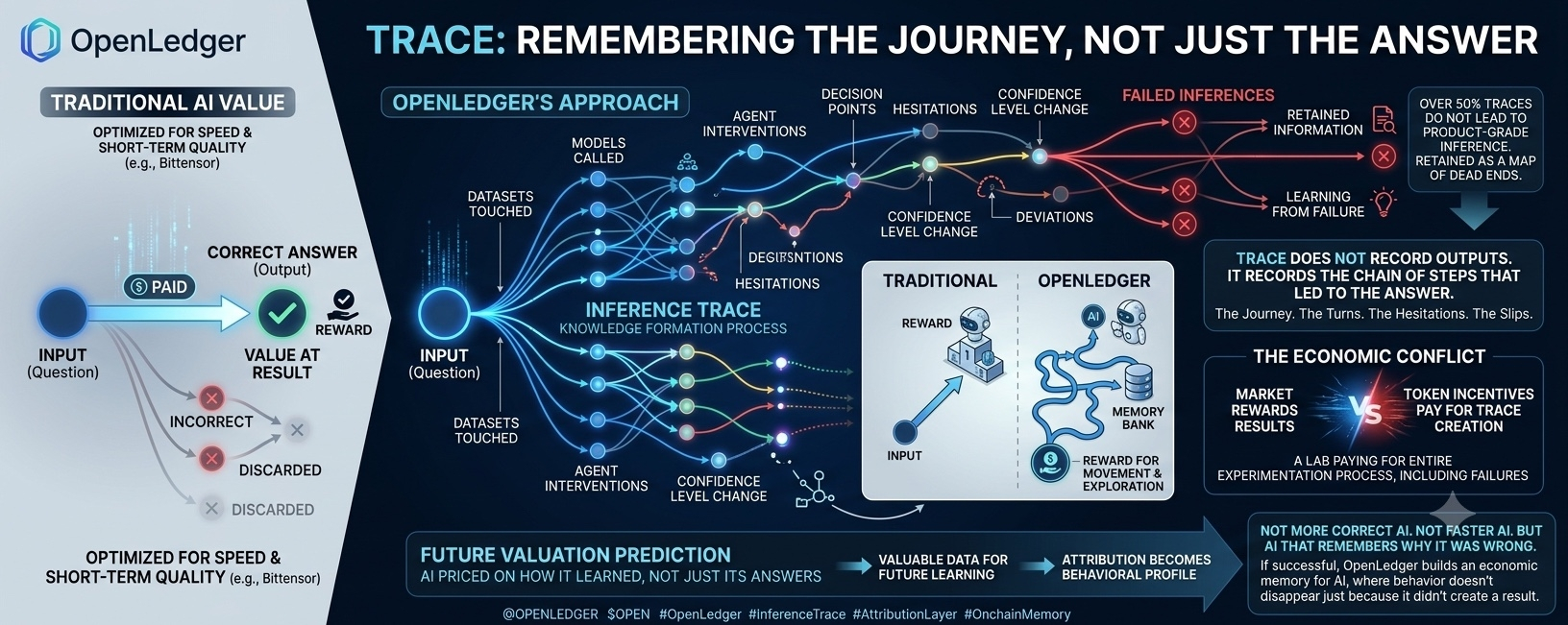
Im Vergleich zu Bittensor wird dieser Unterschied sehr deutlich. Bittensor optimiert stark für Ergebnisse. Miner werden belohnt, wenn ihre Outputs vom Netzwerk hoch eingestuft werden. Ein Fehler führt schnell zu Hunger. Qualität wird durch Eliminierung geschützt. Dieser Ansatz ist extrem effektiv, wenn das Ziel kurzfristige Performance ist. Aber der Preis dafür ist, dass die Reise zusammen mit den Fehlern verloren geht. Das System kann sich nicht daran erinnern, wie es jemals gescheitert ist.
OpenLedger wählt diesen Weg nicht. Sie behalten die Reise, auch wenn das Ziel keinen sofortigen Nutzen hat.
Ein Datenpunkt, der mich wirklich innehalten ließ, tauchte während eines AMA auf. Das Team bestätigte, dass der Großteil der aktuellen Traces nicht zu einer produktstandardisierten Inferenz führt. Mehr als die Hälfte. Keine schöne Zahl. Nicht etwas, das man prahlen würde. Wenn man durch die Linse des Outputs schaut, ist das Verschwendung. Token werden für Dinge verteilt, deren sofortiger Wert nicht nachgewiesen wurde.
Aber wenn man durch die Linse der Reise schaut, ist das eine Karte der Sackgassen, die das System durchlaufen hat. Und diese Karte wird nicht gelöscht.
Genau hier wird der innere Konflikt von OpenLedger sehr deutlich. Token-Anreize bezahlen für die Erstellung von Traces. Der Markt gewöhnt sich daran, Ergebnisse zu belohnen. OpenLedger belohnt jedoch Bewegungen. Diese beiden wirtschaftlichen Logiken harmonisieren nicht. Sie ziehen aneinander. Und das Projekt versucht nicht, diesen Konflikt zu entschärfen.
Stellen Sie sich ein wissenschaftliches Labor vor. Anstatt Gehälter nach der Anzahl veröffentlichter Arbeiten zu zahlen, zahlen sie Gehälter basierend auf dem gesamten Experimentierprozess. Jede falsche Hypothese wird dokumentiert. Niemand wird sofort bestraft, weil er falsch lag. Aber auch niemand wird vergessen. Zu einem bestimmten Zeitpunkt, wenn das Labor sein Fachgebiet besser versteht, wird diese Geschichte des Ausprobierens zu einem Vermögenswert. Sie zeigt, wer wirklich den Weg geebnet hat, und wer nur alte Wege wiederholt hat.
OpenLedger setzt darauf, dass KI in der Zukunft ähnlich bewertet wird. Nicht, weil sie die richtigen Antworten liefert, sondern weil sie zeigt, wie sie gelernt hat.
Wenn diese Annahme stimmt, sind die Konsequenzen tiefgreifend. Optimale Mitwirkende, die kurzfristigen Spam-Output erzeugen, hinterlassen wiederholbare, flache, explorationsarme Traces. Wenn das System reif genug ist, um die Reise zu rekapitulieren, werden diese Muster sehr deutlich. Keine Notwendigkeit für Blacklists. Kein Governance-Drama. Die Geschichte klassifiziert sich selbst. Im Gegensatz dazu können die "schlechten" Wege von heute wertvolle Daten werden, wenn das System lernt, sie neu zu interpretieren. Attribution wird dann nicht mehr zum Ranking. Es wird zum langfristigen Verhaltensprotokoll.
Aber wenn diese Annahme falsch ist, sind die Konsequenzen alles andere als vage. Trace wird zu einem teuren Log. Token werden für Bewegungen verteilt, die niemals neu bewertet werden. Ernsthafte Mitwirkende erkennen, dass ihre Reise sich nicht von der Müllreise unterscheidet und sich zurückziehen. Das Vertrauen in das Zahlungssystem wird von innen heraus untergraben. Die Narrative "Payable AI" bricht zusammen, ohne dass es eines Exploits, Dramas oder externer Schocks bedarf.
Was mich auffällt, ist, dass OpenLedger nicht verspricht, diesen Konflikt bald zu lösen. Kein Fahrplan sagt klar, wann alte Traces neu bewertet werden. Keine klare Governance darüber, wer die Geschichte neu lesen darf und wie. Der sensibelste Teil des Systems bleibt leer. Absichtlich.
Das macht viele Leute unzufrieden. Das Dashboard erzählt diese Geschichte nicht. Volumen, TPS, Anzahl der Inferenz reflektieren nicht den Wert eines Speichers. Aber vielleicht ist das genau das, worauf OpenLedger setzt. Sie akzeptieren, kurzfristig weniger attraktiv auszusehen, um etwas zu bauen, das langfristig schwer zu kopieren ist.
Wenn es erfolgreich ist, liegt der Vorteil von OpenLedger nicht im Modell, nicht im Agenten-Framework und nicht in der Tokenomics. Es liegt in der Verhaltensgeschichte, die kein Netzwerk nachbilden kann. Ein wirtschaftlicher Speicher für KI, in dem jeder Schritt eine Spur hinterlässt.
Wenn das nicht passiert, wird OpenLedger zu einem Netzwerk, das für bedeutungslose Bewegungen bezahlt. Wenn es passiert, wird sich viele Dashboards heute naiv anfühlen, wenn sie zurückblicken.
Und das ist der Grund, warum ich glaube, dass der wahre Wert von OpenLedger nicht dort liegt, wo jeder hinsieht. Er liegt in der Reise, die das System sich merken muss, auch wenn es sehr gerne vergessen würde.