Ich habe länger als erwartet bei der Meldung „OctoClaw ist Live“ innegehalten.
Es liegt nicht daran, dass das Wort „live“ so seltsam ist. In der Crypto-Welt gibt's jeden Tag etwas Live. Mainnet live. Bridge live. Agent live. App live. Alles ist so live, dass das Wort fast seine Bedeutung verliert.
Ich bleibe am Ende hängen: bauen, automatisieren und in Echtzeit mit KI-Agenten ausführen.
Auf den ersten Blick leicht verständlich: OctoClaw ist das neue Frontend von @OpenLedger . Ein Ort, an dem Nutzer auf das AI-Blockchain-Hintergrundsystem zugreifen können. Ein Platz zum Klicken. Ein Platz, um zu sehen, wie der Agent arbeitet.
Am Anfang dachte ich auch so.
Ein Projekt, das zu viel über Datanets, Proof of Attribution, ModelFactory, OpenLoRA spricht, braucht letztendlich etwas, das die Benutzer tatsächlich verwenden können. Ohne ein Frontend bleibt alles in den Docs.
Aber je mehr ich OctoClaw mit dem Rest von OpenLedger verbinde, desto mehr sehe ich, dass diese Sichtweise etwas verkehrt ist.
OctoClaw ist nicht nur erschienen, weil OpenLedger eine Schnittstelle braucht. Es ist erschienen, weil das Problem der Attribution des KI-Agenten begonnen hat, über das Backend hinauszuwachsen.
Wenn KI nur eine Frage beantwortet, ist Attribution bereits schwierig. Eine Antwort kann aus Trainingsdaten, Retrieval-Kontext, Prompt, Feinabstimmung, Modell, Tool und Gedächtnis stammen. Der Benutzer sieht nur einen kompakten Text. Aber hinter diesem Text liegt eine komprimierte Kette von Beiträgen.
Wenn KI zum Agenten wird, wird diese Kompression noch stärker.
Agenten reden nicht nur. Agenten handeln.
Es zieht Daten. Es ruft Tools auf. Es liest Dokumente. Es vergleicht Quellen. Es trifft Entscheidungen. In einigen Workflows kann es sogar On-Chain ausführen. Wenn das passiert, ist das, was auf dem Frontend erscheint, nicht mehr nur eine Antwort. Es ist eine Handlung.
Und Handlungen haben Konsequenzen.
Das ist der Punkt, der OctoClaw bemerkenswerter macht als eine normale KI-App. Eine normale KI-App versucht, das Backend in der Schnittstelle verschwinden zu lassen. Der Benutzer soll nur das Ergebnis sehen. Je weniger er von dem darunterliegenden Teil sieht, desto besser.
Aber bei KI-Agenten schafft diese Sauberkeit tatsächlich Probleme.
Wenn eine Handlung wertvoll ist, wer hat diesen Wert geschaffen?
Nehmen wir den Trading-Agenten als Beispiel. Der Benutzer sieht nur, wie der Agent ein Token analysiert und eine Einschätzung abgibt. Aber hinter dieser Einschätzung könnten Marktdaten, Sentiment, Whitepaper, Governance-Historie, On-Chain-Daten, Prompt-Regeln, Modellfeinabstimmung, RAG-Kontext und ein Datanet mit Strategien aus der Community stecken.
Wenn der Agent richtig ist, wird die Schnittstelle in Erinnerung bleiben.
Aber die Kette der Beiträge dahinter kann sehr leicht verschwinden.
Es geht nicht nur um Fairness. Fairness ist die einfachste Ebene zu diskutieren. Die tiefere Ebene ist die Machtstruktur.
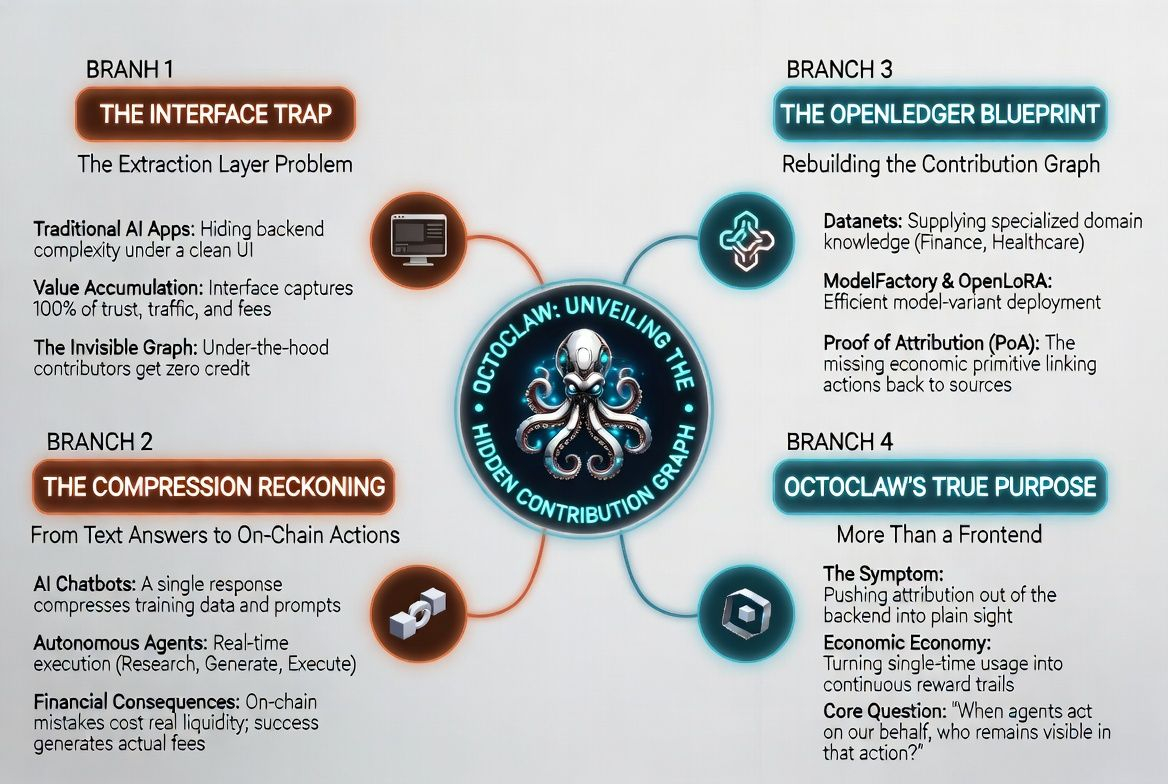
Wenn Attribution verschwindet, steht der Wert nicht still. Er fließt dorthin, wo er sichtbar bleibt. Und der sichtbarste Ort ist oft die Schnittstelle.
Benutzer wissen nicht, welche Daten dem Agenten helfen, besser zu werden. Sie wissen nicht, welcher Prompt die Entscheidung lenkt. Sie wissen nicht, welches Tool wichtige Signale liefert. Sie wissen nur, welche App ein Ergebnis zurückgibt. Im Laufe der Zeit wird die Schnittstelle zum Ort, der Vertrauen, Traffic, Gebühren und den Wert definiert.
So kann sich die Agentenschicht in eine Extraktionsschicht verwandeln.
Es braucht niemanden, der etwas zu schlecht macht. Es reicht, wenn der Beitragsgraph lange genug verborgen bleibt. Die Beitragenden unten schaffen weiterhin Wert. Die Benutzer oben sehen weiterhin die Oberfläche. Der Wert steigt. Der Kredit läuft nicht zurück.
Ich denke, das ist der Grund, warum OpenLedger den Proof of Attribution ins Zentrum gestellt hat. Wenn man nur eine allgemeine KI-Blockchain machen wollte, könnte das Projekt bei einem Datenmarktplatz oder einer Agentenplattform stoppen. Aber OpenLedger fragt tiefer: Welche Daten beeinflussen die Ausgabe, welches Modell verwendet es, wer trägt zum Lebenszyklus der KI bei, und wo sollten die Belohnungen hingehen?
Das macht OctoClaw zu einem anderen Spieler.
OctoClaw ist nicht der Anfang der Geschichte. Es ist ein Symptom eines Problems, das lange genug bestanden hat: Je mehr KI-Agenten handeln, desto weniger kann Attribution im Backend verborgen werden.
Ein Agent kann recherchieren. Aber welche Quellen werden für diese Forschung genutzt?
Ein Agent kann generieren. Aber auf welchem Modell und in welchem Kontext basiert diese Generierung?
Ein Agent kann ausführen. Aber woher kommt diese Ausführung – aus welcher Entscheidung, welchem Tool, welchem Signal, welchem Prompt?
Wenn diese Kette nicht zurückverfolgt werden kann, bleibt dem Benutzer nur ein sehr vages Vertrauen: Der Agent ist richtig, weil die App schlau aussieht.
In der Krypto ist solches Vertrauen gefährlich. Denn wenn KI mit der On-Chain-Ausführung verbunden wird, liegt der Fehler nicht mehr in einem Textabschnitt. Fehler können zu Transaktionen, Geldflüssen, Strategien, Erträgen, Positionen werden.
Und wenn der Agent richtig ist, ist der Wert auch kein Lob mehr. Er wird zu Gebühren, Volumen, Nutzung, Belohnung.
Deshalb ist die Frage "Wer bekommt die Attribution?" keine nebensächliche Frage. Es ist eine wirtschaftliche Frage.
OpenLedger versucht, den Beitragsgraphen hinter jeder Aktion der KI zu rekonstruieren. Datanets organisieren spezialisierte Daten. ModelFactory und OpenLoRA helfen dabei, diese Daten ins Modell zu bringen und effektiver bereitzustellen. Proof of Attribution versucht, die Ausgabe wieder mit den Beiträgen zu verbinden. OctoClaw ist der Ort, an dem Endbenutzer dieses gesamte System in Form eines funktionsfähigen Agenten treffen.
Wenn man so denkt, ist OctoClaw nicht nur ein Frontend.
Es ist der Ort, an dem der verborgene Beitragsgraph näher an die Oberfläche gezogen wird.
Das ist der Grund, warum ich OctoClaw interessant finde. Nicht, weil es ein neuer Agent ist. Sondern weil es mich zwingt, die schwierigere Frage zu betrachten: Wenn ein Agent handelt, als ob er eine einzelne Entität wäre, kann das System dann die Schichten sehen, die diese Handlung erzeugt haben?
Wenn die Antwort nein ist, wird die Schnittstelle zu viel gewinnen.
Wenn die Antwort ja ist, hat OpenLedger die Chance, Attribution von einem schönen Konzept im Whitepaper zu einem echten wirtschaftlichen Primitive zu machen.
Ich denke nicht, dass OpenLedger das gesamte Problem gelöst hat. Attribution in der KI ist extrem schwierig. Daten sind nicht linear additiv wie Tokens in einer Wallet. Ein Datenpunkt kann in diesem Kontext nutzlos, aber in einem anderen sehr wichtig sein. Ein Prompt kann für sich genommen keinen Wert schaffen, aber in Kombination mit RAG und Tool-Calls kann es das gesamte Verhalten des Agenten verändern.
Aber gerade weil es schwierig ist, ist es bemerkenswert.
Je automatisierter der KI-Agent ist, desto mehr benötigt der Markt eine Erklärungsschicht, nicht nur für die Ausgabe, sondern auch für die Herkunft der Handlung. Nicht um alles komplizierter zu machen, sondern um zu verhindern, dass der gesamte Wert in die letzte Schnittstelle gesogen wird.
Wenn OpenLedger es richtig macht, wird OctoClaw nicht nur der Ort sein, an dem Benutzer dem KI-Agenten begegnen.
Es wird der Ort sein, an dem Benutzer beginnen zu sehen, dass hinter jedem Agenten immer eine beitragende Wirtschaft steht.
Die Frage ist also nicht, ob OctoClaw einen intelligenten Agenten schafft.
Die richtige Frage ist: Wenn der Agent anfängt, anstelle von Menschen zu handeln, wer bleibt dann in dieser Handlung sichtbar?