There's a structural problem embedded in almost every token-incentivized data network that rarely gets examined directly: the people most motivated to contribute are often the least qualified to determine what's valuable.
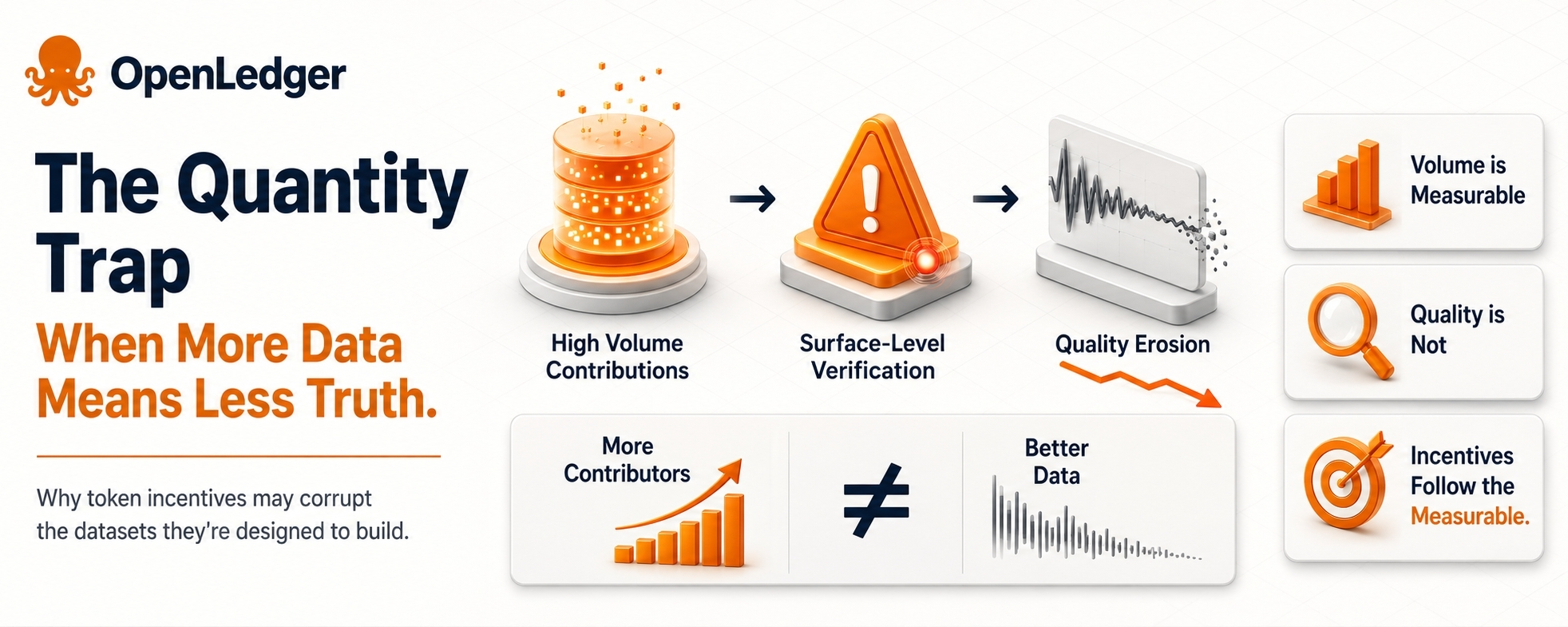
OpenLedger's model depends on contributors supplying data to a verified, attribution-tracked pipeline. The token reward is the mechanism that drives participation. But token rewards, by design, need to be legible — they have to attach to something measurable. And in data networks, measurability almost always defaults to quantity over quality, because quality is slow, expensive, and contested to verify.

This creates a distortion that operates quietly at the foundation of the system.
When contributors understand that rewards are tied to volume — or even to proxies for quality like format compliance, metadata completeness, or source diversity — behavior adapts to those signals rather than to actual usefulness. The dataset that gets built isn't necessarily the dataset that AI developers need. It's the dataset that the incentive structure was easiest to game at scale.
This isn't a criticism unique to OpenLedger. It's a known failure mode in crowdsourced data markets broadly. But it's especially consequential here because OpenLedger's value proposition rests on verified, trustworthy datasets — not just large ones. If the verification layer is robust enough to catch low-quality or manipulated contributions, that's a meaningful friction cost that will reduce contributor throughput. If it isn't robust enough, the data that accumulates may carry the appearance of verification without the substance.
The deeper dynamic worth watching is what happens to contributor behavior over time as the token price fluctuates. During high price periods, contribution volume likely surges — but so does the noise. Contributors who wouldn't normally participate flood in, bringing marginal data that passes surface-level checks. During low price periods, the careful, domain-specific contributors — the ones who were never purely economically motivated — may be the only ones left. Ironically, the network's data quality might be inversely correlated with its token price.
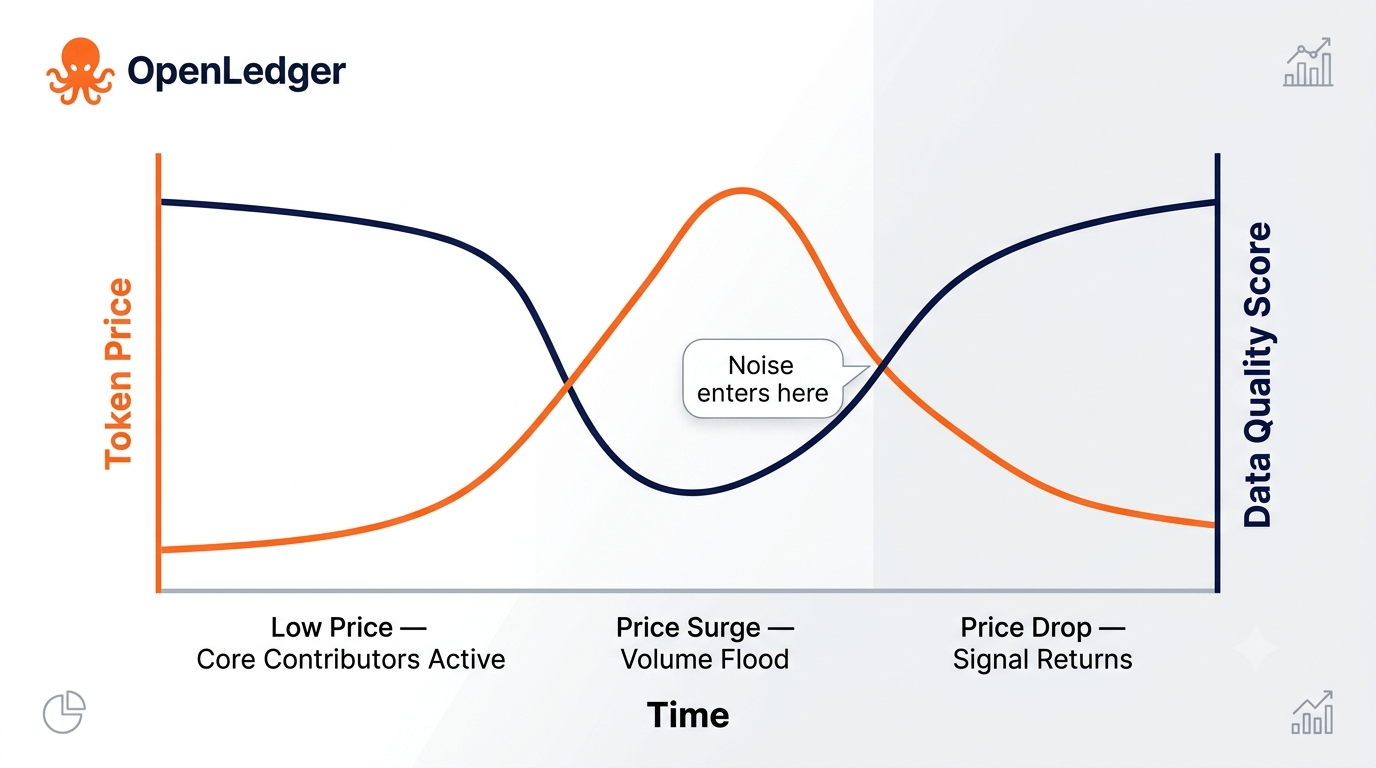
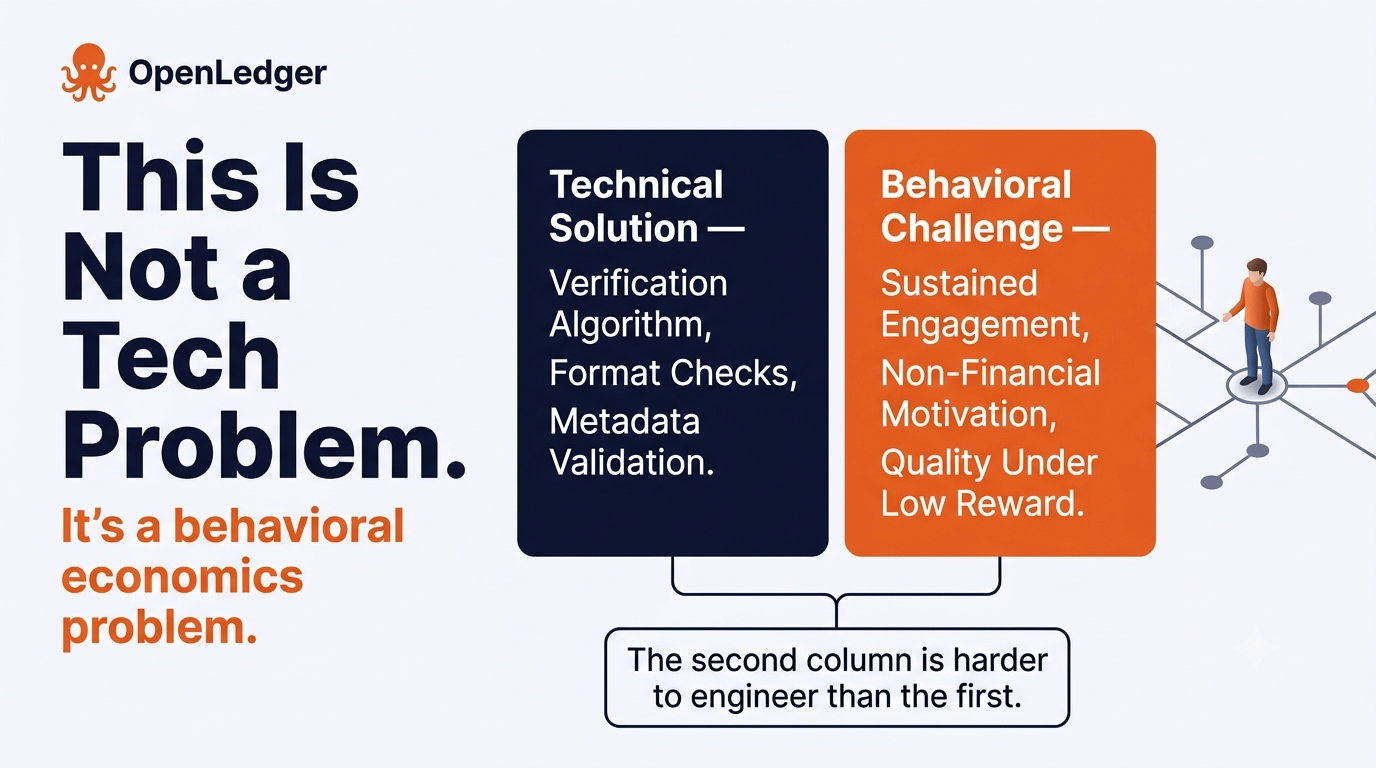
This suggests that OpenLedger's long-term data integrity isn't primarily a technical problem. It's a behavioral economics problem. The system needs contributors who stay engaged and supply useful data even when the financial incentive is weak. That's a much harder thing to design for than a verification algorithm.
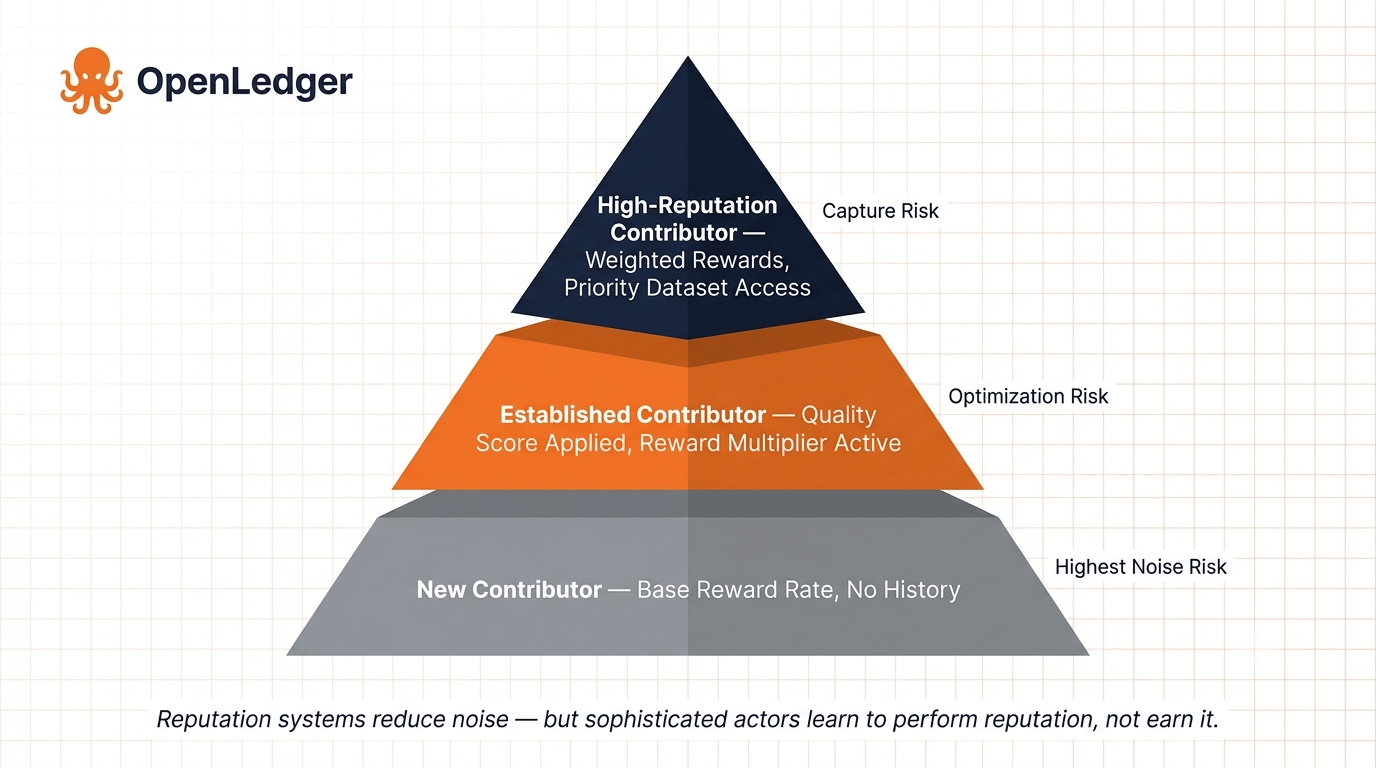
One possible partial solution is reputation weighting — where historical contributor quality scores influence future reward multipliers, creating a non-financial incentive to maintain standards over time. Whether OpenLedger has implemented something with real teeth here, or whether it's a softer layer that sophisticated contributors can eventually optimize around, is the question that separates a durable network from a well-architected one that degrades under load.
The honest conclusion isn't that OpenLedger can't solve this. It's that no data network operating with token incentives has fully solved it yet. The project is building in a space where the economic mechanism and the epistemic goal are in constant tension. Watching how that tension gets managed — not at launch, but eighteen months in — will say more about the system's value than any whitepaper.