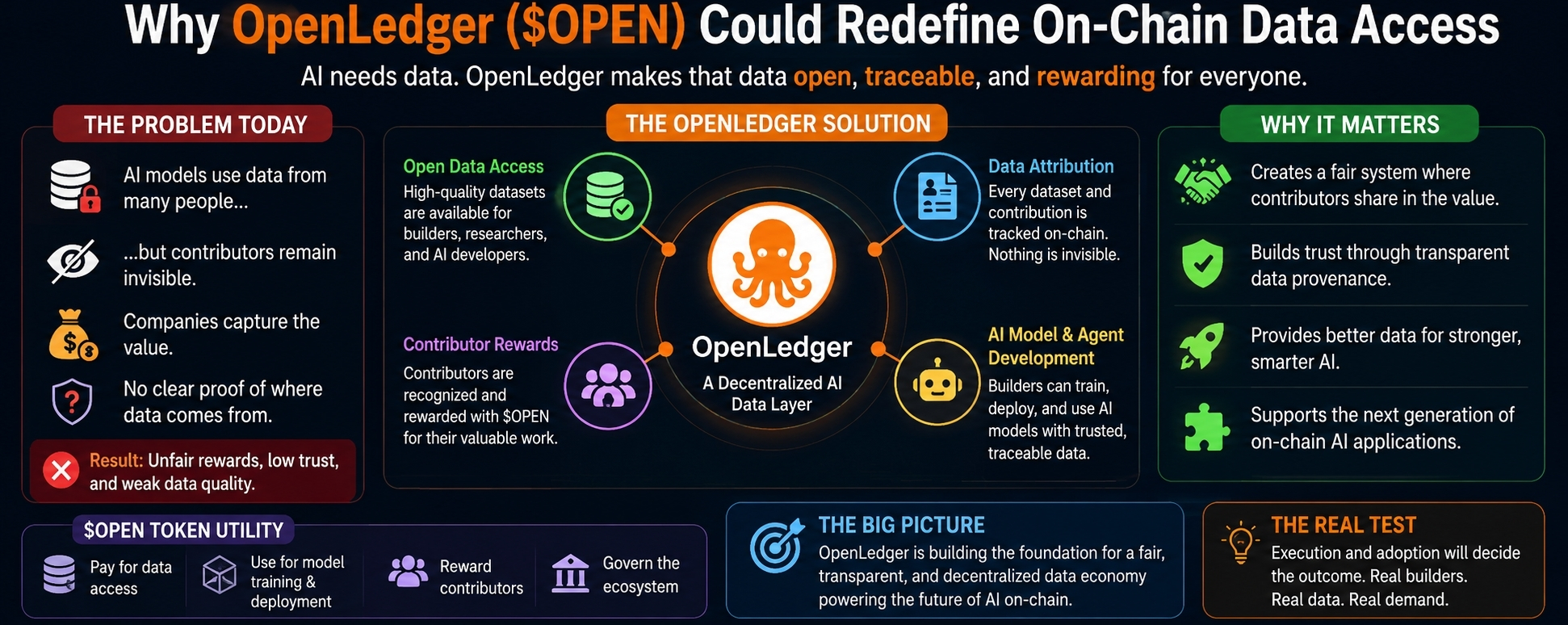
I keep coming back to OpenLedger because it feels like one of those projects I almost dismissed too quickly.
At first, it looked like another AI-and-crypto idea trying to ride the same wave everyone else is chasing. The space is full of projects talking about data, ownership, rewards, and decentralized AI. After seeing enough of those pitches, it becomes easy to tune them out.
But OpenLedger starts to look more interesting when you stop looking at the buzzwords and focus on the actual problem.
AI needs data.
That sounds obvious, but it is the part people skip over too often. Every AI model depends on information. Someone creates that information. Someone organizes it. Someone improves it. Someone makes it useful.
Most of the time, those people are never seen.
The AI tool gets praised.
The company behind it makes money.
The contributors who helped build the data layer are forgotten.
This is the gap OpenLedger is trying to fix.
OpenLedger is building around the idea that data should not just be used quietly in the background. It should be traceable. It should have ownership. It should be clear where it came from and who helped make it valuable.
That is why the project matters.
It is not just trying to put AI on-chain for the sake of sounding modern. OpenLedger is focused on the foundation behind AI: the data itself.
And honestly, that is where the bigger problem is.
AI is becoming more powerful, but trust is still weak. Users want better AI tools. Developers want cleaner datasets. Builders want reliable infrastructure. But if nobody knows where the data comes from, who owns it, or whether it is dependable, then the whole system becomes shaky.
OpenLedger’s approach is simple to understand.
Make data more open.
Make contributions easier to track.
Give builders access to useful datasets.
Create a system where contributors can be recognized and rewarded through the network.
That is a much more practical idea than just saying “decentralized AI” and leaving it there.
Of course, this does not mean OpenLedger has already solved everything.
This is still a hard problem.
Data quality is difficult. Incentives can be abused. People may try to submit low-quality work just to earn rewards. Builders will not care about the idea unless the system actually helps them save time, access better data, or build stronger AI products.
That is the real test for OpenLedger.
Can it attract real developers?
Can it create datasets that people actually want to use?
Can it make $OPEN useful inside the ecosystem instead of just another token people trade?
Can it prove that on-chain data access is not just a nice story, but a real advantage?
Those are the questions that matter.
Still, I understand the project better now than I did at first.
OpenLedger is not exciting because it says “AI.” Plenty of projects say that.
It is interesting because it focuses on something less flashy but more important: how AI gets its data, how that data is tracked, and how the people behind it can share in the value.
That feels more grounded.
And in a market full of loud promises, grounded ideas are worth noticing.
I am not saying OpenLedger will automatically redefine on-chain data access. That depends on execution, adoption, and whether builders truly need what it offers.
But I do think OpenLedger is pointing at a real problem.
If it can turn that problem into a working network with real usage, then $OPEN could become more than just another AI-crypto token.
It could become part of the infrastructure behind how data, AI, and ownership connect on-chain.
And that is why I keep watching it.