I keep coming back to one simple question when I look at OpenLedger. If an AI answer becomes useful because many people shaped the data behind it then who should be able to prove that influence and share in the value that follows? My view is that OpenLedger is not only trying to build another AI network. It is trying to make data influence visible enough to become part of the economic system around AI.
I used to think the main problem in AI data was access. A model needed more data and better data and cleaner data. That still matters but it does not explain the full problem anymore. Data often enters a training pipeline and then disappears into the model. The final output may carry traces of that work yet the original contributor usually has no practical way to show that their input mattered. OpenLedger focuses on that gap. It asks whether the path from data to model to answer can be recorded in a way that people can inspect and trust.
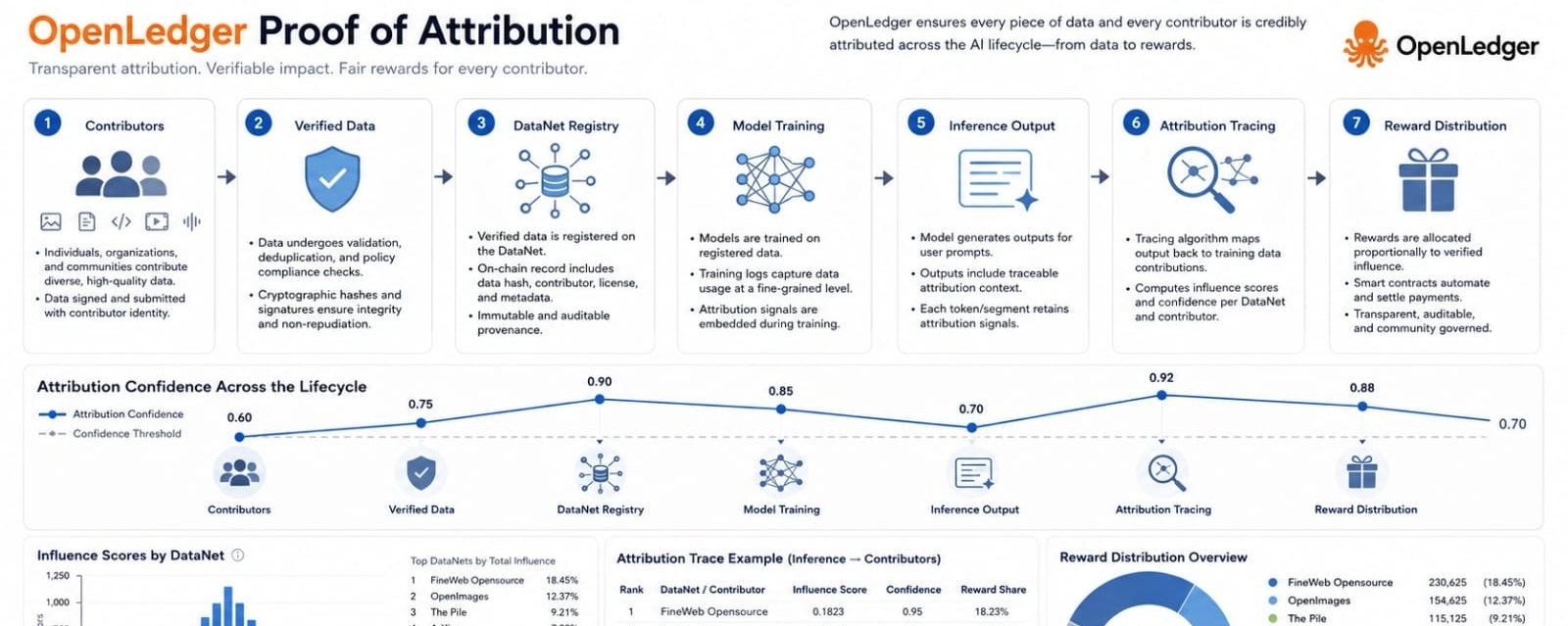
The project’s central idea is Proof of Attribution. In plain terms this means the system tries to connect model behavior back to the training data that influenced it. When a model gives an answer people increasingly want to know where the influence came from. OpenLedger’s thesis is that these questions should not sit outside the AI system as afterthoughts. They should be part of the infrastructure itself. That is a serious idea because attribution is not just about credit. It is also about confidence. When users understand why an output exists and what shaped it they can judge the system with more care.
The DataNet concept is where the idea becomes easier to understand. I find it helpful to picture a DataNet as a focused data community rather than a random database. A DataNet can be built around a specific kind of knowledge such as legal text or code examples or medical style records or question answer pairs. Contributors add data. The system records who added it and what rules or quality signals are attached. A model can then train on those DataNets and later the attribution layer can examine how much those sources shaped an output. This is where the project moves from a broad promise into a more practical design.
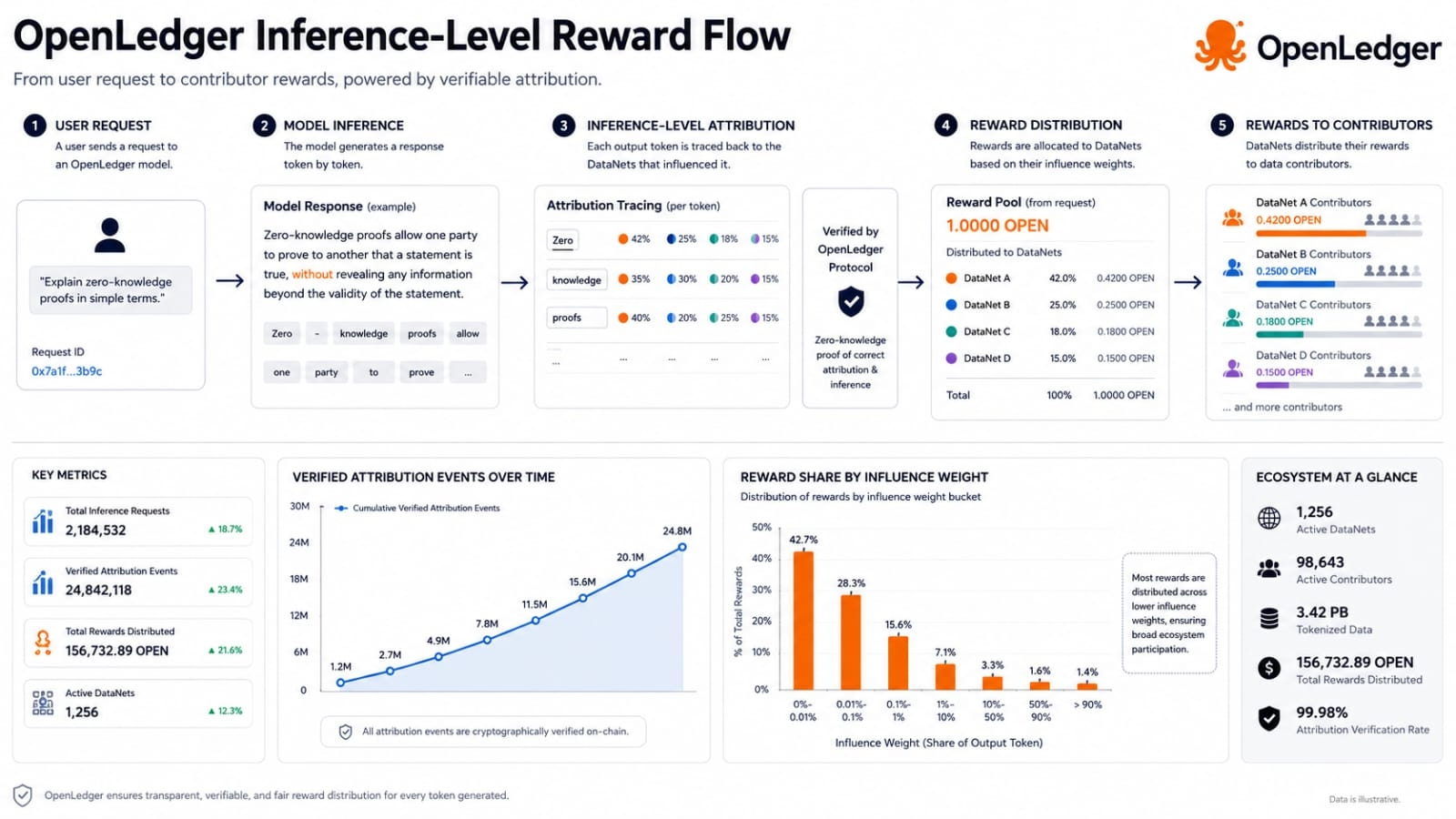
That sounds clean but the hard part is measurement. It is easy to say that data deserves credit. It is much harder to decide how much credit a specific dataset deserves for a specific answer. OpenLedger describes methods that try to estimate influence across different model situations. Smaller specialized models can use influence style approaches that examine how training data affects a result. Larger models may need token and span based tracing to connect output text back toward training material. I do not read this as a perfect answer to every attribution problem. I read it as an attempt to make the measurement problem concrete enough that rewards and audits can be built around it.
The strength of this design is that it links things that usually stay separate. It links provenance with explainability. It links explainability with rewards. It links rewards with ongoing data quality. If contributors know that useful data can keep earning recognition after it helps a model then they may have a stronger reason to contribute focused and well cleaned material. That is different from the usual pattern where data is collected once and the contributor loses visibility forever. I think this is one of the more important parts of OpenLedger because it treats data as an active asset rather than a silent input.
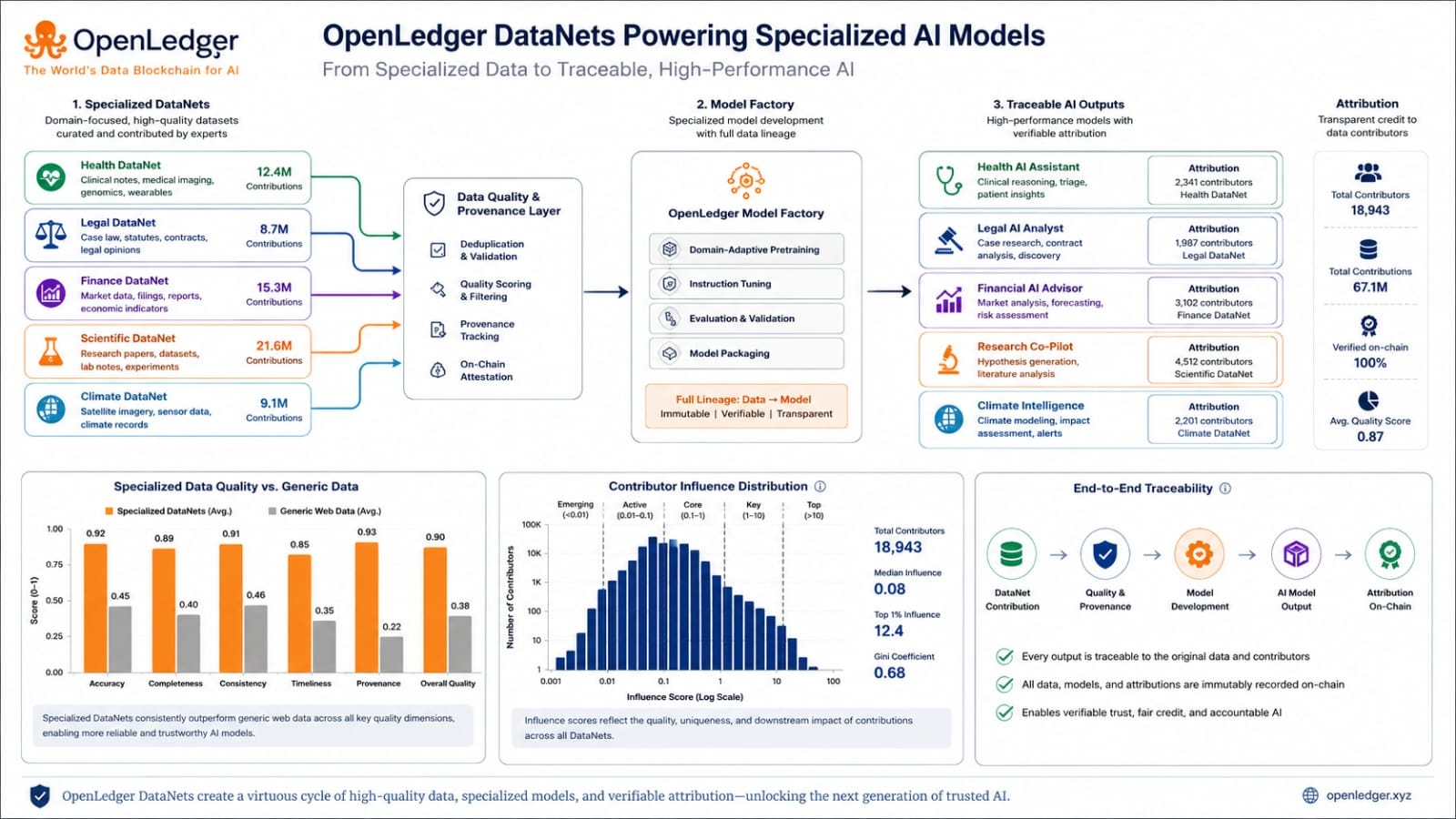
The short term appeal is clear. AI builders want better specialized data and users want more confidence in model behavior. OpenLedger offers a structure where datasets are not just stored but registered and tracked. That could matter for builders who need models in narrow domains where general internet scale data is not enough. Still I would be careful about turning the idea into a guaranteed outcome. Attribution is messy. Training data can influence models in indirect ways. Similar content can appear across many sources. A model may blend patterns rather than recall a clean source. If the reward system is too simple it could overpay obvious matches and miss deeper influence. If it is too complex users may struggle to understand it.
For market participants the practical question is not only whether the project sounds original. The practical question is whether its attribution records become useful enough to create repeat behavior. I would watch for signs that contributors keep adding higher quality data and that model builders actually choose DataNets because they improve results. I would also watch whether rewards feel understandable and whether users can verify them without trusting a claim. If the system can show real usage and real attribution then the case becomes stronger. If it depends mostly on future expectations then the market may treat it as another idea waiting for proof.
The long term question is bigger. If AI keeps moving toward more specialized agents and task specific models then the value of clean domain data may rise. In that world a system that can prove data influence could become important. It could give data communities a more serious role in the model economy. But if attribution remains too expensive or too approximate or too hard to explain then the project could remain more theoretical than practical. What matters later is not only whether OpenLedger can describe the problem well. It must show that the attribution layer can work at useful scale without making the user experience heavy.
What surprises me most is that OpenLedger’s deeper thesis is not really about paying people for uploads. That would be too shallow. The thesis is that AI value should be traceable back through the full chain of contribution. Data should not vanish once training begins. Models should not be treated as isolated objects with no visible memory of their sources. Outputs should carry enough provenance that trust and reward can be discussed with evidence. I think that is the strongest reason to take the project seriously. Not because it removes every problem but because it puts pressure on one of the least solved problems in AI. Who shaped the answer and how do we know?
@OpenLedger $OPEN #OpenLedger $PLAY
