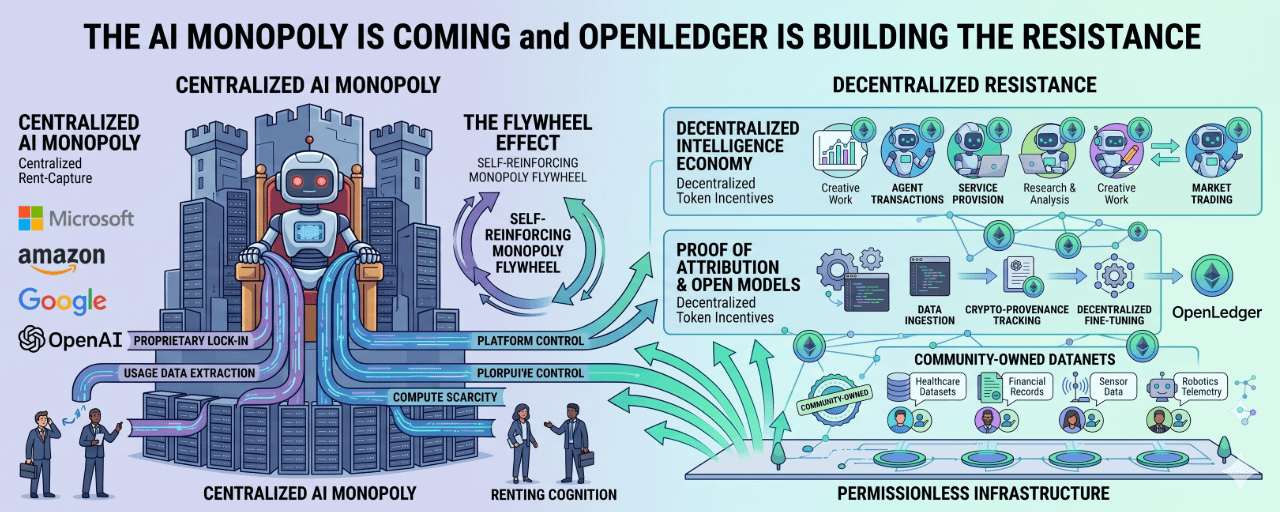

KI könnte das gleiche Konzentrationsproblem neu erschaffen, das Big Tech definiert hat, nur dass die Konsolidierung diesmal passiert, bevor die meisten Menschen überhaupt entschieden haben, was KI sein sollte.
Was mir auffiel, als ich mir die Wirtschaftlichkeit von KI ansah, war, wie vertraut mir das Muster vorkam. Wir reden ständig über Intelligenz, Modelle, Agenten und Argumentation. Aber darunter sieht das weniger nach einer Software-Geschichte aus und mehr nach einer Infrastruktur-Geschichte. Und Infrastruktur hat die Angewohnheit, sich zu zentralisieren.
Das ist wichtig, weil die langlebigsten Monopole im Internet nicht entstanden sind, weil ein Unternehmen eine leicht bessere Benutzeroberfläche hatte. Sie wurden aufgebaut, weil Skalierung sich selbst verstärkt hat. Die Suche verbesserte sich mit mehr Anfragen. Soziale Netzwerke verbesserten sich mit mehr Nutzern. Cloud-Plattformen verbesserten sich mit mehr Unternehmensabhängigkeit. KI scheint alle drei Vorteile gleichzeitig zu erben.
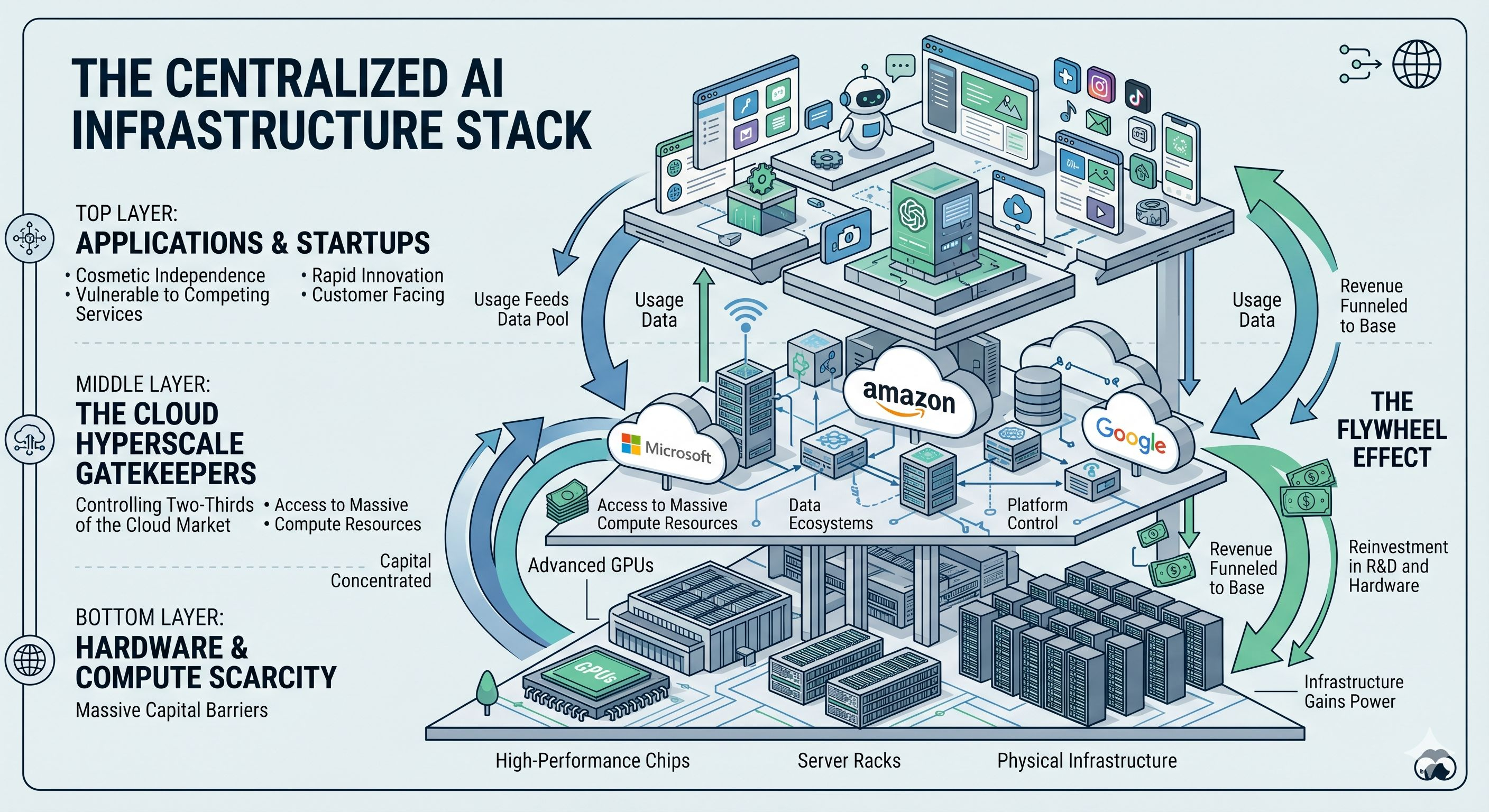
Beginnen wir mit dem offensichtlichen Problem: Rechenleistung.
Das Training von fortschrittlichen KI-Modellen ist auf einem Niveau teuer, das die Marktstruktur verändert. OpenAI hat angeblich 2025 die 10 Milliarden Dollar an wiederkehrenden jährlichen Einnahmen überschritten, was enorm klingt, bis man sich daran erinnert, dass Einnahmen nicht dasselbe sind wie Margen in der KI, wo die Kosten für Inferenz weiterhin bestrafend hoch bleiben. (TechCrunch) KI ist eine der seltenen Softwarekategorien, in denen die Bedienung jedes zusätzlichen Benutzers immer noch bedeutend teuer sein kann.
Das schafft einen leisen, aber kraftvollen Gatekeeping-Effekt. Wenn der Bau wettbewerbsfähiger Modelle den Zugang zu zehntausenden von fortschrittlichen GPUs, spezialisierten Netzwerken, Rechenzentrum-Verträgen und Ingenieurteams erfordert, die wissen, wie man all das optimiert, verengt sich die Teilnahme schnell.
Jetzt kommt die Cloud-Konzentration hinzu. Die globalen Unternehmensausgaben für Cloud erreichten im Q1 2026 129 Milliarden Dollar, wobei Amazon, Microsoft und Google etwa zwei Drittel des Marktes kontrollieren. (Data Center Dynamics) Diese Zahl ist weniger als Schlagzeile wichtig, sondern mehr für das, was sie offenbart: Die Grundlage der KI sitzt bereits auf Infrastruktur, die einer Handvoll von Firmen gehört.
Wenn wir also sagen, dass KI wettbewerbsfähig ist, weil es viele Startups gibt, sollten wir eine härtere Frage stellen. Wettbewerbsfähig auf wessen Schienen?
Ein Startup kann eine KI-Anwendung entwickeln. Es kann sogar spezialisierte Modelle trainieren. Aber wenn seine Rechenabhängigkeit über einen Hyperscaler läuft, der auch konkurrierende KI-Dienste verkauft, sieht Unabhängigkeit kosmetisch aus.
Dieser Schwung erzeugt einen weiteren Effekt: proprietären Modell-Lock-in.
Benutzer übernehmen nicht nur KI-Tools. Sie bauen Arbeitsabläufe um sie herum. Entwickler integrieren APIs. Unternehmen gestalten ihre Abläufe um das Verhalten von Modellen neu. Sobald das passiert, wird der Wechsel teuer, nicht weil die Migration technisch unmöglich ist, sondern weil sich betriebliche Gewohnheiten verfestigen.
Das haben wir bei Cloud gesehen. Das haben wir bei mobilen Ökosystemen gesehen. Das haben wir bei Suchwerbung gesehen.
KI könnte schlimmer sein, weil die Abhängigkeit kognitiv wird. Wenn der Kundenservice, die interne Forschung, die Code-Generierung, die Analyse und die Inhalts-Workflows Ihres Unternehmens alle über einen einzigen Intelligenzanbieter laufen, wird der Austausch dieses Anbieters mehr als eine Beschaffungsentscheidung. Es wird zu einer organisatorischen Operation.
Und das führt direkt zum Monopolrisiko, das die meisten Menschen unterschätzen.
Es geht nicht nur um Marktanteile. Es geht um Kontrolle über die Interpretation.
Suchmaschinen haben Informationen eingestuft. Soziale Plattformen haben Aufmerksamkeit eingestuft. KI-Systeme synthetisieren zunehmend Antworten direkt. Das ist eine andere Schicht der Macht.
Wenn eine Modellfamilie dominant wird, könnten subtile Entscheidungen über Filterung, Rangfolge, Verhaltensverweigerung, kommerzielle Priorisierung oder politische Ausrichtung beeinflussen, wie Millionen die Realität interpretieren. Nicht unbedingt durch offensichtliche Zensur. Eher durch Voreinstellungen.
Das ist schwerer zu bemerken.
Ein voreingenommener sozialer Feed zeigt immer noch mehrere Stimmen. Eine zentrale KI-Antwort präsentiert oft eine einzige synthetisierte Antwort mit Autorität, die in die Schnittstelle eingebaut ist.
Die wirtschaftliche Logik drängt in dieselbe Richtung. Größere Anbieter sammeln mehr Nutzungsdaten, mehr Unternehmensintegrationen, mehr Kapital und besseren Infrastrukturzugang. Das verbessert Produkte, zieht mehr Benutzer an und rechtfertigt noch größere Infrastrukturinvestitionen.
Klassisches Schwungrad. Schnellere Rotation.
Im Moment spiegelt das Finanzierungsumfeld diese Konzentrationslogik wider. Kapital konzentriert sich auf eine winzige Anzahl von Modellunternehmen, weil Investoren zunehmend glauben, dass Grundlagenmodelle Märkte sind, in denen der Gewinner fast alles nimmt. Selbst wenn diese Annahme übertrieben ist, beeinflusst der Glaube selbst die Ergebnisse.
Die Geschichte bietet unangenehme Parallelen.
Suche hat sich konsolidiert, weil die Relevanz mit der Skalierung verbessert wurde.
Cloud hat sich konsolidiert, weil Unternehmenskäufer Zuverlässigkeit über Fragmentierung bevorzugten.
App-Ökosysteme haben sich konsolidiert, weil Distribution wertvoller wurde als Produktdifferenzierung.
KI kombiniert alle drei Mechanismen und fügt Rechenknappheit hinzu.
Diese Kombination ist ungewöhnlich mächtig.
Jetzt sind die Unterstützer der Zentralisierung nicht ganz im Unrecht.
Es gibt einen praktischen Fall für Konzentration.
Das Training fortschrittlicher Modelle erfordert außergewöhnliche Koordination. Die Sicherheitsbewertung ist ressourcenintensiv. Die Infrastrukturinvestitionen sind massiv. Die Governance in verteilten Systemen kann langsam, chaotisch und anfällig für die Erfassung einer anderen Art sein.
Ein zentrales KI-Unternehmen kann oft schneller agieren, Anreize klar ausrichten und kohärente Upgrades ohne endlosen Konsensfriktionen bereitstellen.
Das ist ein echter Vorteil.
Aber Geschwindigkeit ist nicht neutral, wenn das langfristige Ergebnis strukturelle Abhängigkeit ist.
Hier werden dezentrale KI-Projekte wie @OpenLedger interessant, nicht weil sie das Problem bereits gelöst haben, sondern weil sie die richtige Schicht angreifen.
Das übliche dezentrale KI-Pitch konzentriert sich auf Offenheit. Das ist nicht genug.
Das stärkere Argument ist die wirtschaftliche Architektur.
Wenn die KI-Infrastruktur erlaubnisfrei wird, erweitert sich die Teilnahme. Wenn Beitragsmodelle, Datenbeiträge, Validierung oder Inferenzbereitstellung mit ausgerichteten Anreizen verteilt werden können, verschiebt sich das Eigentum weg von einem kleinen Unternehmenszentrum.
Das verändert die Textur des Systems.
Anstatt dass ein paar Firmen Werte aus geschlossenen Ökosystemen extrahieren, wird das Netzwerk selbst zum wirtschaftlichen Akteur.
Das ist zumindest die Theorie.
Der Reiz von OpenLedger liegt in dieser Möglichkeit: verteilte Anreize anstelle von zentralisierter Mietabschöpfung, Ökosystembesitz anstelle von Plattformabhängigkeit, Teilnahme anstelle von Genehmigung.
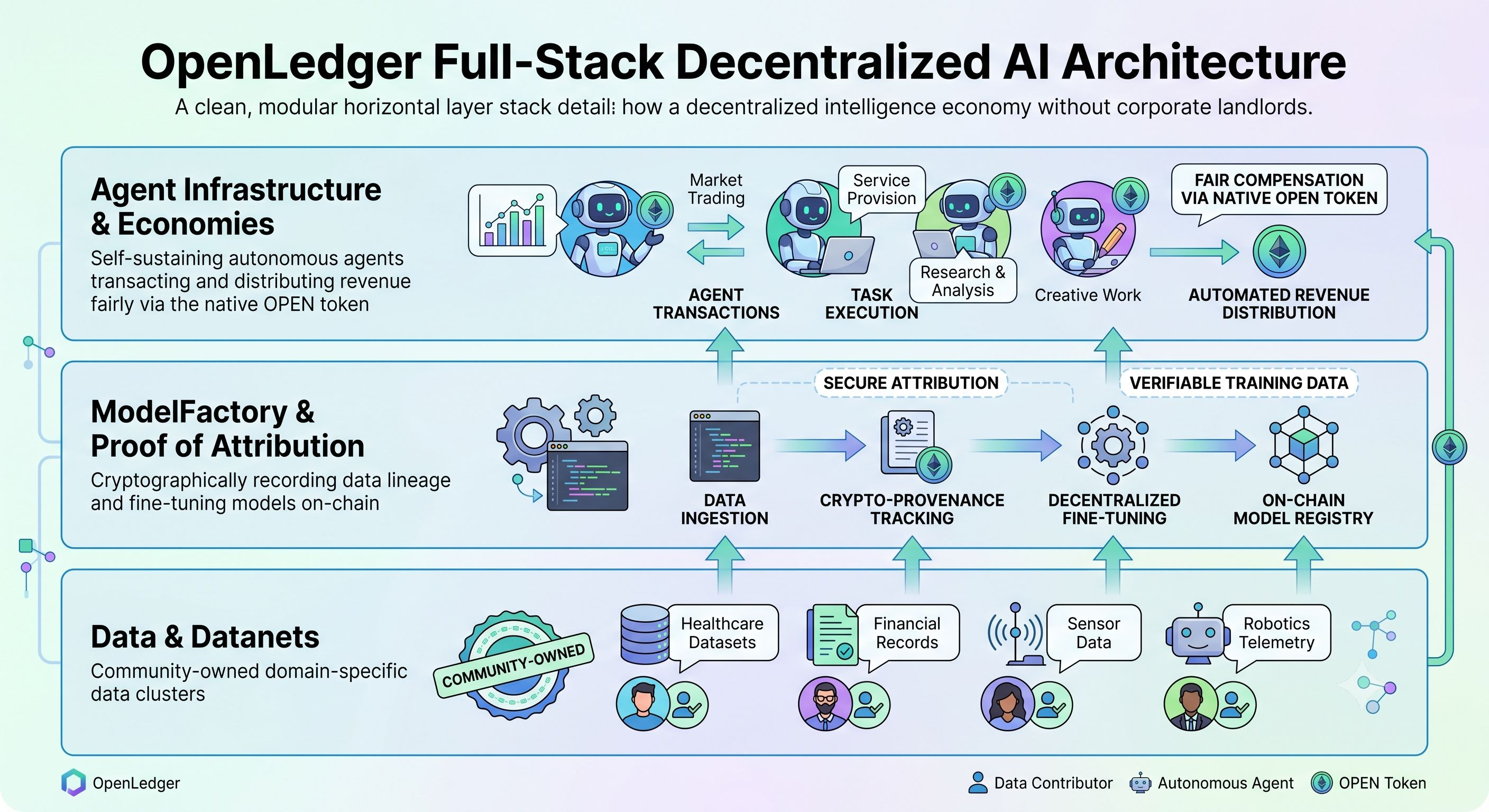
Aber die harten Fragen bleiben.
Kann dezentrale KI tatsächlich in der Leistung konkurrieren?
Kann verteilte Governance schnell genug agieren, wenn die Iterationszyklen der Modelle in Wochen gemessen werden?
Können fragmentierte Mitwirkende Sicherheitsstandards koordinieren?
Kann wirtschaftliche Effizienz mit Hyperscalern mithalten, die bereits in erstaunlichem Maßstab operieren?
Diese sind keine triviale Einwände.
Dezentralisierung klingt oft überzeugend, bis die Ausführung beginnt.
Verteilte Systeme opfern häufig Geschwindigkeit für Fairness. Governance kann performativ werden. Anreizmodelle können Spekulation anziehen, anstatt dauerhafte Bauherren zu gewinnen. Infrastrukturkoordination ist schwieriger, als es die Ideologie erscheinen lässt.
Und dennoch würde eine zu schnelle Abwertung der Dezentralisierung den tieferen Punkt verfehlen.
Das Internet zentralisiert sich immer wieder, weil Bequemlichkeit kurzfristig gewinnt.
Benutzer wählen Geschwindigkeit über Struktur.
Entwickler wählen Einfachheit über Souveränität.
Unternehmen wählen Zuverlässigkeit über Optionen.
Dann erkennen Jahre später alle, dass Abhängigkeiten Kosten haben.
KI könnte diesen Zeitrahmen dramatisch komprimieren.
Denn im Gegensatz zu früheren Internet-Schichten organisiert KI nicht nur Informationen oder ermöglicht Kommunikation. Es wird zu einem Vermittler für das Denken selbst.
Das ist eine andere Kategorie von Hebel.
Wenn die aktuellen Trends anhalten, könnten die größten KI-Unternehmen nicht wie Softwareanbieter aussehen. Sie könnten mehr wie private Intelligenz-Dienstleister aussehen.
Und Versorgungsunternehmen sind, einmal verankert, notorisch schwer zu verdrängen.
Die echte Frage ist also nicht, ob zentrale KI beeindruckende Produkte hervorbringt. Das hat sie bereits.
Die eigentliche Frage ist, ob wir einen Markt aufbauen, in dem Intelligenz etwas ist, das von wenigen Unternehmensvermietern gemietet wird.
Wenn OpenLedger oder ähnliche dezentrale Ansätze erfolgreich sind, werden sie nicht gewinnen, weil Dezentralisierung philosophisch sauberer klingt. Sie werden gewinnen, weil zu viel Konzentration letztendlich nach Alternativen verlangt.
Dieses Muster hat sich seit Jahrzehnten in der Technologie wiederholt.
Dennoch spielt das Timing eine Rolle. Alternativen müssen lebensfähig werden, bevor die Abhängigkeit verhärtet.
Denn sobald KI die unsichtbare Schicht unter Arbeit, Forschung, Software, Finanzen und Kommunikation wird, sieht das Monopol nicht mehr wie eine Marktbedingung aus, sondern wie eine infrastrukturelle Realität.
Und Infrastrukturmonopole werden selten nur durch bessere Ideen gebrochen.
Sie sind zerbrochen, bevor sie zu Fundamenten werden.
@OpenLedger $OPEN #OpenLedger